Clear Sky Science · en
Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems
Why smarter AI memory matters
As chatbots and AI assistants move into workplaces, classrooms, and even hospitals, they increasingly rely on a trick called “remembering” past questions so they can answer similar ones faster and cheaper. This memory, known as a semantic cache, can dramatically cut costs and delays—but it can also open a back door for attackers to trick systems into leaking secrets or giving wrong answers. This paper explores those hidden risks and introduces a new design, SAFE-CACHE, that aims to keep AI’s memory fast while making it far harder to abuse.
How today’s AI assistants reuse past answers
Modern large language models (LLMs) often work inside a setup called retrieval-augmented generation (RAG). When you ask a question, the system first looks up relevant documents and then has the LLM write an answer using that material. Because many people ask nearly the same question in different words, companies now add a semantic cache: a store of old questions and answers, plus mathematical fingerprints of their meanings. When a new query arrives, the system checks whether its fingerprint is “close enough” to one already in the cache; if so, it simply reuses the old answer instead of running the whole search-and-generate process again. This idea, deployed by tools like GPTCache and cloud platforms from Microsoft and Google, saves money and speeds up responses across customer support bots, enterprise chat tools, and other high-traffic AI services. 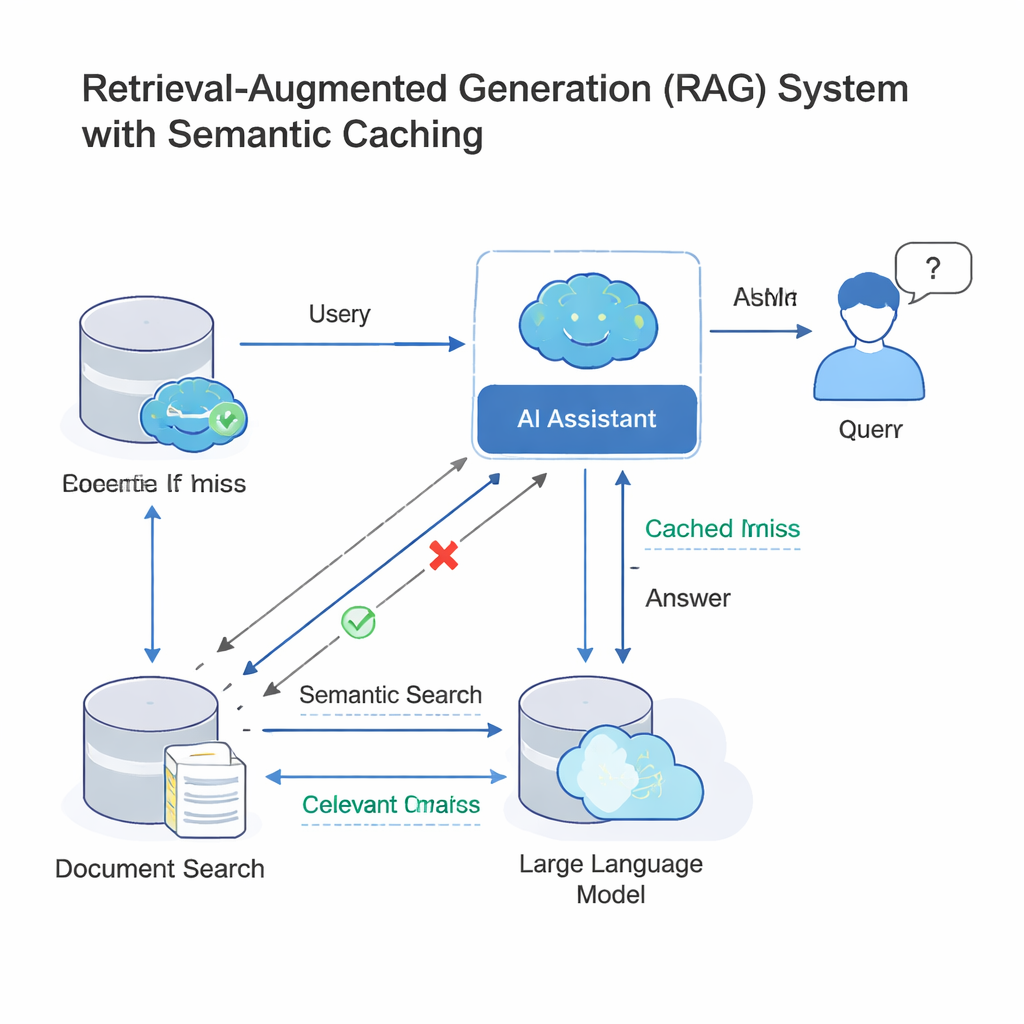
When clever wording turns into a security hole
The same shortcut that boosts speed can also be turned against the system. Attackers can craft queries that look similar in structure but mean something different—changing a date, swapping a person or place, or flipping the meaning of a question. Because today’s caches mostly trust the numeric similarity of embeddings (those fingerprints of meaning), a malicious query can “collide” with a benign one in this vector space, even though the intent has shifted. That collision can cause the cache to return the wrong answer, potentially exposing confidential information or letting bad data be stored for later reuse. Prior work has already shown that vector databases and semantic caches can be poisoned in this way, especially when many users share the same underlying cache in multi-tenant systems.
