Clear Sky Science · en
Diagnosis and grading of steatotic liver disease via clinical and laboratory data using machine learning
Why Fatty Liver Disease Matters to Everyday People
Fatty liver disease has quietly become one of the most common long-term liver problems in the world, affecting roughly a third of adults and even many people who feel perfectly healthy. If too much fat builds up in the liver and is not caught early, it can slowly progress to scarring, liver failure, and even liver cancer. Yet the best tests we have today are either invasive, like a needle biopsy, or rely on costly scanners that many clinics do not have. This study explores whether simple, routine blood tests and body measurements, combined with modern computer techniques, can offer an easier way to spot who has fatty liver disease and how advanced it is.
A Silent Disease That Can Turn Serious
Steatotic liver disease, often called fatty liver, starts when fat accumulates inside liver cells. At first, this build-up (simple steatosis) may cause no symptoms and is often discovered by chance. Over time, however, fat can trigger inflammation and damage in the liver, leading to scarring (fibrosis), hardening of the tissue, and in the worst cases, cirrhosis and liver failure. Because the early stages are silent but reversible, catching the disease before severe scarring develops is crucial. The problem is that many widely used tools for grading liver damage—such as special ultrasound machines and blood-based scoring systems—are either too expensive, not widely available, or less reliable in people with obesity, who are among those at highest risk.
Turning Routine Checkups into a Liver Health Test
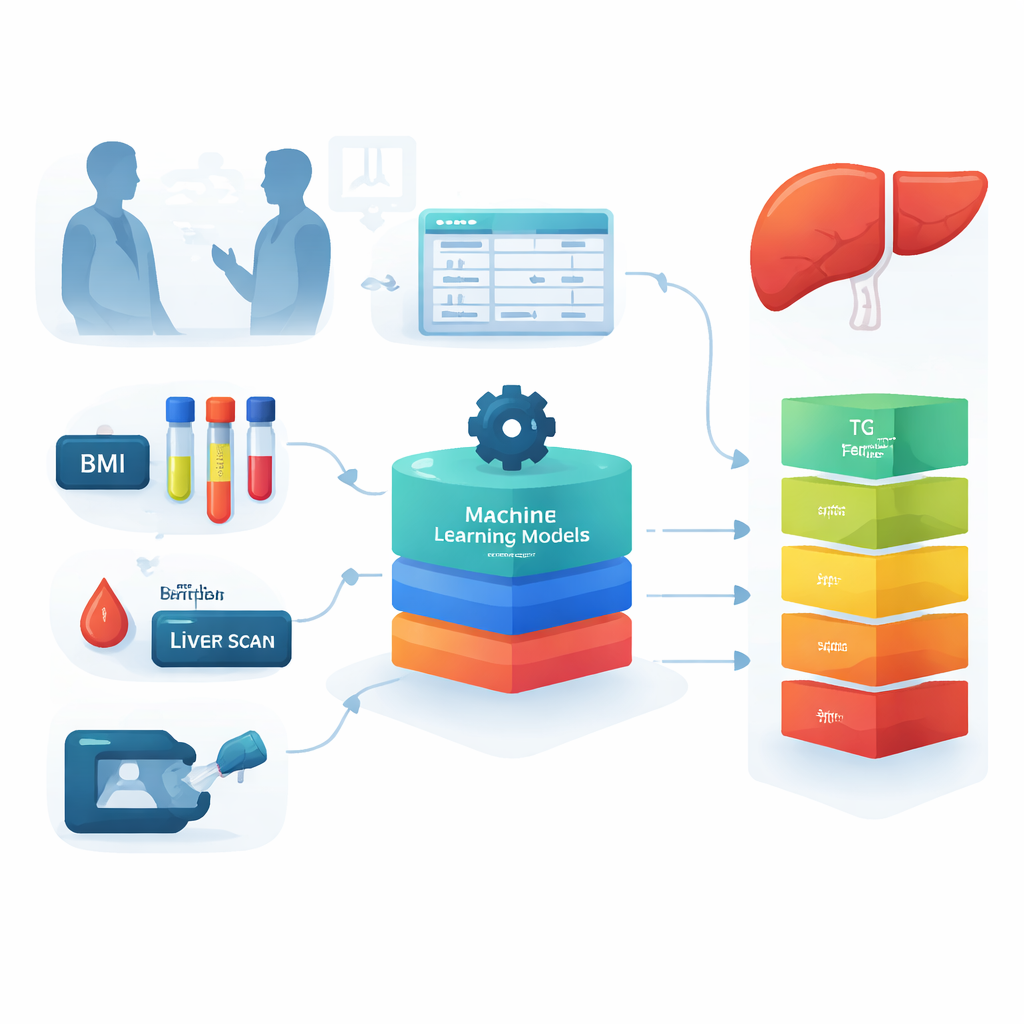
The researchers asked whether everyday clinical information could be turned into a powerful screening tool. They drew on records from 210 adults visiting a digestive disease clinic in Tehran, Iran. For each person, they collected basic measurements like height and weight, and standard blood tests such as cholesterol, triglycerides, fasting blood glucose, liver enzymes, and iron-related markers. The severity of fat build-up and scarring in the liver had already been measured with a specialized device called FibroScan, which allowed the team to sort participants into five groups: from healthy livers, through mild, moderate, and severe fat accumulation, to those with advanced scarring. These groups served as the “ground truth” for training and testing the computer models.
