Clear Sky Science · en
A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification
Why smarter eyes in the sky matter
Aerial photos from drones and satellites now guide disaster response, city planning, farming, and even traffic control. But teaching computers to understand these complex, cluttered views from above is still hard. This study presents two new artificial intelligence models that combine different ways of “seeing” images to recognize ten types of objects in drone photos—such as buildings, cars, trees, and roads—with better accuracy than previous methods. Their approach could make automated monitoring from the air faster, more reliable, and easier to deploy in real-world settings.
Challenges of looking down on the world
Aerial images differ from everyday photos we take on our phones. Objects are smaller, can appear at odd angles, and are often packed close together. A car partly hidden by a tree, a narrow footpath, or piles of debris after a landslide may be difficult even for humans to spot quickly. Yet governments, emergency teams, and environmental agencies increasingly rely on drone and satellite views to track floods, wildfires, urban growth, and infrastructure damage. With thousands of satellites in orbit and a booming aerial imaging market, the volume of data is growing too fast for people to inspect manually, pushing the need for more accurate and efficient automated classification.
Blending two ways machines learn to see
Most successful image-recognition systems today rely on deep learning. One family, convolutional neural networks, excels at picking out local patterns such as edges, textures, and small shapes. Another, newer family called vision transformers treats an image like a sequence of patches and is especially good at capturing long-range relationships, for example how a road, a cluster of roofs, and a nearby open field fit together in a scene. This work combines both: a well-known convolutional model called ResNet-50 and a vision transformer. Each processes the same aerial image and extracts its own set of numerical features—compact summaries of what the network has learned about the scene. These two streams of information are then joined and passed into an “attention” module that learns which features matter most for deciding among the ten target classes.
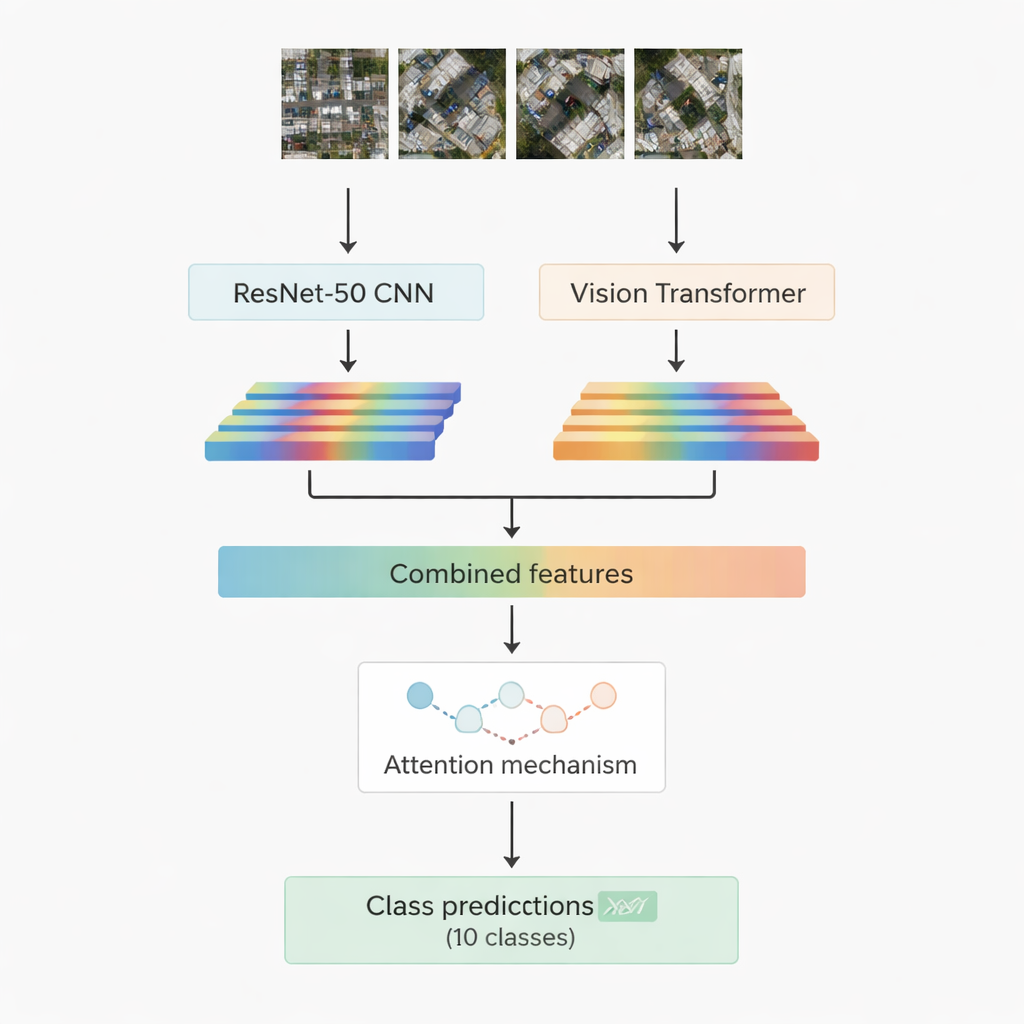
Two attention strategies to focus on what counts
The researchers design and test two versions of their hybrid system. In the first, they simply join the features from ResNet-50 and the transformer and feed them into a multi-head attention module. This mechanism can be thought of as many small spotlights that each look at the features from a slightly different angle, then combine their findings. In the second version, they use cross-attention: the features from the convolutional network act as a query that asks the transformer features where to look, allowing one stream to guide the other. In both cases, the attention output is passed through standard layers that finally assign the image patch to one of ten classes, including buildings, cars, debris, footpaths, metal roads, open fields, shadows, tanks, trees, and roofs.
Testing on real-world drone images
To judge how well their models work, the authors use a public dataset from the Indian state of Sikkim, collected by a drone flying 60 to 120 meters above ground. The data cover rivers, forests, hills, and built-up areas, sliced into small patches so that each image falls into one of the ten categories. The dataset is balanced, with an equal number of training and testing images per class, making it a fair test bed. The researchers train both hybrid models under identical conditions and then compare their performance using widely used measures: accuracy, precision, recall, F1-score, confusion matrices, and ROC curves. They also benchmark their results against several well-known networks and newer transformer-based methods from recent literature.

Sharper classification and real-world potential
Both hybrid models outperform earlier systems on this dataset, reaching overall accuracies of 95.52% and 95.80%, with the multi-head attention version slightly in the lead. Their performance remains strong and stable across all ten object types, and detailed analyses show that even the weaker classes are still recognized at high rates. This suggests that mixing convolutional networks, vision transformers, and attention mechanisms is a powerful recipe for understanding complex aerial scenes. For a lay reader, the bottom line is that computers are getting much better at answering questions like “Where are the roads?” or “Which patches show debris or buildings?” in huge collections of drone images. As such models are refined and extended to new datasets, they could underpin smarter disaster response, environmental monitoring, and smart-city services that rely on fast, reliable interpretation of images from above.
Citation: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Keywords: aerial image classification, drone imagery, deep learning, vision transformer, remote sensing