Turning scattered questions into stable intent clusters
The authors argue that the root problem is treating each query in isolation. Their solution, SAFE-CACHE, groups past question–answer pairs into clusters that represent underlying intents—like “who won the 2022 Arizona Senate race?” or “what is the price of Tesla’s Full Self-Driving software?” Instead of matching new queries directly to individual old ones, SAFE-CACHE compares them to the center, or centroid, of each cluster. To build these clusters, it first embeds each full question-plus-answer (not just the question alone) so that differences in responses—such as a refusal to reveal sensitive data—also shape the grouping. It then uses a community-detection algorithm to find natural clusters and statistical tests to flag noisy groups that might mix different intents or adversarial entries. These suspect clusters are cleaned and split using a specially trained bi-encoder that has learned to pull together honest examples and push apart poisoned ones.
Teaching a small model to strengthen AI’s memory
Some intents show up only a few times in real traffic, making their clusters fragile. To stabilize them, SAFE-CACHE uses a fine-tuned lightweight language model (a 1‑billion-parameter Gemma-3 variant) to generate paraphrases that keep the same intent while varying the wording. These extra examples make the clusters denser and their centroids more reliable, without needing humans to label thousands of variants. At run time, every new query is embedded and compared to these centroids. If its similarity to the best-matching centroid is above a carefully tuned threshold, the cached answer is returned; otherwise, the system falls back to the full RAG pipeline and later decides how to cluster the new pair. In experiments using strong attack methods based on metamorphic rewriting and GPT‑4.1, SAFE-CACHE cut successful poisoning attempts by roughly two-thirds to three-quarters compared with a GPTCache-style design, while keeping response speed essentially unchanged. 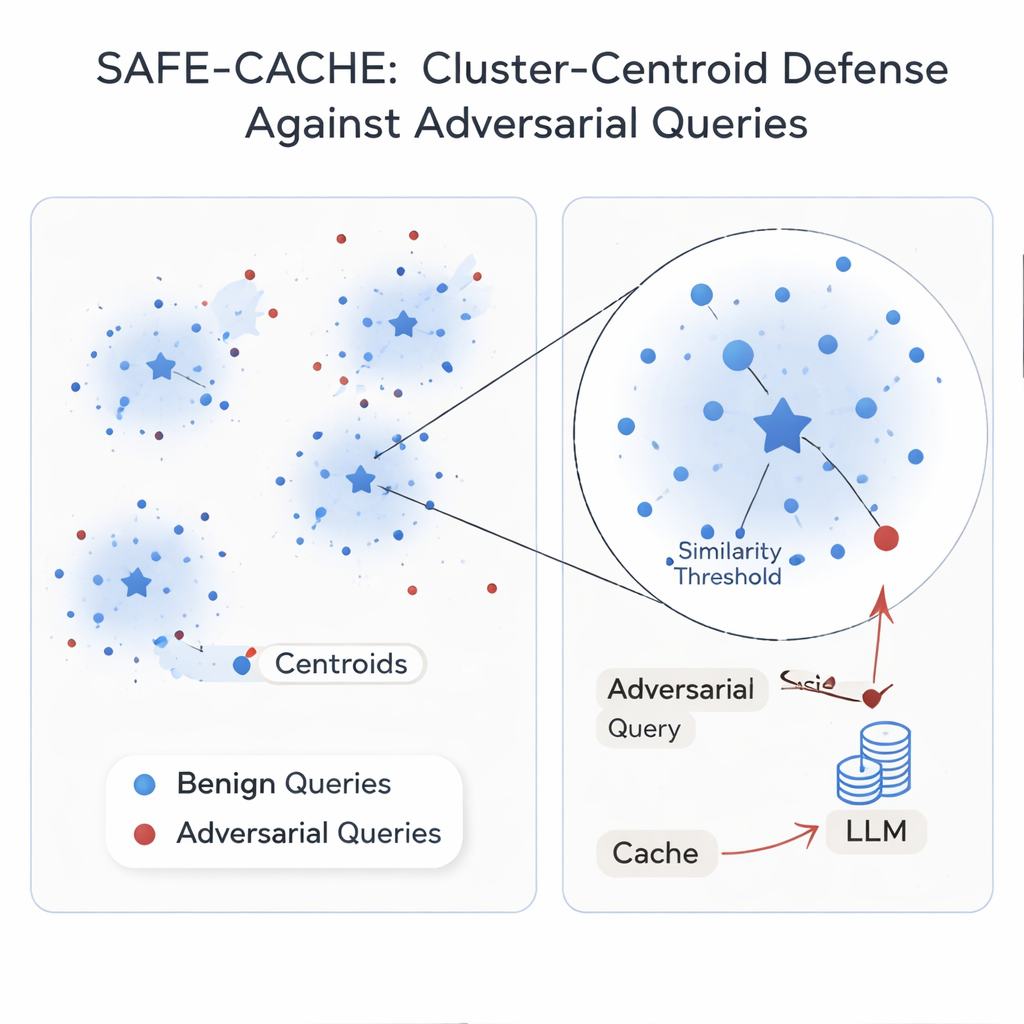
What this means for everyday AI users
For non-specialists, the takeaway is that giving AI systems “memory” is not free: naive designs can leak secrets or be tricked into spreading bad answers. SAFE-CACHE shows that by organizing memory around deeper, intent-level patterns and reinforcing those patterns with targeted paraphrases, it is possible to keep the speed and cost benefits of semantic caching while sharply reducing the risk of attack. As AI assistants become a front door to sensitive data—from company records to personal information—approaches like SAFE-CACHE will be key to making sure that what AI remembers can’t easily be turned against us.
Citation: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Keywords: semantic caching, retrieval-augmented generation, adversarial attacks, cluster-based defense, LLM security