Clear Sky Science · en
Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals
Smarter Online Training for Working Tech Pros
For many information technology (IT) professionals, online courses are now the main way to keep skills current. But most training platforms still grade people with blunt tools like quiz totals or completion badges. This study presents a smarter way to read the digital “footprints” learners leave behind and turn them into precise, real‑time insights about how well each person is truly learning.
Why One-Size-Fits-All Online Courses Fall Short
Conventional e-learning treats most learners the same: everyone sees the same modules, takes the same quizzes, and is judged using the same fixed tests. That approach ignores how differently professionals progress, especially in fast-moving fields like cybersecurity or cloud computing. Earlier research tried to fix this with machine learning—combining quiz scores, time spent, and click data to predict success—but many models struggled with noisy or incomplete data, could not scale to realistic platforms, or failed to track how learning unfolds over weeks and months. The result was often delayed, coarse feedback that could not easily guide tailored content or timely intervention.
Turning Raw Course Logs into Clean, Fair Data
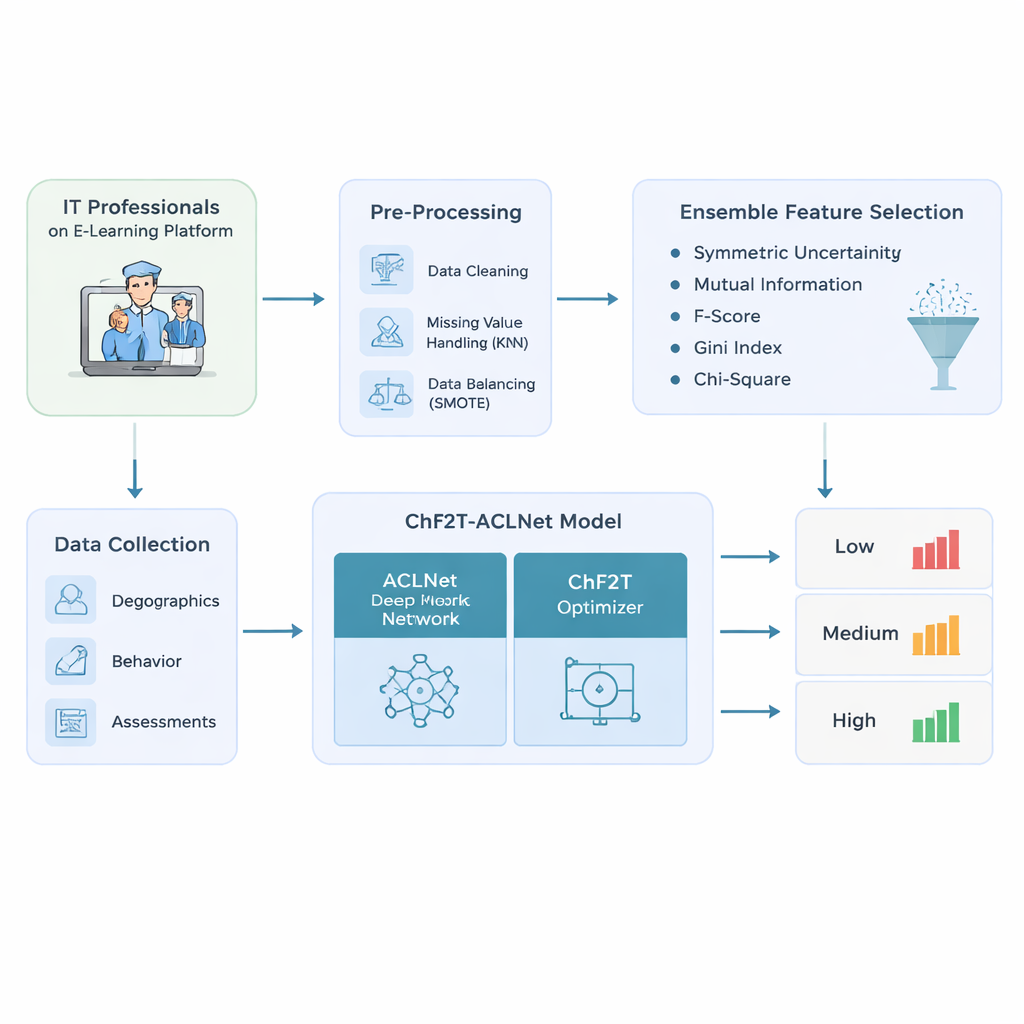
The authors begin by designing a careful data pipeline for IT professionals using adaptive e-learning platforms. They gather a rich mix of information: basic profile details such as age and job role; behavioral traces like time spent, access dates, and active days; and performance indicators including quiz scores, attempts, certificates, and feedback ratings. Before any modeling, they scrub the data—removing duplicate records, estimating missing values by looking at similar learners, and correcting skewed class distributions so that low, medium, and high performers are represented more fairly. This balancing step avoids models that are overly confident only for the most common “average” learners and blind to those who struggle or excel.
Selecting Only the Most Telling Signals
From the cleaned dataset, the system does not simply feed every available column into a black box. Instead, it uses an ensemble of five simple ranking methods to decide which features really matter for predicting learning outcomes. Each method examines the connection between a candidate feature—such as quiz attempts or time spent—and the final performance label. By combining their rankings using a median score, the approach filters out noisy or redundant signals and keeps only the most informative ones. This not only reduces the amount of computation the later model needs, but also helps it focus on patterns that meaningfully distinguish low, medium, and high achievers.
