Clear Sky Science · en
Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction
Why this matters for patient privacy
Hospitals sit on huge collections of medical notes that could improve care and research, but these records are full of sensitive details such as names, addresses, and dates. Powerful cloud-based AI systems are very good at hiding this information, yet many hospitals are not allowed to send raw patient data to outside servers. This study shows that with careful tuning, smaller AI models running entirely inside the hospital can come surprisingly close to the performance of top cloud systems—offering a way to use AI while keeping patient data safely on site.
The privacy-versus-progress dilemma
Modern large language models can reliably spot and remove protected health information (PHI) from medical text, often exceeding 90 percent accuracy. However, sending unedited patient notes to cloud services raises legal and ethical concerns under regulations like HIPAA, GDPR, and Japan’s APPI. Many institutions insist on full “data sovereignty,” meaning information never leaves their own computers. Until now, local models that can run on in‑house hardware have typically missed far more identifiers, forcing hospitals into a trade-off: strong analytics in the cloud or stricter privacy with weaker tools. The authors set out to see whether this gap could be closed enough for real-world clinical use.
A staged game plan for smarter local AI
The team designed a five-step optimization framework to steadily improve the performance of local language models on PHI removal in Japanese radiology reports. They started with 14 different models of various sizes, all running on an isolated, internet‑free computer meant to mimic hospital security. Using 160 carefully crafted synthetic reports—realistic but entirely fictional—they measured how well each model found and separated eight types of identifiers, from names and ID numbers to dates and departments. After an initial baseline test, they created more helpful general prompts, then tailored instructions to each model’s quirks, added an automated “self-check and fix” loop, and finally tested the best candidates on a reserved set of reports. 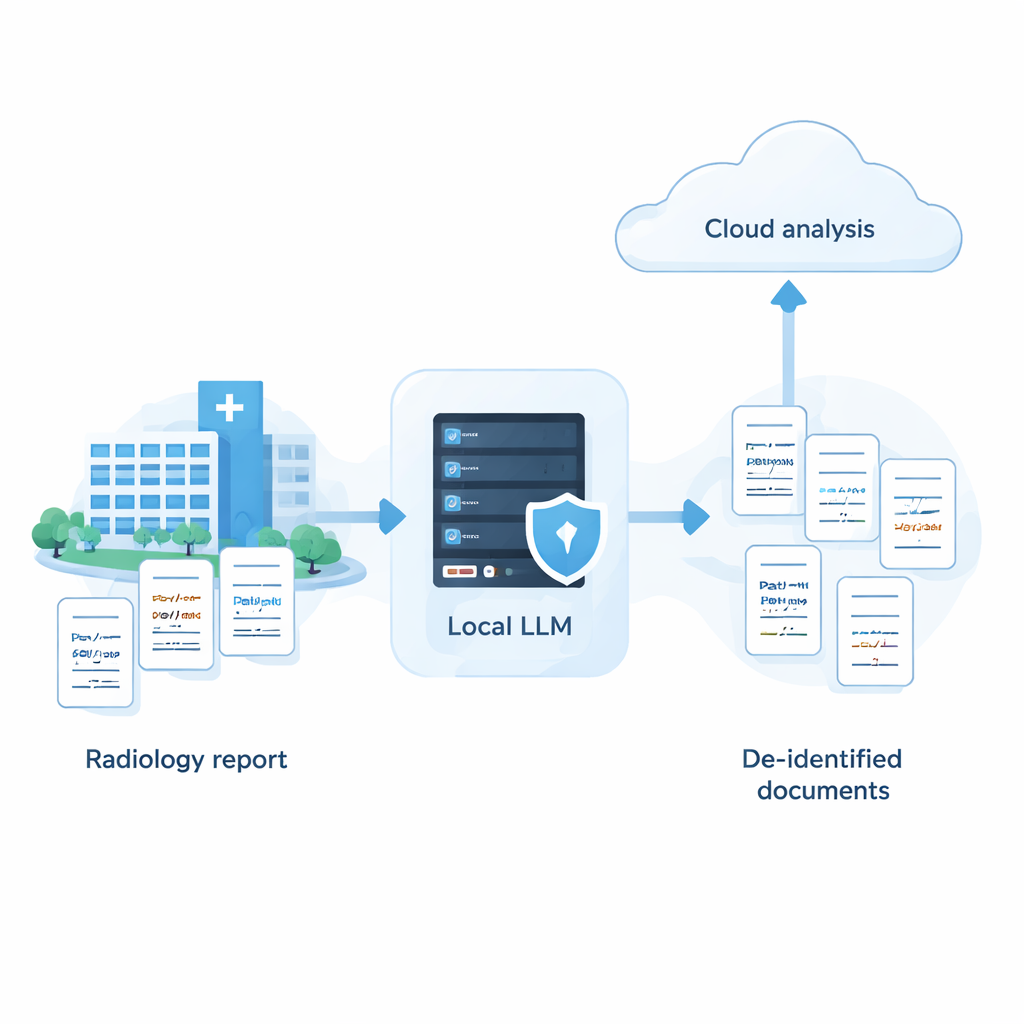
Closing in on cloud-level performance