Boosting the Data and Training the Machines
Because 210 patients is a relatively small number for machine learning, the team created additional “synthetic” patient records by adding carefully controlled random variation to the real data. They checked that these simulated records still followed the same overall patterns as the original set, and expanded the dataset to 1,500 samples. They then tested eight different machine learning approaches, including decision trees, random forests, support vector machines, and neural networks, along with combinations of these methods. Each model was asked to predict which of the five liver health groups a person belonged to, based only on the clinical and laboratory data. Performance was judged not only by overall accuracy, but also by how rarely the model mistakenly labeled a sick person as healthy, a critical concern for any screening tool.
Finding the Few Numbers That Matter Most
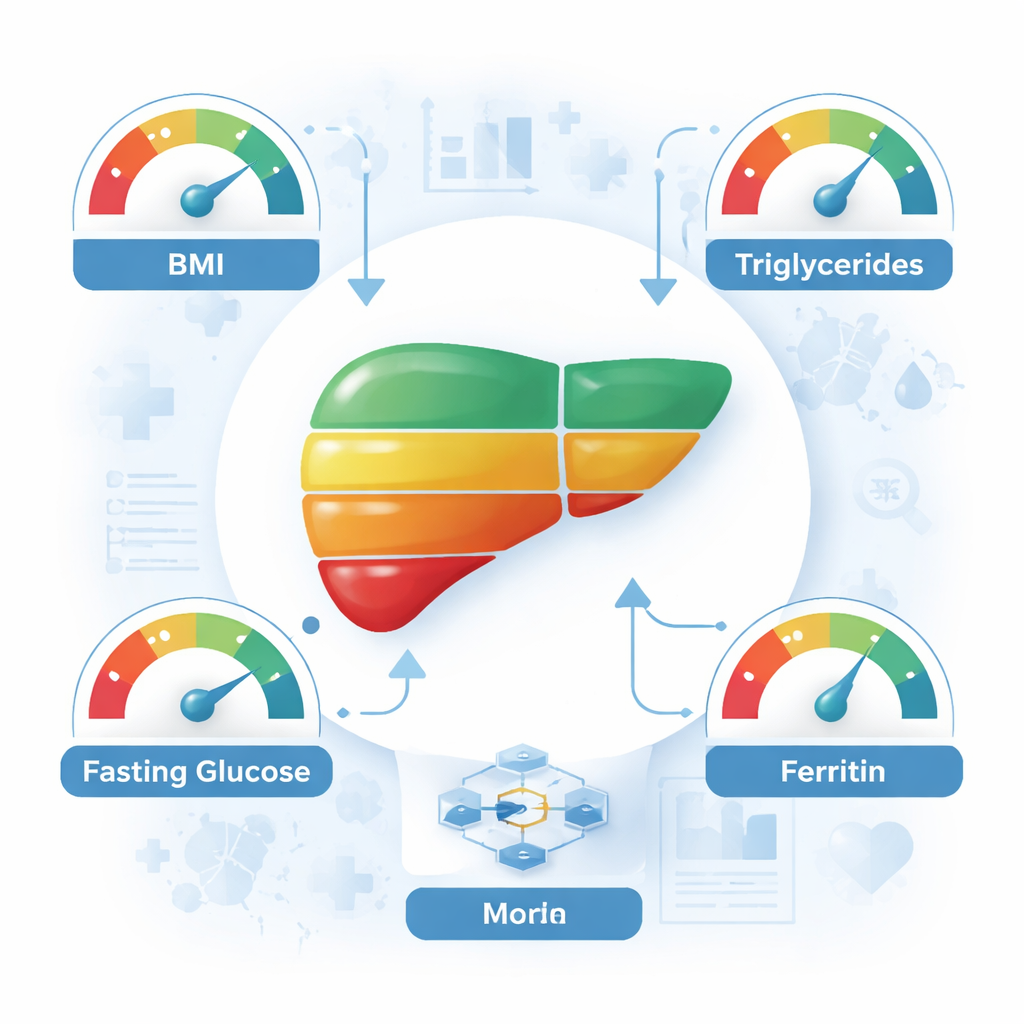
Some of the models, especially a hybrid combining support vector machines with a boosting method (SVM–XGBoost), achieved around 93% accuracy when using all 26 available features. To make the tool simpler and easier to use, the researchers next examined which measurements contributed most to the predictions. Statistical techniques first highlighted eight particularly important features, including body mass index (BMI), triglycerides, fasting blood glucose, ferritin (an iron-storage protein), platelets, alkaline phosphatase, creatinine, and a blood clotting measure. Liver specialists then reviewed these results and selected four measures that were both strongly tied to disease biology and practical in everyday care: BMI, triglycerides, fasting blood glucose, and ferritin. Remarkably, when models were retrained using only these four inputs, they still correctly classified patients about 70% of the time, and up to 76% with the best method.
What This Means for Patients and Clinics
For a layperson, the main message is that a handful of routine numbers from a standard checkup—weight and height for BMI, along with simple blood tests for fats, sugar, and iron stores—can give a surprisingly detailed picture of liver health when interpreted by well-designed computer models. While these tools do not replace expert medical judgment or specialized imaging when it is available, they offer a promising way to identify people at risk, especially in clinics with limited resources and in regions where fatty liver disease is common. Earlier detection can prompt lifestyle changes, such as weight loss, healthier eating, and more physical activity, which are known to improve liver health. This study suggests that, in the near future, your regular lab results may double as an early warning system for a silent but serious disease.
Citation: Sadeghi, B., Zarrinbal, M., Poustchi, H. et al. Diagnosis and grading of steatotic liver disease via clinical and laboratory data using machine learning. Sci Rep 16, 6866 (2026). https://doi.org/10.1038/s41598-026-36834-2
Keywords: fatty liver disease, machine learning, blood tests, BMI and triglycerides, noninvasive diagnosis