Clear Sky Science · en
Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding
Why spotting fake news in Urdu matters
In Pakistan and around the world, more people now get their news from websites and social media than from newspapers or television. That shift has made it easier than ever for false stories to spread quickly, especially in national languages like Urdu where digital tools are limited. This study tackles a simple but urgent question: can modern artificial intelligence automatically tell real Urdu news from fake, helping ordinary readers, journalists, and platforms defend themselves against misleading information?
The growing challenge of online misinformation
The authors begin by outlining how fabricated headlines and distorted stories can shape public opinion, fuel political tensions, and even harm people’s health and finances. While many fact-checking websites and research projects focus on English, regional languages such as Urdu are often left behind. Existing Urdu resources include only a few thousand news items, many translated from English and focused on narrow topics like politics. That makes it hard to train reliable computer systems to recognize suspicious content in the language most Pakistanis actually read.
Building a large Urdu news collection
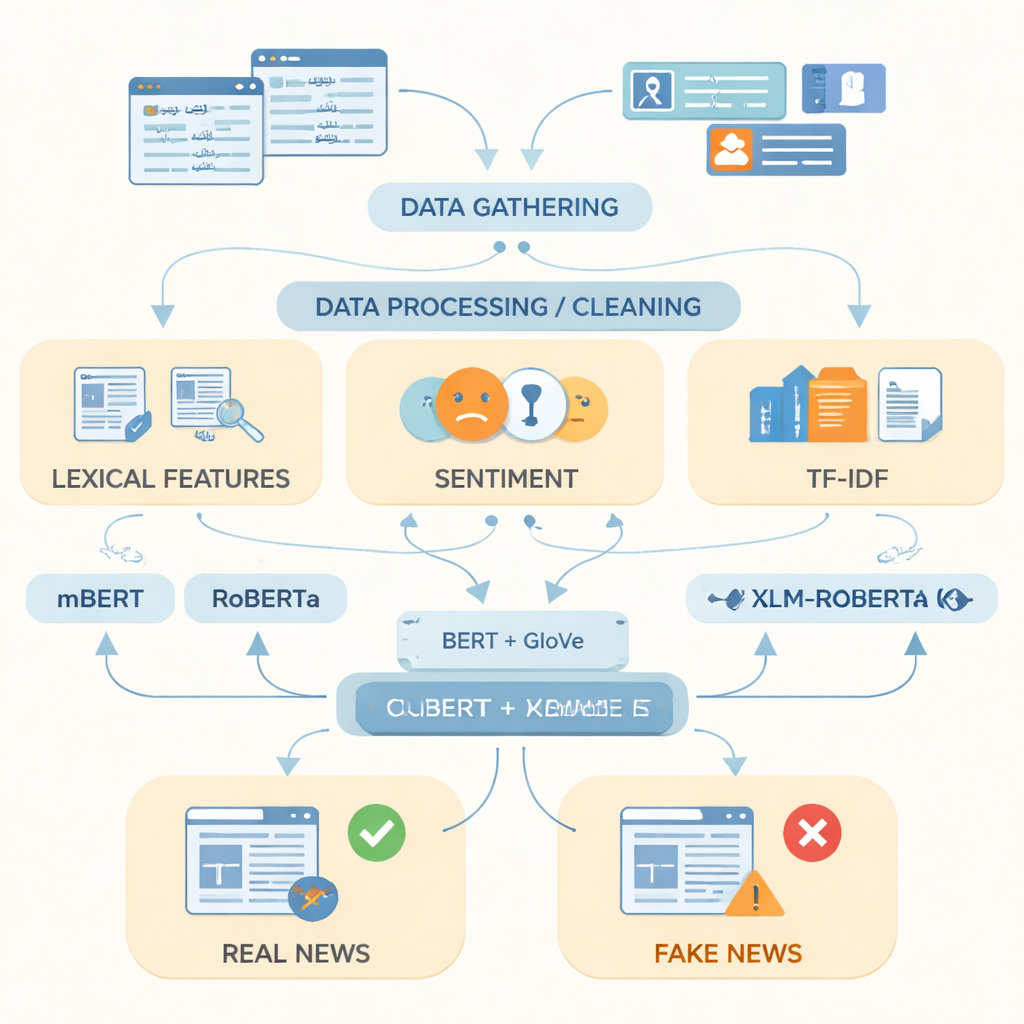
To close this gap, the researchers assembled what they describe as the most extensive Urdu fake news dataset to date, containing 14,178 news articles collected between 2017 and 2023 from respected Pakistani news websites and online platforms. The stories span fifteen areas of daily life, including politics, health, education, business, crime, sports, and the environment. Using fact-checking sources such as PolitiFact, FactCheck, and specialized news APIs, each item was labeled as real or fake; partly true items were grouped with real news to reflect more nuanced reporting. The team then cleaned the text by removing duplicates, web addresses, and extra punctuation, breaking sentences into words, and stripping out very common filler words.