Through this staged process, the researchers discovered that raw model size was not the key to success; some very large systems still performed poorly. Instead, the most promising models were those that responded well to careful instruction design and error analysis. One mid‑sized system, Mistral-Small-3.2, became the clear winner after custom prompts and a self-refinement step where the model reviewed and selectively corrected its own output. On the final 60 test cases, this optimized local setup scored 91.54 out of 100—about 97.8 percent of the leading cloud model’s 93.56 points—while obeying formatting rules perfectly. In practical terms, its remaining shortfall was judged clinically minor. The main cost was speed: local processing took around 25 seconds per typical report, compared with under 2 seconds in the cloud, but this was considered acceptable for routine, non‑emergency batch work. 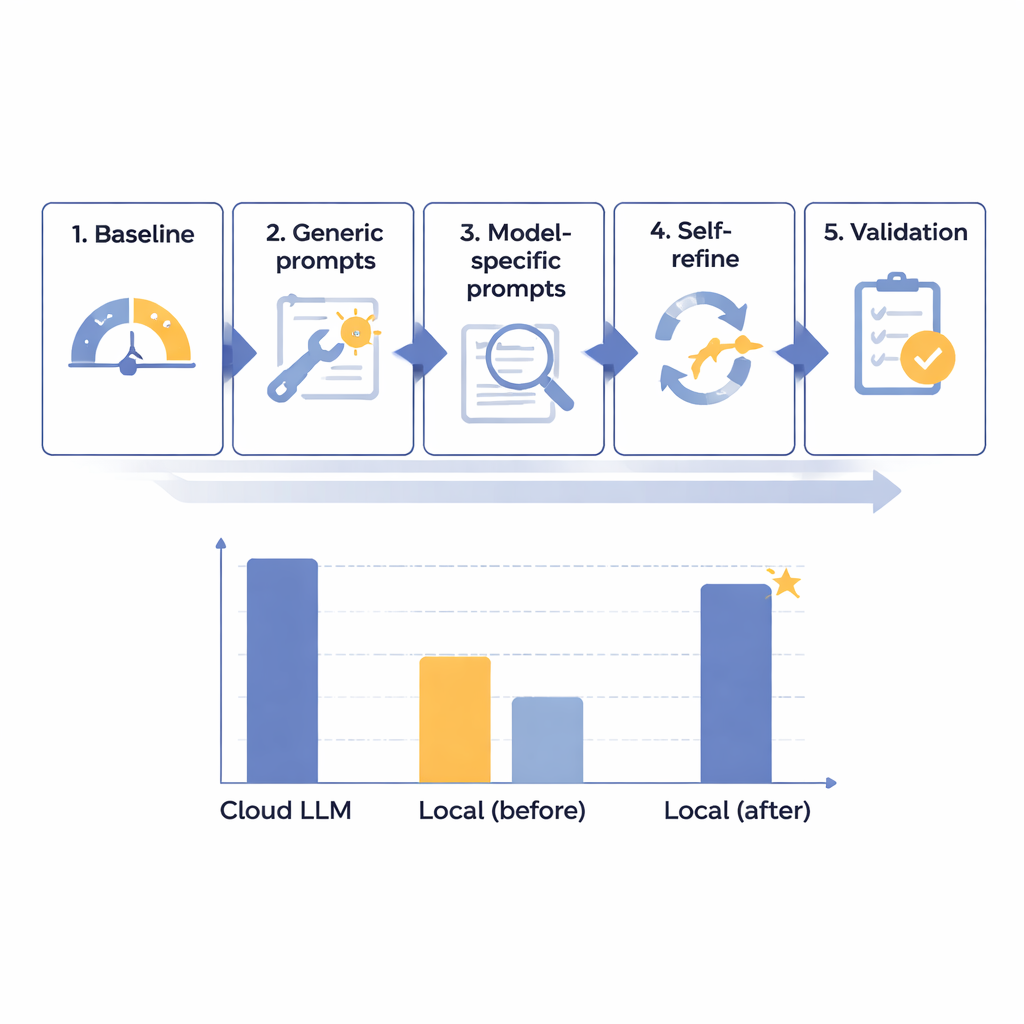
A surprising threshold for self-correction
One of the most intriguing findings was a kind of tipping point around 87–88 points on the authors’ 100‑point scale. Models scoring below this level at baseline—like Mistral-Small-3.2—benefited greatly from the self-refinement loop, gaining nearly seven points by fixing a small fraction of their own mistakes. Models that already started above this threshold showed almost no improvement, and sometimes wasted effort trying to “fix” correct answers. This suggests that advanced optimization tools should be reserved for models that are good but not yet excellent, offering hospitals a way to focus computing power and staff time where it pays off most. The authors caution that this threshold is based on just two models and needs confirmation, but it offers an early rule of thumb for deployment planning.
What this means for hospitals and patients
The study argues that hospitals do not have to choose between strong privacy and strong AI. With a systematic approach—screening many models, tuning prompts to their strengths and weaknesses, and adding an intelligent self-review step—it is possible for a fully local system to approach the accuracy of top cloud services for removing sensitive information from medical text. In practice, this opens the door to a hybrid strategy: PHI is stripped out safely on hospital-owned machines, and only anonymized reports, with names and other identifiers removed, are sent to the cloud for more advanced analysis. While the work so far is based on synthetic Japanese radiology reports and must be tested on real-world data and other languages, it offers an actionable roadmap for institutions that want to harness AI while keeping patient trust and privacy at the center.
Citation: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Keywords: medical de-identification, patient privacy, local language models, healthcare AI, radiology reports