Clear Sky Science · en
Collaborative representation and confidence-driven semi-supervised learning for hyperspectral image classification
Sharper Eyes on Earth’s Hidden Colors
From tracking crop health to monitoring wetlands, scientists increasingly rely on hyperspectral images—detailed pictures that capture dozens or even hundreds of colors our eyes cannot see. These rich data promise more accurate maps of land use and vegetation, but they are notoriously hard to analyze. This study introduces a new method, called GCN-ARE, that makes sense of these complex images more reliably and efficiently, paving the way for better environmental monitoring, smarter agriculture, and improved urban planning.
Why Hyperspectral Images Are So Tricky
Unlike a regular photo, a hyperspectral image records a full color spectrum for every pixel. That lets scientists distinguish, for example, healthy grass from stressed grass, or different crop types that look almost identical in ordinary imagery. But this richness creates challenges. Neighboring areas can mix many land types, classes are often imbalanced (some land covers are rare), and terrain can be irregular—think patchy vegetation or tangled city blocks. Traditional machine learning depends on hand‑crafted features and often misses subtle patterns, while modern deep networks like convolutional neural networks and Transformers can struggle with irregular shapes and require heavy computing power. As a result, models that work well on one scene may fail on another.
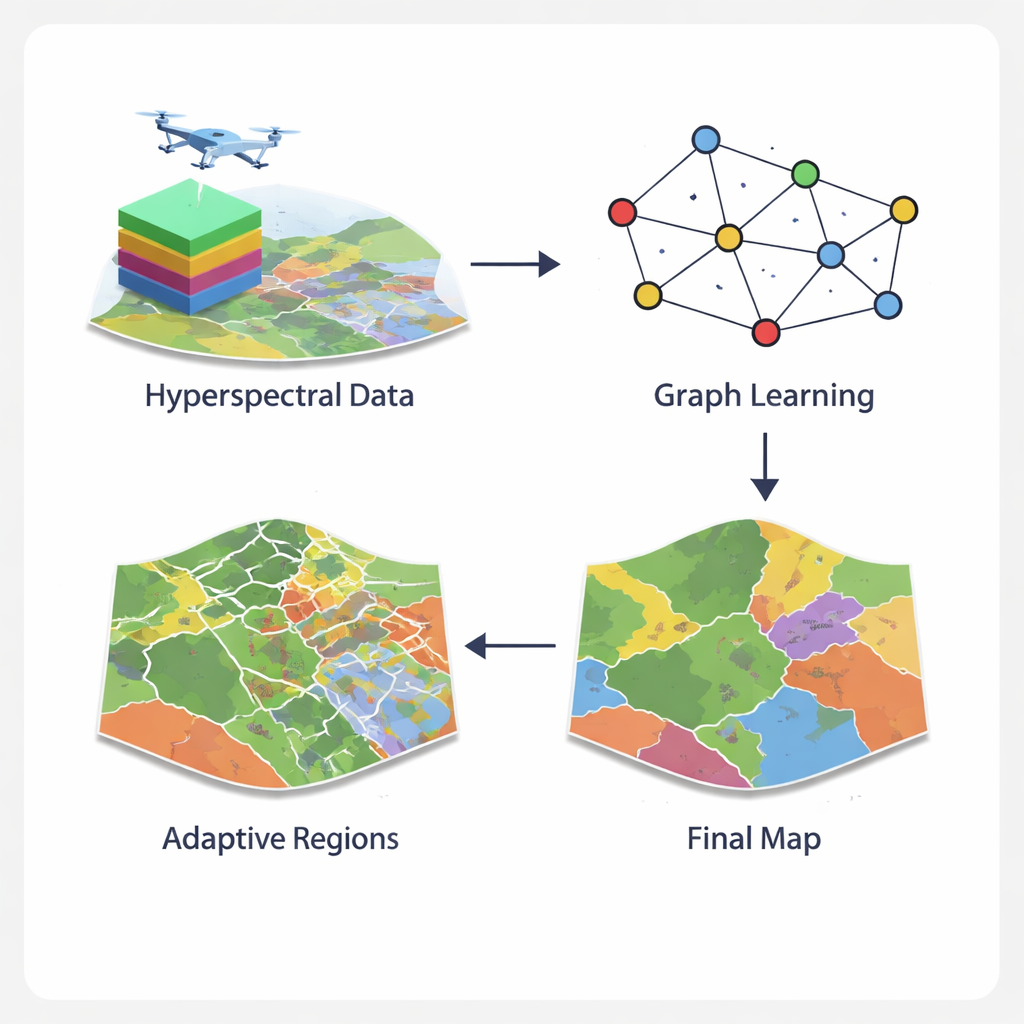
Turning Pixels into a Smart Network
The GCN-ARE framework tackles these issues by rethinking how hyperspectral images are represented. Instead of treating each pixel in isolation or forcing them into rigid square neighborhoods, the method builds a graph—a network where pixels are nodes and nearby pixels are linked. A specialized graph operator keeps information flow stable, preventing numerical problems that