Clear Sky Science · en
Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion
Seeing Depth with a Single Eye
Modern robots, self-driving cars, and drones often rely on expensive 3D sensors to understand how far away things are. This study shows how ordinary color cameras, like those in smartphones, can be pushed much further: the authors design a new way for a computer to infer depth from just one picture, and they focus on the hardest part of the scene to get right—the far distance, where obstacles are tiny, blurry, and easy to misjudge.
Why Faraway Objects Are So Hard to Judge
Depth from a single image, called monocular depth estimation, is a kind of visual trick. Nearby objects cover many pixels and have sharp textures, so today’s neural networks already do well at short and medium ranges. Farther away, however, cars shrink to a few pixels and road markings fade into haze. Standard convolutional neural networks are good at noticing fine local details but have trouble taking in the big picture of an entire street. Newer Transformer models see global context well, but they are less sensitive to tiny edges and textures. As a result, both families of methods often stumble exactly where safe navigation most needs reliable estimates: at long distances.
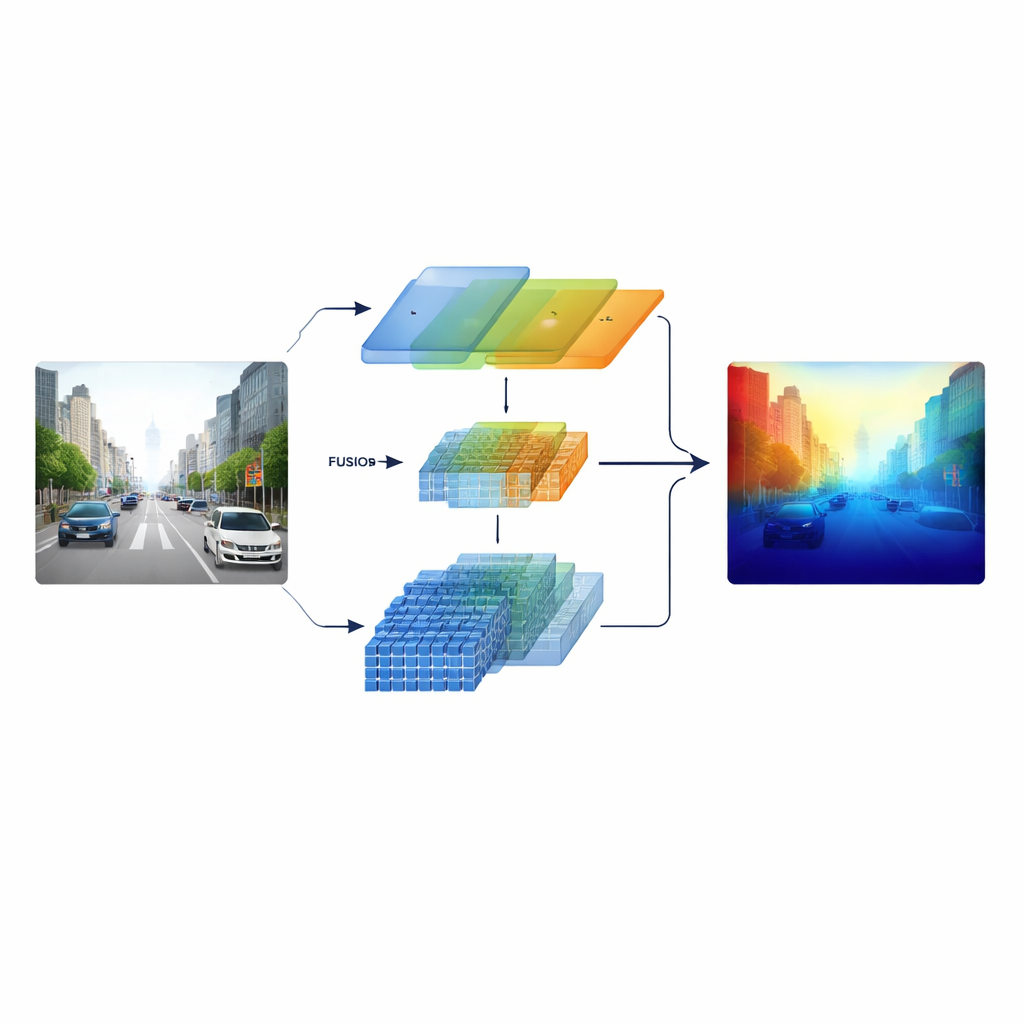
Blending Two Ways of Seeing
The researchers tackle this by building a “heterogeneous” encoder that runs two different types of visual processing in parallel. One branch is based on a classic ResNet-style convolutional network that specializes in crisp local patterns such as lane markings, poles, and object edges. The other branch uses a Swin Transformer, which is designed to capture long-range connections across the image, such as the layout of a road corridor or the skyline of distant buildings. Instead of combining these two views only at the end, the system keeps multi-scale features from both branches and feeds them into a carefully designed fusion stage, so that fine structure and broad context inform one another throughout.
Crossing Channels, Space, and Scale
At the heart of the model is a Cross-dimensional Semantic Fusion module that acts like an intelligent meeting room for the two streams of information. First, it decides which channels—different types of learned visual patterns—deserve more attention, balancing signals from detailed textures and high-level scene cues. Next, it looks separately along horizontal and vertical directions, which are especially meaningful in scenes full of roads, buildings, and trees, to highlight important structures that stretch across the image. Finally, it mixes shallow, detail-rich features with deeper, more abstract ones across several scales. A learnable weighting step lets the network decide how much to trust each branch for each region, so small, faraway objects are not drowned out by nearby scenery.