Teaching computers what fake news looks like
After preparing the data, the authors focused on how best to represent Urdu text for a computer. They combined simple indicators like frequently used words, the emotional tone of the language, and term frequency scores with two powerful word-representation techniques. One, called GloVe, treats each word as a fixed numerical vector based on how often it appears with other words across the whole collection. The other, based on BERT-style models, looks at each word in its sentence and assigns it a context-aware meaning. By joining these two views of language into a single, richer representation, the system can capture both overall patterns and subtle shifts in wording that often distinguish fake from real stories.
Putting advanced language models to the test
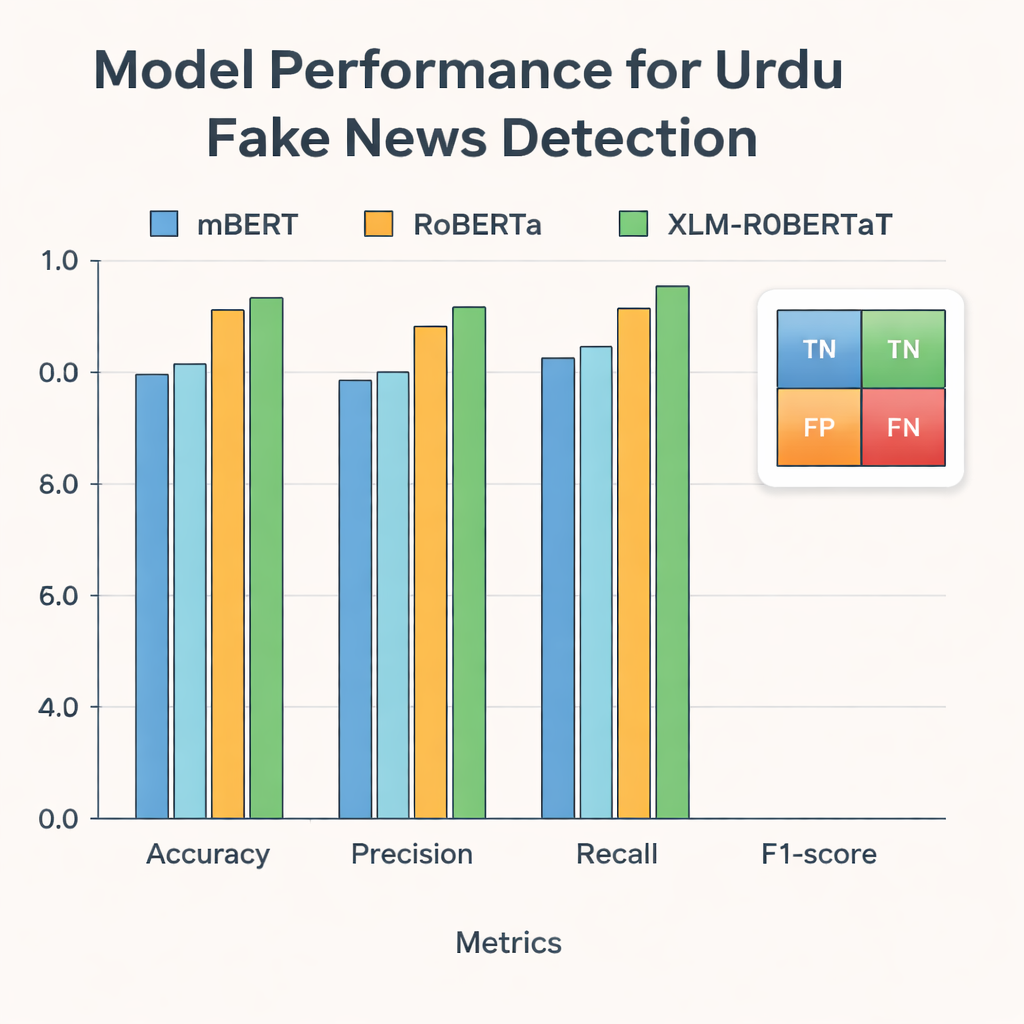
The researchers then fed these representations into three modern deep learning models that have been trained on text from many languages: mBERT, RoBERTa, and XLM-RoBERTa. All three were fine-tuned on the Urdu dataset to predict whether each article was real or fake. Their performance was judged using standard measures: accuracy (how often they were correct), precision (how often flagged fakes were truly fake), recall (how many of all fake stories they caught), and the F1-score, which balances precision and recall. While every model performed strongly, XLM-RoBERTa combined with the fused BERT and GloVe representation came out on top, correctly classifying about 96 percent of the test articles and achieving an F1-score of 0.956—better than previous Urdu fake news systems that used smaller datasets or simpler methods.
What this means for everyday readers
For non-specialists, the message is straightforward: with enough high-quality Urdu news data and the right type of AI, it is now possible to build tools that automatically flag likely fake stories with high reliability. The study shows that richer language representations and multilingual models give computers a much better grasp of how Urdu is actually written in different regions and topics. Although the current work focuses on text alone and does not yet analyze images or social media behavior, it lays a strong foundation for future systems that could work across languages and media types. In practical terms, this research moves Pakistan a step closer to browser plug-ins, newsroom dashboards, or social media filters that help people separate fact from fiction in the language they use every day.
Citation: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Keywords: fake news detection, Urdu language, deep learning, BERT and GloVe, online misinformation