Clear Sky Science · en
Evaluation of three artificial intelligence chatbots for generating clinical hematology multiple choice questions for medical students
Smarter Test Questions for Tomorrow’s Doctors
Multiple-choice tests may not sound exciting, but they quietly shape the skills of future doctors. Each question on an exam can steer how students think about real patients. This study asks a timely question: can modern artificial intelligence chatbots help busy medical teachers write good exam questions in blood diseases faster, without sacrificing quality or safety?
How AI Helped Build Exam Questions
The researchers focused on three widely used AI chatbots, all designed to generate text. They asked each system to write 50 multiple-choice questions in hematology, the field that studies blood disorders such as anemia and leukemia. The questions had to cover five common topics that appear in medical exams and real clinics: pancytopenia (low counts of all blood cells), anemia, thrombocytopenia (low platelets), and two groups of blood cancers called myelo- and lymphoproliferative syndromes. In total, the chatbots created 150 questions in less than half a minute per system—an enormous time savings compared with writing them by hand. 
Putting AI-Written Questions Under the Microscope
Speed alone is meaningless if the questions are wrong, confusing, or unfair. To check quality, three experienced hematology teachers—who did not know which chatbot wrote which question—scored every item using a detailed checklist. They rated scientific accuracy, clinical relevance, clarity of wording, realism of the wrong answer choices, and overall quality on a five-point scale. They also judged whether each question had the right level of difficulty for medical students and whether it could distinguish strong students from weaker ones. Questions that reached at least 15 out of 25 points were considered acceptable for use, others needed revision or rejection.
Which Chatbot Did Best?
All three systems produced mostly solid questions, but one model stood out. Across the expert ratings, this chatbot scored highest for accuracy, clinical relevance, and believable wrong answers. Every one of its 50 questions met the acceptance threshold, and none needed changes. The other two models still performed well: more than nine out of ten of their questions were good enough but required minor touch-ups, often because an incorrect option was too obviously wrong or a detail could be clearer. Overall, the experts agreed that all three tools can quickly generate exam material that is very close to ready for classroom use. 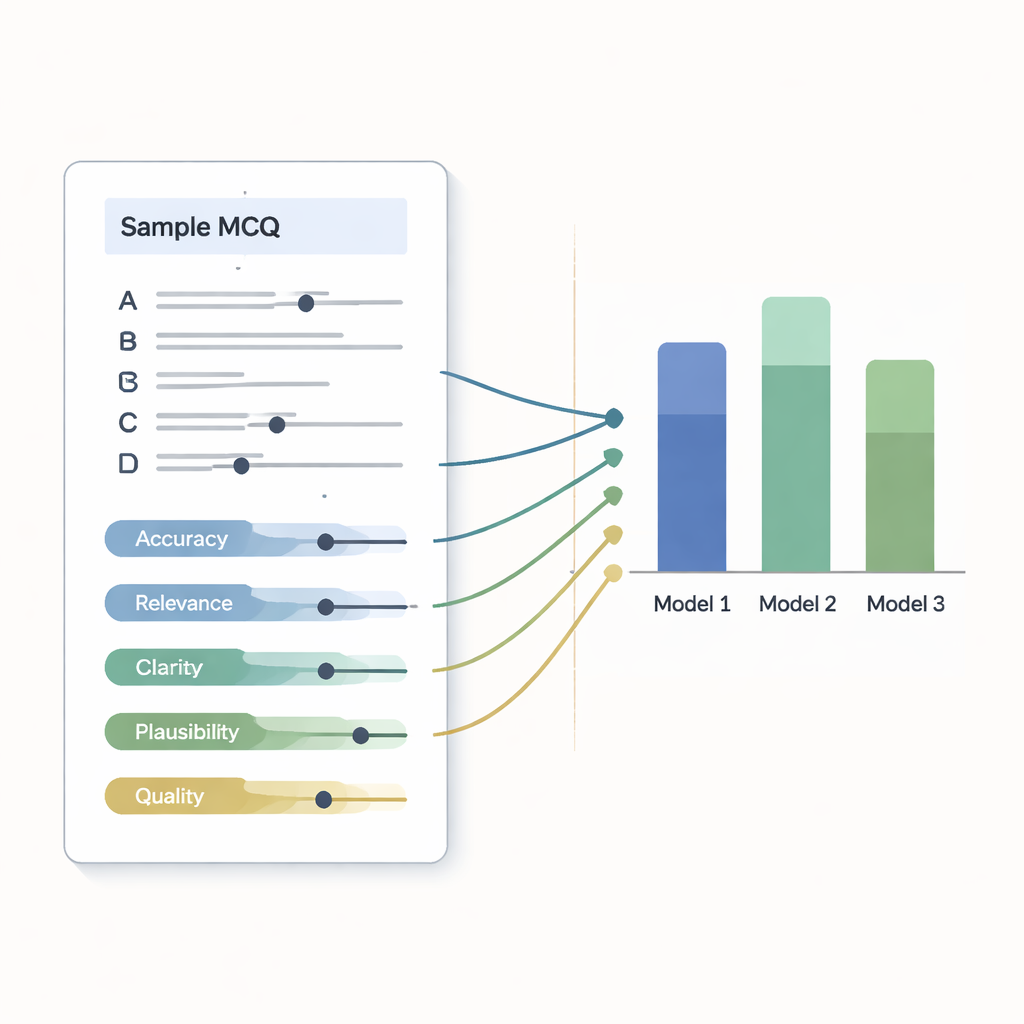
Thinking Skills, Not Just Memorization
The team also asked what kind of thinking these AI-written questions demanded from students. Using Bloom’s taxonomy—a framework educators use to classify mental skills—they grouped questions into simple knowledge and comprehension versus higher-order skills like applying facts, analyzing situations, and evaluating options. Surprisingly, the chatbots produced mostly higher-order questions. For one model, over 90% of the items required students to reason through clinical scenarios rather than just recall facts. Basic recall questions were relatively rare across all three systems. This pattern suggests that large language models, trained on vast amounts of connected text, naturally lean toward context-rich, problem-solving scenarios instead of simple flashcard-style prompts.
Promise, Limits, and the Need for Human Partners
Despite these strengths, the study uncovered important gaps. None of the chatbots spontaneously proposed image-based questions, which are crucial in blood diseases where doctors must interpret microscope slides and lab graphics. When directly asked for image-based items, two systems admitted they could not provide them, and one produced a low-quality attempt. The study also relied on expert opinion rather than real exam data from students, so it cannot fully prove how well these questions would perform in live testing. The authors stress that teachers still need to check facts, refine wording, and ensure that key basic concepts are adequately covered.
What This Means for Future Medical Training
For the lay reader, the bottom line is that AI is not replacing medical teachers, but it is becoming a powerful assistant. In this study, chatbots rapidly generated mostly accurate, clinically realistic questions that help students practice decision-making in blood disorders. One model in particular produced questions of such high quality that experts would use them with little or no change. Still, the machines overlooked simpler knowledge checks and could not handle visual material on their own. The authors conclude that the best approach is a partnership: AI does the heavy lifting of drafting varied questions, while human experts guide the prompts, fill in missing basics, verify the content, and keep pace with changing medical guidelines.
Citation: Boufrikha, W., Sallem, A., Laabidi, B. et al. Evaluation of three artificial intelligence chatbots for generating clinical hematology multiple choice questions for medical students. Sci Rep 16, 5802 (2026). https://doi.org/10.1038/s41598-026-36839-x
Keywords: medical education, artificial intelligence, hematology, multiple choice questions, chatbots