can derail training when terrain is messy. A graph‑convolutional network then spreads and refines information along this network, combining what each pixel "sees" in its spectrum with what its neighbors reveal. This graph view captures complex spatial layouts, such as jagged field boundaries or fragmented urban vegetation, more naturally than standard image filters.
Cutting Complex Regions Down to Size
Even with a powerful graph model, some parts of an image remain hard to classify—for example, border zones where crops meet roads or where vegetation mixes with bare soil. GCN-ARE addresses this by adaptively splitting the scene into regions based on how well they are being classified. If a region performs poorly, it is automatically subdivided into smaller, more uniform pieces using a clustering step that groups similar pixels together. This process is guided by statistical rules, so it is not just a visual trick: the authors show that, in theory, these splits reduce the model’s expected error, helping it distinguish subtle differences in land cover more reliably.
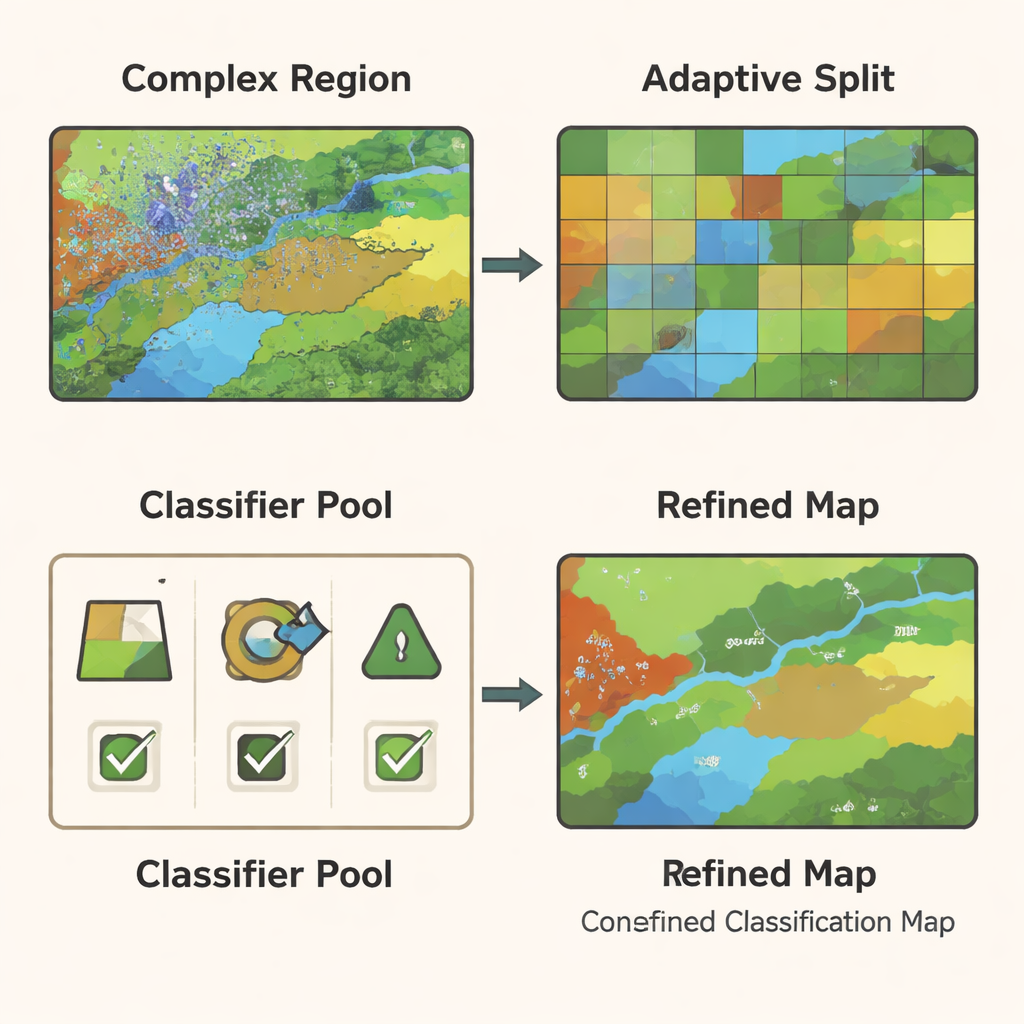
Letting Multiple Classifiers Vote—But Smartly
Different types of classifiers—such as decision trees, support vector machines, and random forests—excel in different conditions. Rather than betting on a single model, GCN-ARE trains a small pool of these classifiers on the graph‑based features and then chooses among them region by region. The choice is not made by guesswork: a mathematical tool called Hoeffding’s inequality is used to show that, as a region contains more data, the method’s chance of picking the truly best classifier rises quickly. During actual use, the system compares the classifiers’ predictions. If they agree, it accepts a consensus decision; if they disagree, it activates the region’s selected "best" classifier. This adaptive ensemble makes the final map both stable in easy areas and sharper in difficult ones.
