Clear Sky Science · en
Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization
Smarter AI That Can Juggle Many Jobs at Once
Modern apps increasingly rely on artificial intelligence that must do several things at the same time—such as understand images and text together, support medical decisions, or help cars perceive the road. But when one AI model learns too many skills at once, its training can become unstable and the skills can interfere with each other. This paper introduces a new deep‑learning framework, called the Unified Multitask and Multiview Deep Architecture (UMDA), designed to let one model learn from many data types and solve many tasks without getting confused or unstable.
Why Today’s Multi‑Skill AI Often Struggles
Most current systems that learn several tasks (multitask learning) or combine several data types, such as images and text (multiview learning), suffer from three big issues. First, different tasks can fight each other during training: improving performance on one task can quietly harm another, a problem known as negative transfer. Second, simply stacking or averaging information from different data sources often loses subtle but important relationships between them. Third, the training process itself can become shaky, with large swings in the direction in which the model’s parameters are updated. These issues are especially serious in real‑world settings like medical diagnosis or industrial inspection, where the data is complex and decisions must be reliable.
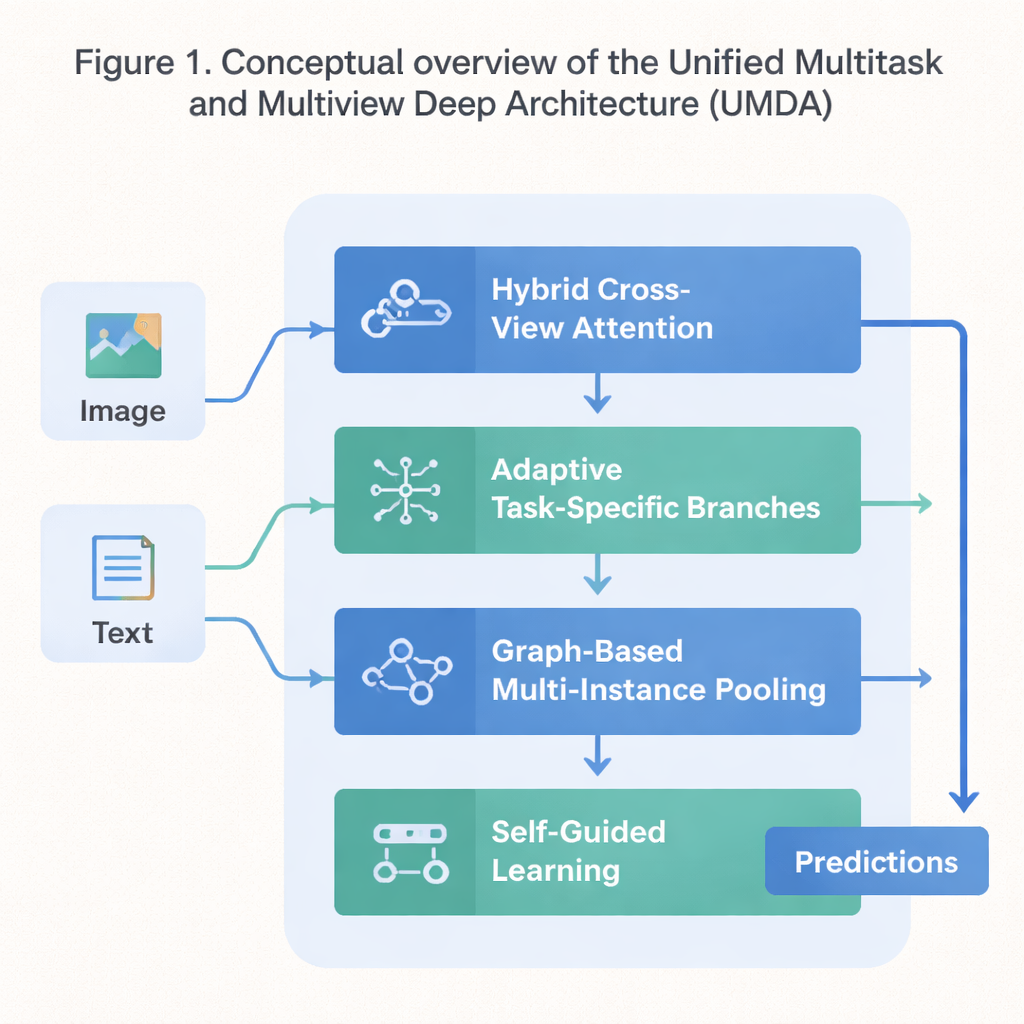
A Four‑Part Blueprint for Cooperative Learning
UMDA tackles these weaknesses by breaking the learning process into four tightly connected parts that share information in a controlled way. The first part, called Hybrid Cross‑View Attention, looks at different views of the same data—such as text and images describing a movie—and learns which view should influence another at each step. It uses math tools that encourage the model to avoid over‑relying on a single view, to keep each view distinctive, and at the same time to keep them broadly in agreement. In simple terms, it teaches the model to listen to all of its “senses” without letting one drown out the others.
Keeping Tasks Distinct but Still Cooperative
The second part, Adaptive Task‑Specific Branching, separates generic knowledge that many tasks share from the special knowledge each task uniquely needs. Instead of forcing all tasks to use exactly the same features, UMDA builds separate “branches” for each task that can still talk to one another through carefully weighted connections. Extra penalty terms in the training objective push these branches to be different enough to specialize, yet not so different that they drift apart and stop cooperating. This balance helps reduce harmful interference among tasks while still letting them benefit from what the others learn.
Seeing Structure in Collections of Examples
Many real datasets come as collections of related items—for example, multiple image patches from a single medical slide or many frames from a video. The third part of UMDA, called Graph‑Based Multi‑Instance Pooling, explicitly models the relationships among these items by treating them as nodes in a network. It connects similar items, lets information flow along these connections, and then summarizes the whole collection into a single compact representation. Extra regularization nudges nearby items to agree with each other while still keeping enough diversity, allowing the model to capture structural patterns that simple averaging would miss.
Self‑Tuning Training for Steady Progress
The final part, Self‑Guided Learning, focuses on how the model is trained rather than on its internal structure. It continuously measures how strong and how similar each task’s training signals are and then automatically adjusts the learning speed for each task. It also smooths and re‑weights the gradients—the signals that tell the model how to change—so that tasks with similar goals reinforce each other and tasks that pull in very different directions do not destabilize training. When tested on a standard dataset that mixes movie plots and posters, UMDA achieved higher average accuracy than a dozen state‑of‑the‑art competitors, kept the relationship between views more consistent, and reduced a key measure of training instability by more than half.
What This Means for Real‑World AI Systems
For non‑specialists, the key message is that UMDA offers a way to build single AI models that can handle multiple data types and objectives more reliably. By teaching the model when to share information and when to keep it separate, and by letting it automatically tune how it learns, the framework delivers better predictions, more coherent internal representations, and smoother training. This makes it a promising building block for future systems in medicine, autonomous driving, and other complex applications where AI must interpret many signals at once without losing its balance.
Citation: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Keywords: multitask learning, multimodal AI, deep learning stability, attention networks, graph neural networks