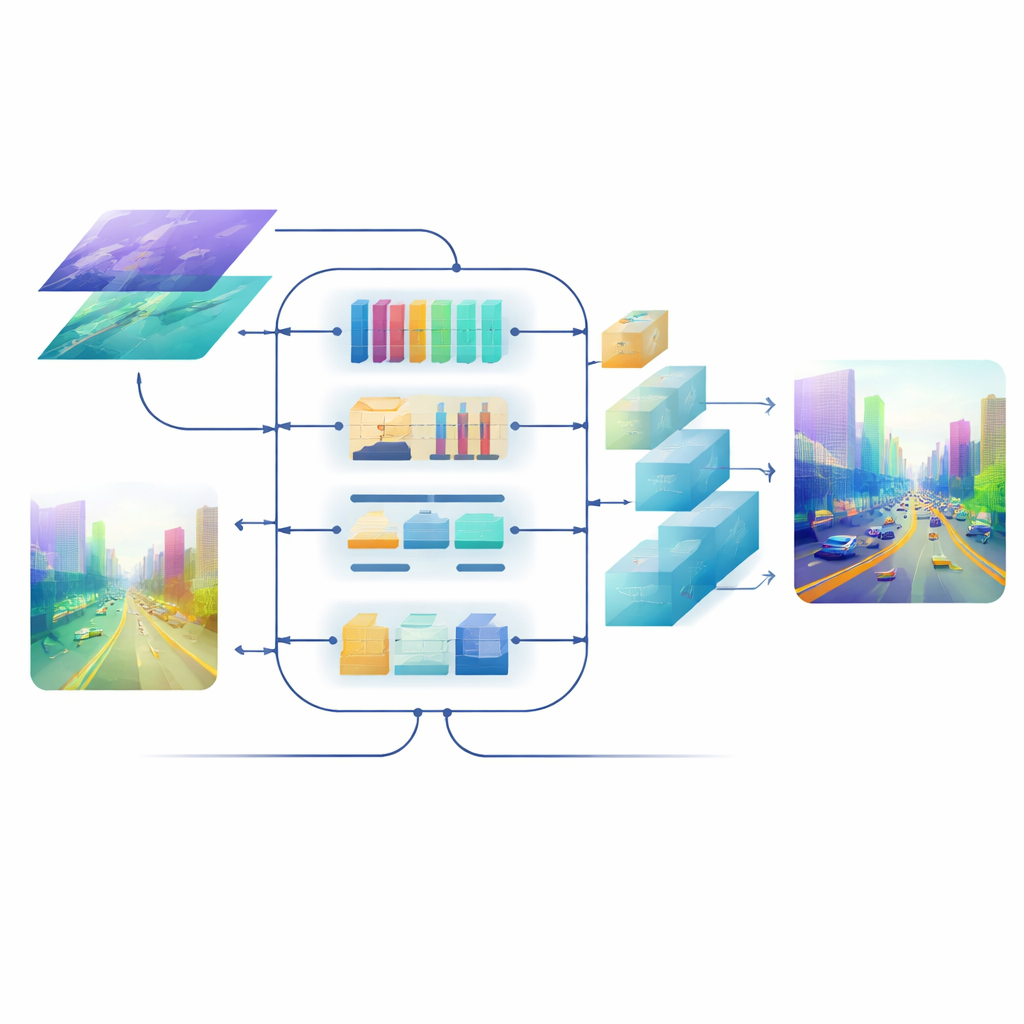
Sharpening the Final Picture
Even with good fused features, turning them back into a full-resolution depth map can blur edges and wash out thin structures. To avoid this, the team designs an attention-driven decoder. Its upsampling blocks use lightweight, depth-wise convolutions to enlarge the map without losing context, and a multi-scale self-attention mechanism groups feature channels so that attention can be computed efficiently. This step refines depth predictions at each scale while keeping computation in check. The result is a smooth, coherent depth field where object borders—like the outline of a distant cyclist or the rungs of a bunk bed—remain sharp.
How Well It Works in the Real World
The method is tested on several standard datasets. On KITTI, a large collection of driving scenes, the model achieves state-of-the-art accuracy on most common metrics and, crucially, produces the lowest error in designated long-range regions. It also yields cleaner depth boundaries around objects than competing systems. On NYU Depth V2, which contains indoor scenes, and on the SUN RGB-D benchmark, the same model successfully generalizes, reconstructing furniture and room layouts in convincing 3D point clouds. Ablation studies—systematic tests that remove or swap components—show that each proposed piece, from the hybrid encoder to the fusion module and the decoder’s attention block, measurably improves performance, especially for distant, low-texture areas.
What This Means for Everyday Technology
In simple terms, this work teaches a neural network to use both a magnifying glass and a wide-angle lens at once, and to combine them wisely. By better balancing local details with global scene understanding, the proposed framework significantly improves how well a single camera can judge depth far down the road or across a room. That makes it more practical to equip robots, vehicles, and drones with cheaper sensors while still giving them a rich 3D sense of the world—an important step toward safer, more capable, and more affordable autonomous systems.
Citation: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Keywords: monocular depth estimation, computer vision, transformer and CNN fusion, autonomous driving, 3D scene reconstruction