Proving It Works in the Real World
The authors tested GCN-ARE on four well‑known datasets: wetlands in Botswana, an urban area around Houston, farmland in Indiana (Indian Pines), and a high‑resolution crop scene in China (WHU‑Hi‑LongKou). Across all of these, their method achieved higher overall accuracy, better average accuracy across classes, and stronger agreement scores than leading approaches such as graph attention networks and Vision Transformers—typically improving overall accuracy by about 1.5 to 5.7 percentage points. It was especially strong at recognizing rare classes and complex boundaries, and did so with modest computing time and memory. Ablation experiments showed that both the adaptive region splitting and the dynamic ensemble were essential—removing either noticeably reduced performance.
What This Means for Everyday Applications
In practical terms, GCN-ARE is a smarter way to turn raw hyperspectral data into trustworthy maps. By combining a stable graph representation, targeted region refinement, and statistically grounded model selection, it produces clearer land‑cover maps even when labeled training data are scarce and the landscape is messy. For farmers, this could mean more precise crop monitoring with fewer field measurements; for environmental agencies, more reliable tracking of wetlands, forests, or urban sprawl. While the current method still faces challenges at truly massive scales, the authors outline paths to make it faster and lighter, suggesting that such adaptive, confidence‑driven mapping tools will become increasingly important as hyperspectral sensors spread from satellites to planes and drones.
Citation: Chen, Y., Lu, H. & Huang, X. Collaborative representation and confidence-driven semi-supervised learning for hyperspectral image classification. Sci Rep 16, 6180 (2026). https://doi.org/10.1038/s41598-026-36806-6
Keywords: hyperspectral imaging, land cover mapping, graph neural networks, ensemble learning, remote sensing