A Hybrid Network Trained Like a Sports Team
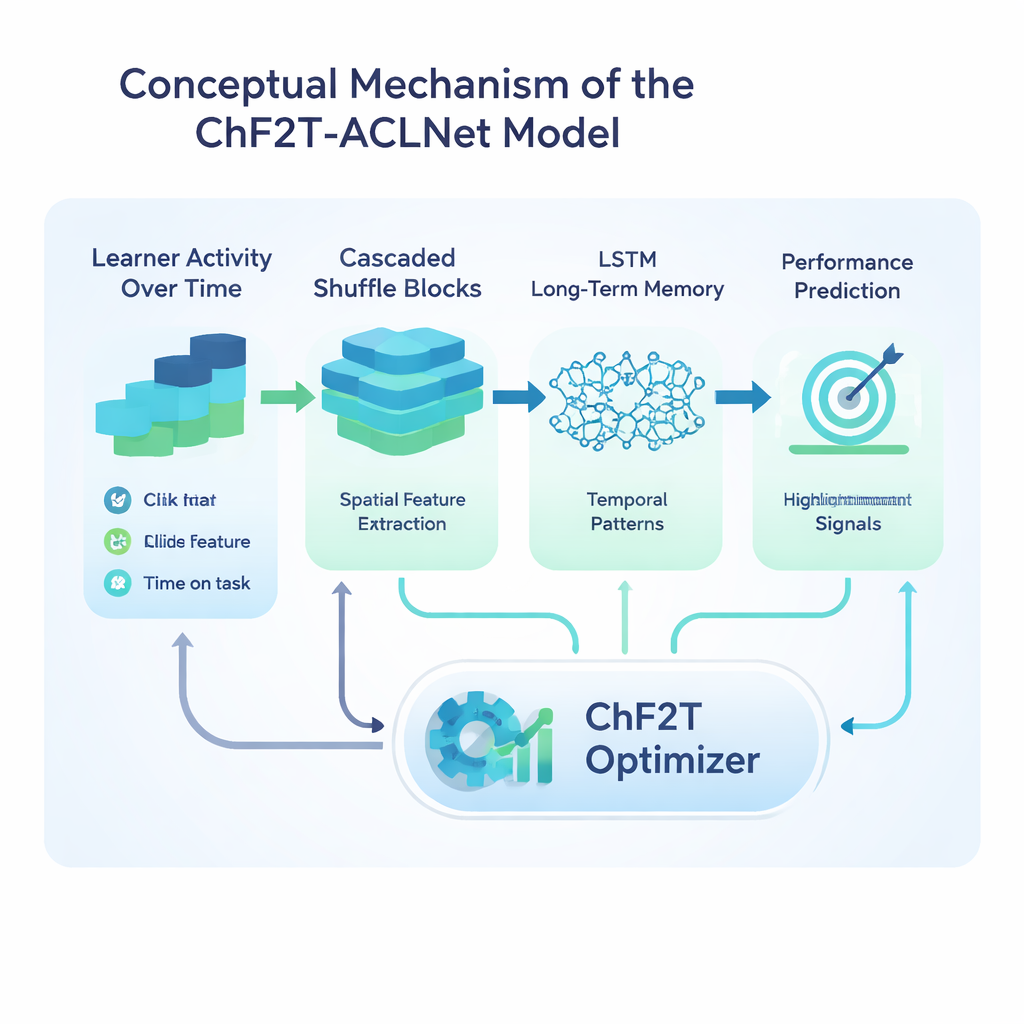
The heart of the study is a hybrid deep learning model called ACLNet, paired with an unconventional training strategy inspired by team sports. ACLNet first uses lightweight “shuffle” blocks to compress and mix input signals efficiently, then passes them into a memory module that traces how a learner’s behavior changes over time. An attention layer on top highlights the most influential channels—such as sudden drops in activity or consistently high quiz scores—before making a final prediction of the learner’s performance class. To tune this network’s many internal settings, the authors introduce a Chaotic Football Team Training (ChF2T) algorithm. Here, virtual “players” explore different parameter settings, imitating strong performers, avoiding weak ones, and occasionally making large, chaotic jumps that help the search escape poor local choices. This blend of structure and controlled randomness speeds convergence and reduces overfitting.
How Well the System Performs in Practice
The researchers test their pipeline on a synthetic yet realistic dataset of 1,200 IT professionals, built to mirror real learning management system records with deliberately uneven class distributions. They compare their ChF2T‑ACLNet model against several strong baselines, including federated learning setups, advanced image-style networks adapted to education, and other deep or ensemble models. Across multiple cross‑validation setups, the proposed method reaches about 98.9% accuracy, with similarly high precision, recall, and F‑scores. It also achieves a near-perfect agreement score that corrects for chance and delivers strong area-under-curve values, meaning it separates performance levels reliably over many thresholds. Despite its complexity, the system runs faster than competing approaches, thanks to careful feature selection, an efficient network design, and the optimizer’s quick convergence.
What This Means for Everyday Online Learning
In plain terms, this work shows that it is possible to watch how professionals move through online courses and infer, with high confidence, who is struggling, who is coasting, and who is mastering the material—without waiting for a final exam. Such a system could trigger early hints, recommend different exercises, or alert mentors long before a learner falls behind. The authors note remaining challenges, including scaling to very large platforms, adapting to fast-changing course designs, and making the model’s decisions easier to explain. Still, their approach is a strong step toward e-learning systems that act more like attentive personal coaches than static digital textbooks.
Citation: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Keywords: adaptive e-learning, learning analytics, deep learning, IT professional training, student performance prediction