Clear Sky Science · en
Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning
Sharper Views from Space
Satellite images power everything from city planning to disaster response, but many pictures are fuzzier than we would like because of limits in camera hardware and data transmission. This paper presents a new way to turn blurry satellite photos into sharper ones at any chosen zoom level, using a learning strategy that can adapt to the special look of aerial imagery without needing to be retrained for every situation.
Why Sharper Satellite Images Matter
High‑resolution remote sensing images are crucial for spotting small objects, tracking changes on the ground, and mapping land use in detail. Yet real-world satellites must trade off resolution against cost, sensor size, and bandwidth, so many images arrive at lower quality than analysts would prefer. Traditional “super‑resolution” techniques can sharpen images but are usually trained for a fixed zoom, like exactly two or four times larger. That means operators need separate models for each zoom level, which is inefficient and inflexible when dealing with many satellites and varied tasks.
Beyond One-Size-Fits-All Zoom
Recent research has developed “continuous‑scale” super‑resolution, which treats an image as a smooth signal and can generate sharp outputs at any zoom factor with a single model. Most of these methods were built and tested on everyday photos, not satellite data. They typically decide how to mix nearby pixel information using fixed geometric rules—essentially weighting neighbors by distance. This works reasonably well for natural scenes like faces or landscapes, but satellite images contain dense buildings, repetitive textures, and abrupt edges that do not follow the same patterns. When models trained on natural photos are applied to satellite views, their assumptions break down, and details like rooftops, roads, and vehicles are not faithfully recovered.
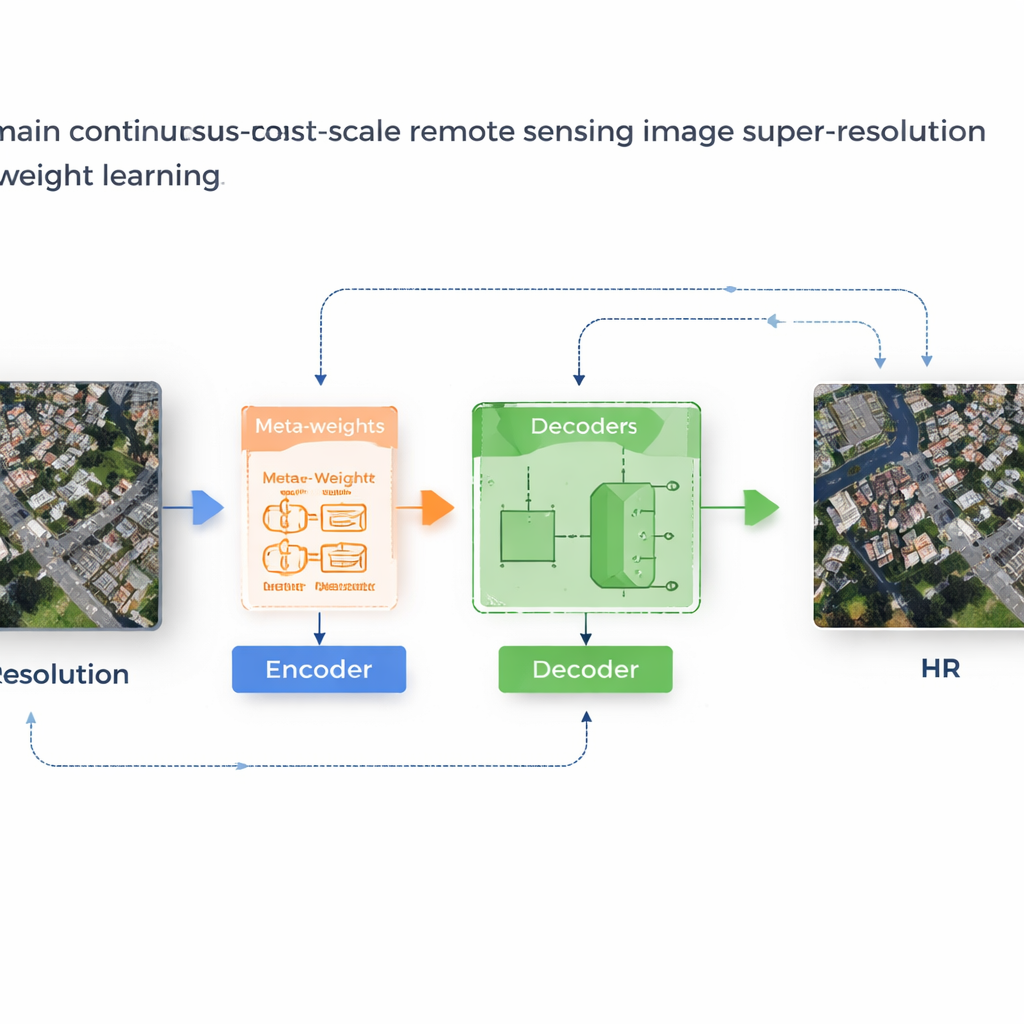
A Learning System That Adapts Its Own Rules
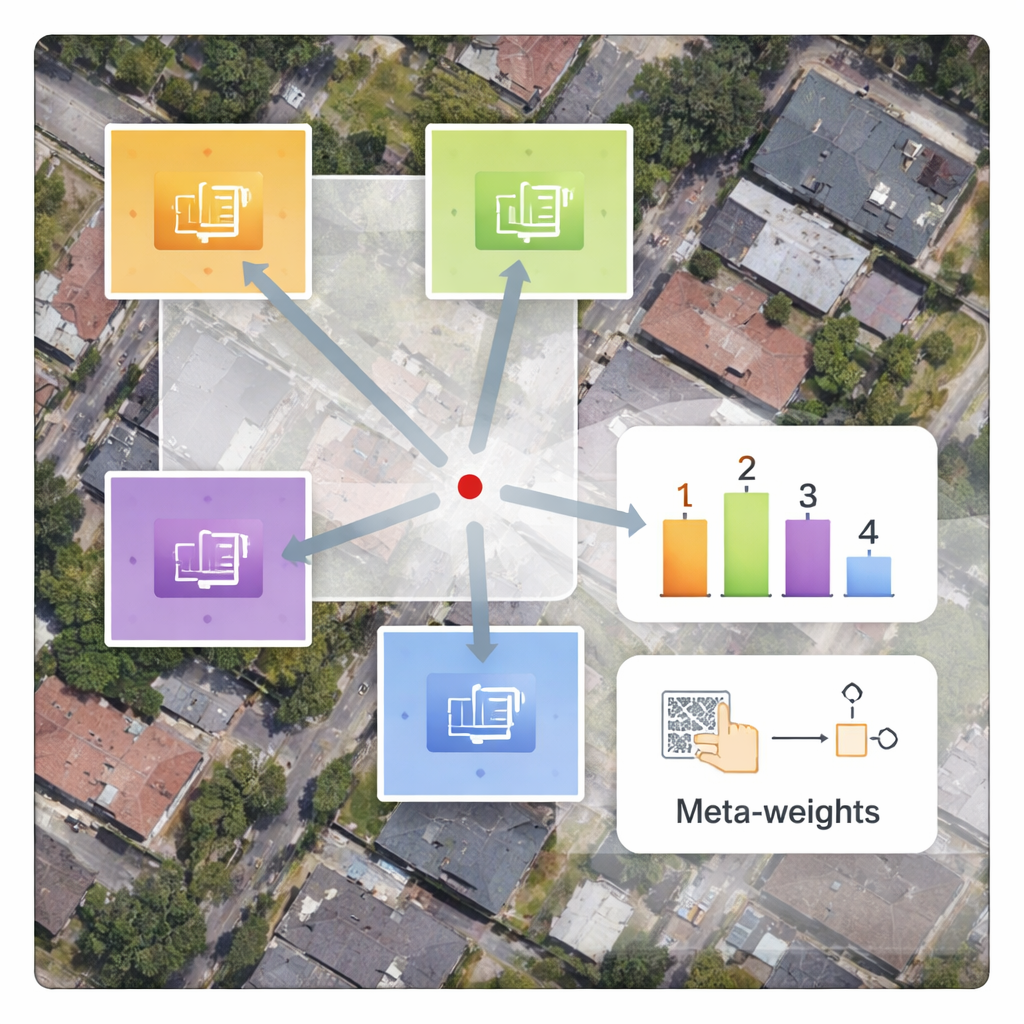
The authors propose a framework called MLIN (Meta-Learning-based Implicit Neural Network) to solve this cross‑domain problem. Instead of handcrafting how nearby pixel features should be combined, MLIN learns these combination rules from data. It keeps a powerful image encoder that was originally trained on natural photos completely frozen, so it can still extract rich visual patterns without being distorted by the smaller satellite datasets. On top of this, MLIN adds a new “implicit decoder” equipped with a meta‑learning module. For each point in the high‑resolution image the model wants to reconstruct, this module looks at the surrounding features and their precise positions and then predicts a set of soft weights that tell the decoder how strongly to use each neighbor. In other words, the system no longer assumes that distance alone matters; it lets local content—such as textures of roofs, fields, or water—shape the reconstruction.
