Clear Sky Science · en
Taxonomical modeling and classification in space hardware failure reporting
Finding Patterns in Spaceflight Glitches
Every mission to space relies on countless pieces of hardware working flawlessly, from bolts and cables to life-support systems. When something goes wrong, engineers file detailed discrepancy reports, but NASA now has more than 54,000 of these records—far too many for people to read one by one. This study shows how modern language and machine-learning tools can turn that mountain of text into organized knowledge, helping engineers spot patterns in failures, improve designs, and keep astronauts safer.
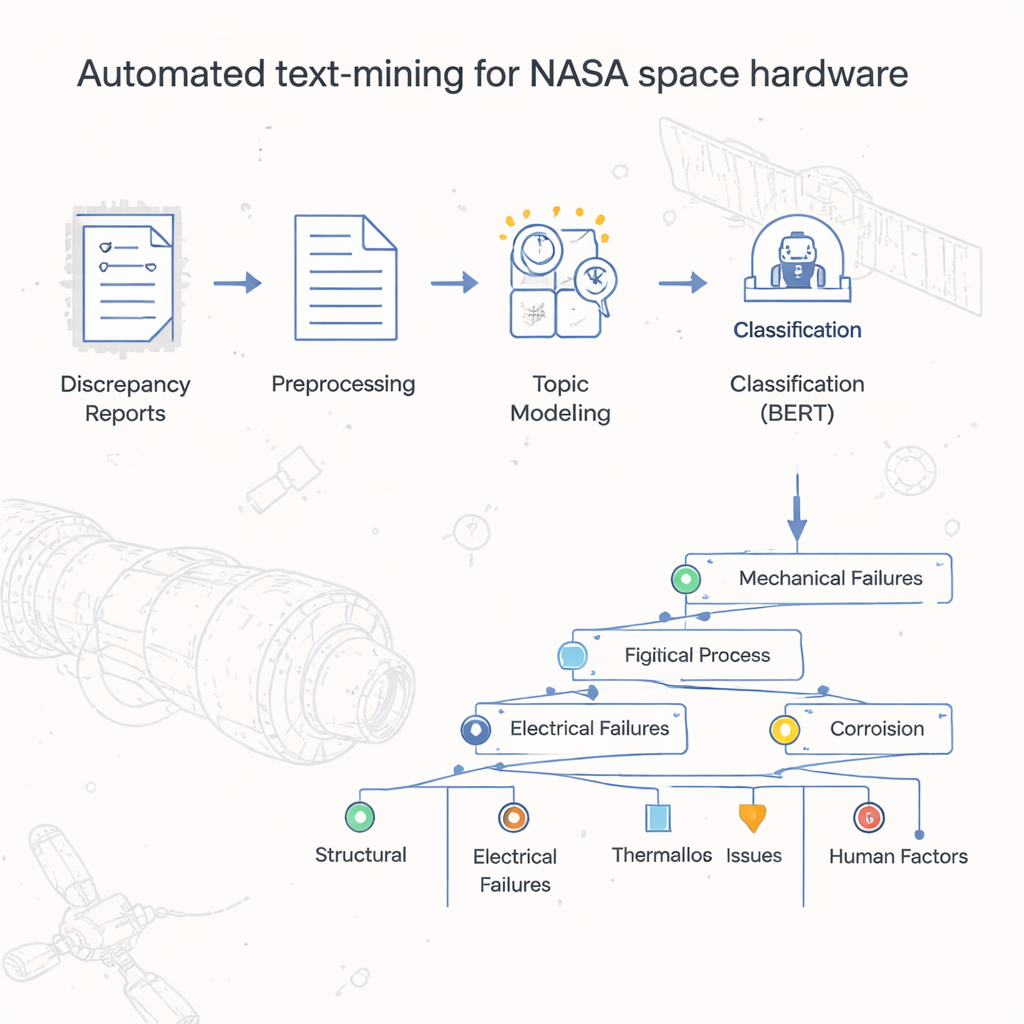
From Piles of Reports to Organized Insight
For decades, NASA’s Johnson Space Center stored hardware failure and discrepancy reports as digital documents, much like scanned versions of old paper forms. Basic spreadsheet tallies revealed which official defect codes appeared most often, but the real story—the specific causes, steps, and conditions that led to problems—was buried in free-form text fields. Reading and categorizing more than 54,000 records by hand would be prohibitively time-consuming. The authors set out to build an automated way to classify and group these reports, creating a kind of “map” or taxonomy that captures how space hardware actually fails in day-to-day practice.
Teaching Computers to Read Engineering Language
The team first cleaned the text in each report so that computers could work with it effectively. They removed stray symbols and digits that added noise, broke sentences into individual words, and converted them to a simpler base form (for example, turning “leaked” and “leaking” into “leak”). Common words that carry little meaning, like “the” or “and,” were filtered out. Once the text was standardized, the researchers converted it into numbers that machine-learning algorithms can handle, using established techniques that capture how often words appear and how strongly they characterize a document. This groundwork allowed them to apply powerful tools originally developed for general language tasks to the highly specialized world of space hardware reports.
Building a Tree of Failure Types
At the heart of the project is a two-step model the authors call LDA-BERT. The first step, Latent Dirichlet Allocation (LDA), automatically discovers themes—called topics—by looking for patterns of words that tend to appear together across thousands of reports. A single report can mix several topics, mirroring real life where one hardware problem can have multiple contributing issues. The second step uses BERT, a modern language model, to check and refine how well these topics separate the reports. By treating the LDA topics as provisional labels and training BERT to predict them, the researchers could identify the number and combination of topics that gave stable, accurate classifications. They then further divided each topic into subtopics, using clustering and statistical checks, to construct a branching taxonomy that organizes failure reports from broad defect codes down to detailed process-level labels.
Turning Taxonomies into Actionable Trends
Once the taxonomy was in place, the team visualized it with dashboards and interactive tools. Each branch and sub-branch of the tree could be linked to other information in the reports: when an issue was first noted, how long it took to close out, which organization was responsible, and what final decision was made. Time-series plots showed whether certain types of problems—such as inspection oversights or tolerance-data issues—were becoming more or less common over the years. Word maps provided a quick feel for the language used in each cluster without reading every report. These views help managers focus on high-trending and high-impact process failures, guiding training, procedure changes, or design updates where they will matter most.
Limits of Automatic Root-Cause Hunting
The researchers also explored tools that try to go beyond labeling and trend-spotting to infer direct cause-and-effect relationships from text. They tested systems like INDRA-Eidos and custom rule sets built with the spaCy language library. While these tools could extract some cause-and-effect pairs and visualize them as interactive networks, many of the suggested links were too vague or confusing to be useful. In practice, the models struggled because the original reports often did not spell out root causes clearly; engineers implied them or left them for later investigation. The study concludes that reliably automating root-cause discovery would require both richer data entry—such as explicit fields for likely cause—and more costly, highly tailored model training than is justified for this one-off analysis.
Why This Matters for Future Missions
By turning a large, unstructured archive of failure reports into a clear, layered taxonomy, this work gives NASA a practical way to monitor how and why hardware problems arise over time. Even though the methods cannot yet replace human judgment for deep root-cause analysis, they excel at scanning vast amounts of text to highlight where issues are clustering and what kinds of processes tend to be involved. That kind of early warning and structured insight can help engineering teams target their attention, refine procedures, and design more robust systems—concrete steps toward safer, more reliable missions to the Moon, Mars, and beyond.
Citation: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Keywords: space hardware failures, natural language processing, topic modeling, engineering risk analysis, NASA discrepancy reports