Clear Sky Science · en
An automated framework for qur’anic education of the hearing-impaired using body pose classification and Arabic sign language integration
Opening a Sacred Text to Silent Voices
For many deaf and hard-of-hearing Muslims, learning to recite the Qur’an can be painfully difficult, because traditional teaching depends on listening and repeating. This study introduces a technology-based teaching aid that "sees" Arabic Sign Language gestures and links them to verses from a short chapter of the Qur’an. By turning body movements into a bridge between sign and scripture, it aims to make religious learning more inclusive for millions of people who communicate primarily through sign language.
Why Hearing-Impaired Learners Are Left Out
Deaf Muslims often rely on gesture and sign to communicate, yet most Qur’anic education is built around sound—teachers recite aloud, students imitate the melody and pronunciation. Families may not know sign language well, and qualified sign interpreters are scarce, especially for religious material. As a result, many deaf believers struggle to access the same level of spiritual education as their hearing peers. Recent advances in computer vision and artificial intelligence, which can recognize hand and body movements from camera images, offer a way to change that by turning sign language into something a computer can understand and respond to in real time.
Turning Gestures into Teachable Units
The researchers focused on Sūrat al-Ikhlāṣ, a short but theologically rich chapter that many Muslims memorize early in life. Working with institutions that serve deaf users in Egypt, they recorded 2,054 images of Arabic Sign Language gestures that correspond to individual Qur’anic words from this chapter. To avoid confusion about meaning and pronunciation, each gesture was labeled using both Arabic script and a standardized transliteration system widely used in academic Islamic studies. This careful labeling ensures that the system links each sign to the correct Qur’anic term, while remaining flexible enough to expand to other chapters in the future.
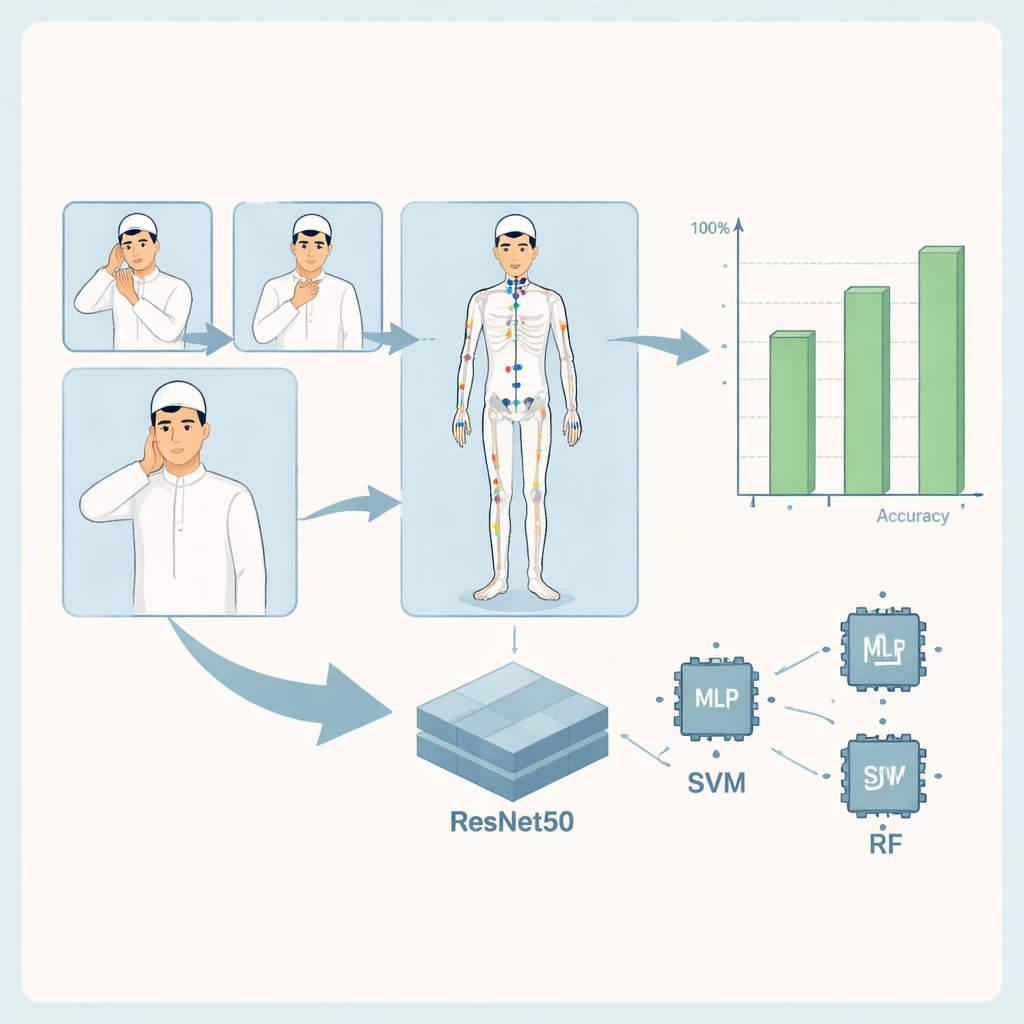
How the Computer Learns to See Prayerful Poses
At the heart of the system is a visual pipeline that first detects the signer’s body pose and then classifies which Qur’anic word is being signed. All images are resized and cleaned to a standard format. A software toolkit called MediaPipe identifies 33 key points on the body—such as shoulders, elbows, and wrists—and tracks their positions. These coordinates form a compact description of each pose, which is then fed into three kinds of machine-learning models: a custom multi-layer perceptron (a simple neural network), a support vector machine, and a random forest made of many small decision trees. In parallel, a more powerful deep-learning model, ResNet50, analyzes the full image to learn detailed visual patterns associated with each word.
Remarkably Accurate Recognition of Qur’anic Signs
To test the system, the authors split their dataset into training, validation, and test sets and evaluated how accurately each model recognized the gestures. All approaches performed strongly, with the pose-based models correctly identifying most signs across 14–16 Qur’anic word classes. The random forest model, for example, achieved near-perfect scores for many words, with only a few confusions between visually similar gestures. The combined ResNet50-based model, which looks directly at the images while also benefiting from pose information, reached almost flawless performance on the test data: every gesture was classified correctly, and standard measures of accuracy, precision, recall, and a discrimination score called ROC–AUC all reached their maximum values. These results suggest that even relatively small image collections, when carefully prepared, can support highly accurate recognition of religious sign language.
Promise, Limits, and the Road Ahead
Although the performance numbers are impressive, the authors stress that they apply only to the controlled conditions of their study: a single chapter, a limited number of signers, and still images rather than continuous signing in motion. Real-world use would require larger, more varied datasets, better coverage of lower-body movements, and careful testing with signers from different regions. Nonetheless, the work shows that modern vision and learning tools can reliably recognize Qur’anic signs and provide instant feedback, for example by showing a check mark or a corrective animation when a learner performs a gesture. In everyday terms, this means that a deaf student could practice Qur’anic verses in sign before a simple camera and receive guidance without needing a live interpreter—an important step toward making sacred knowledge more accessible to all.
Citation: AbdElghfar, H., Youness, H.A., Wahba, M. et al. An automated framework for qur’anic education of the hearing-impaired using body pose classification and Arabic sign language integration. Sci Rep 16, 5939 (2026). https://doi.org/10.1038/s41598-026-36578-z
Keywords: Qur’anic education, Arabic Sign Language, hearing-impaired learners, pose recognition, assistive technology