From Blurry Blocks to Crisp Structures
Technically, the method works by sampling a small 2×2 neighborhood of hidden features around every target location in the output image. A meta‑network then combines information about these features, their relative coordinates, and the requested zoom factor to choose weights that sum to one. The decoder uses these weights to blend predictions from each neighbor, producing a final color value at that location. Because this weighting is learned, MLIN can treat complex regions—like dense residential blocks, ports with ships, or airports with runways—very differently from smooth areas like deserts or oceans. Experiments on two widely used satellite datasets (WHU‑RS19 and UCMerced) show that MLIN consistently delivers higher numerical quality scores and visibly sharper details than several leading continuous‑zoom methods, across both familiar zoom levels and extreme enlargements as high as ten times.
Faster Training Without Extra Delay
A practical advantage of the design is that only the new decoder and meta‑weight network need to be trained on satellite images, while the large encoder remains fixed. This greatly reduces training time compared with methods that retrain all parameters from scratch. Even though the meta‑network introduces extra computation, modern graphics processors handle these operations efficiently, so the time to process a single image stays almost the same as existing approaches. Ablation studies—careful tests where parts of the system are removed or simplified—confirm that the content‑aware weighting is the key ingredient that improves both edge sharpness and texture continuity.
Clearer Eyes on Earth
In plain terms, this work shows how to reuse powerful image models trained on everyday photos and smartly adapt them to the very different world of satellite imagery. By letting the system learn how to balance information from nearby pixels based on what is actually in the scene, MLIN produces clearer, more reliable satellite images at any zoom level from a single model. That means better tools for scientists, planners, and emergency responders who rely on detailed views of our planet, all while keeping computation and storage demands manageable.
Citation: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Keywords: satellite super-resolution, remote sensing imagery, meta-learning, arbitrary-scale zoom, image enhancement