Clear Sky Science · en
Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling
Why this matters for future doctor visits
Artificial intelligence systems that talk and write, known as large language models, are rapidly moving from research labs into hospitals. They can already help doctors read complex charts, suggest treatments, and answer medical questions. But most tests of these systems give only a single overall score, much like a final exam grade, which can hide dangerous blind spots. This study shows a new way to look inside those scores and reveal exactly which areas of medicine these models truly understand—and where they could still put patients at risk.
Looking beyond a single test score
Today, most medical AI is judged on how many questions it answers correctly on exams modeled after doctor licensing tests. That approach is simple but crude. A model might earn a high overall score while still being weak in a critical field such as heart rhythm analysis or liver disease. In real clinics, such gaps can have life-or-death consequences. The authors argue that safe use of AI in medicine demands a deeper, more fine-grained evaluation—one that can map out a detailed skill profile instead of handing out a single, possibly misleading, grade.

A smarter way to test medical know-how
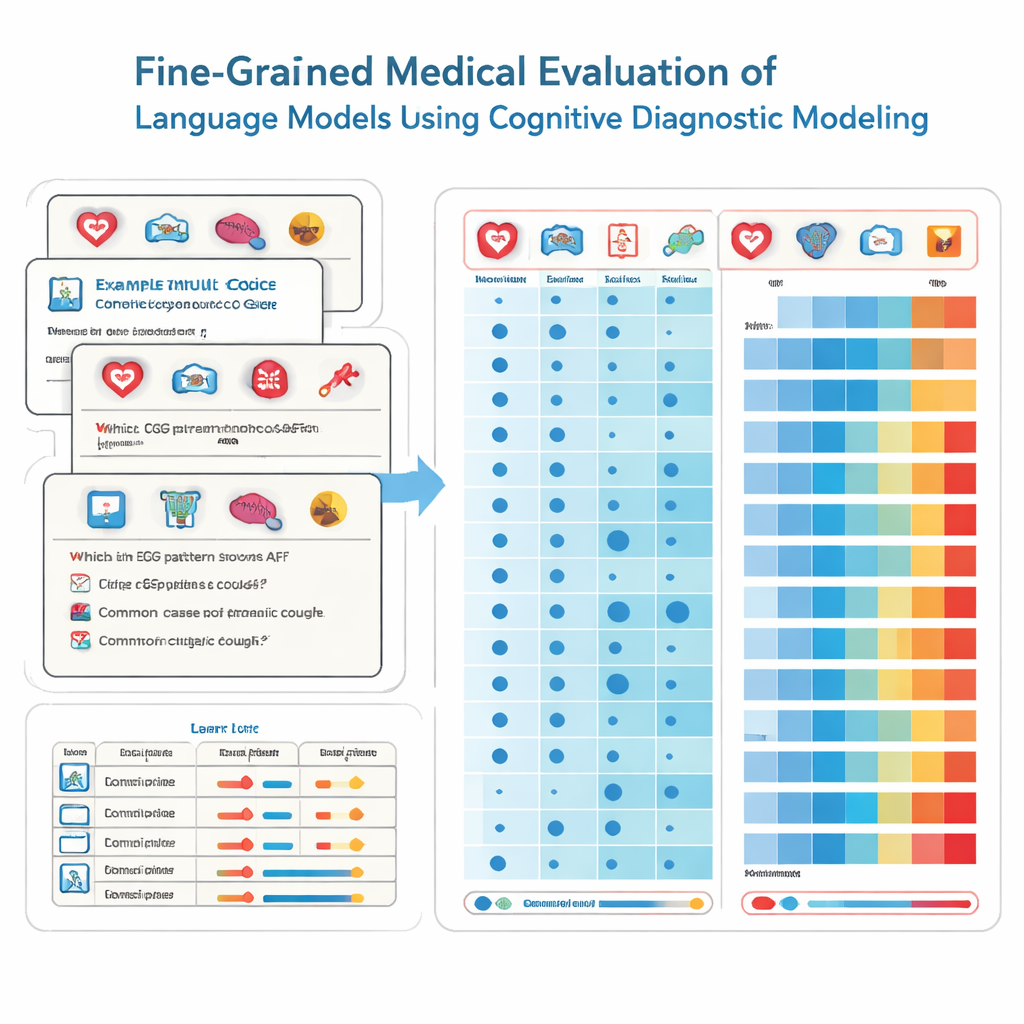
To achieve this, the researchers borrow tools from educational psychology called cognitive diagnostic assessment. Instead of treating every exam question as if it measured the same vague ability, this method breaks medical knowledge into specific building blocks, like cardiology, radiology, or emergency care. Each multiple-choice question is tagged with the exact mix of skills it requires. Using a non-parametric statistical technique, the team compares how a model answers thousands of such questions to ideal response patterns. From this, they infer whether the model has “mastered” each underlying skill, much as a detailed report card might show strengths and weaknesses across school subjects.
Putting 41 AI models through a medical exam
The team tested 41 widely used language models, including both commercial systems and open-source models, on 2,809 carefully vetted questions drawn from a Chinese national medical test bank. These questions span 22 medical subdomains and are designed for students about to take their physician licensing exam. Every question has one correct answer and is labeled by experts to indicate which specialties it touches. Using their diagnostic method, the researchers estimated, for each model, how many of these 22 medical attributes it effectively mastered, not just how many questions it happened to get right.
Strong general knowledge, but sharp blind spots
The results are both impressive and worrying. The best-performing models, such as several leading commercial systems, scored correctly on most questions and showed mastery of 20 out of 22 medical domains. Across all models, performance was excellent in many common specialties, achieving full mastery in 15 areas including cardiology, dermatology, and endocrinology. Yet the fine-grained analysis exposed stark gaps in others. Radiology lagged behind with much lower mastery rates, and two subdomains—ECG & hypertension & lipids and liver disorders—were not mastered by any model. Importantly, some smaller models shared the same mastered skills as much larger ones, revealing that sheer size does not guarantee broad, reliable medical knowledge.
Choosing the right tool for the right job
These detailed profiles matter because models with very similar overall scores can have very different patterns of strengths and weaknesses. One system might be strong in neurology but weak in pharmacology, while another shows the opposite pattern. For hospital leaders, this means they cannot safely select an AI assistant based only on its headline exam score or number of parameters. Instead, they need diagnostic results like those in this study to match each model to specific clinical tasks, and to design workflows where human specialists double-check AI output in high-risk areas where the model is known to be weak.
What this means for patients and clinicians
In plain terms, the study concludes that a high “grade” on medical tests does not guarantee that an AI system is safe to use across all parts of medicine. The new approach works more like a thorough health check-up for the AI itself, revealing which organs—in this case, medical specialties—are healthy and which need attention. By uncovering hidden gaps in critical areas such as ECG interpretation and liver disease, the method gives hospitals, regulators, and developers a practical roadmap: use models only where they have been proven strong, keep humans firmly in the loop where weaknesses remain, and focus future training on the riskiest blind spots. This kind of fine-grained evaluation, the authors argue, is not just helpful—it is essential before trusting AI with patient care.
Citation: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Keywords: medical AI, large language models, clinical safety, model evaluation, diagnostic testing