Clear Sky Science · en
Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm
Why blood clots and data privacy matter
Blood clots that form deep in the veins of the legs, known as deep vein thrombosis (DVT), can silently travel to the lungs and cause life‑threatening emergencies. CT scans can reveal these clots, but turning thousands of gray‑scale images into reliable, automatic detections is a difficult task for computers. At the same time, hospitals are rightly cautious about sharing sensitive patient data. This study explores how multiple hospitals can team up to train a powerful clot‑finding artificial intelligence (AI) system—without ever pooling or exposing their raw patient scans.
Sharing brains, not bodies
The heart of the work is a technique called federated learning, which lets several institutions train AI models collaboratively while keeping their data on‑site. Instead of sending CT images to a central server, each hospital trains its own local model on its own scans. Only the model’s learned parameters—essentially what it has "figured out" about recognizing clots—are sent to a central server. There, an approach called federated averaging combines these different sets of parameters into a single, improved global model, which is then sent back to all hospitals. In this way, every site benefits from the collective experience of all participants, while no patient image ever leaves its home institution. 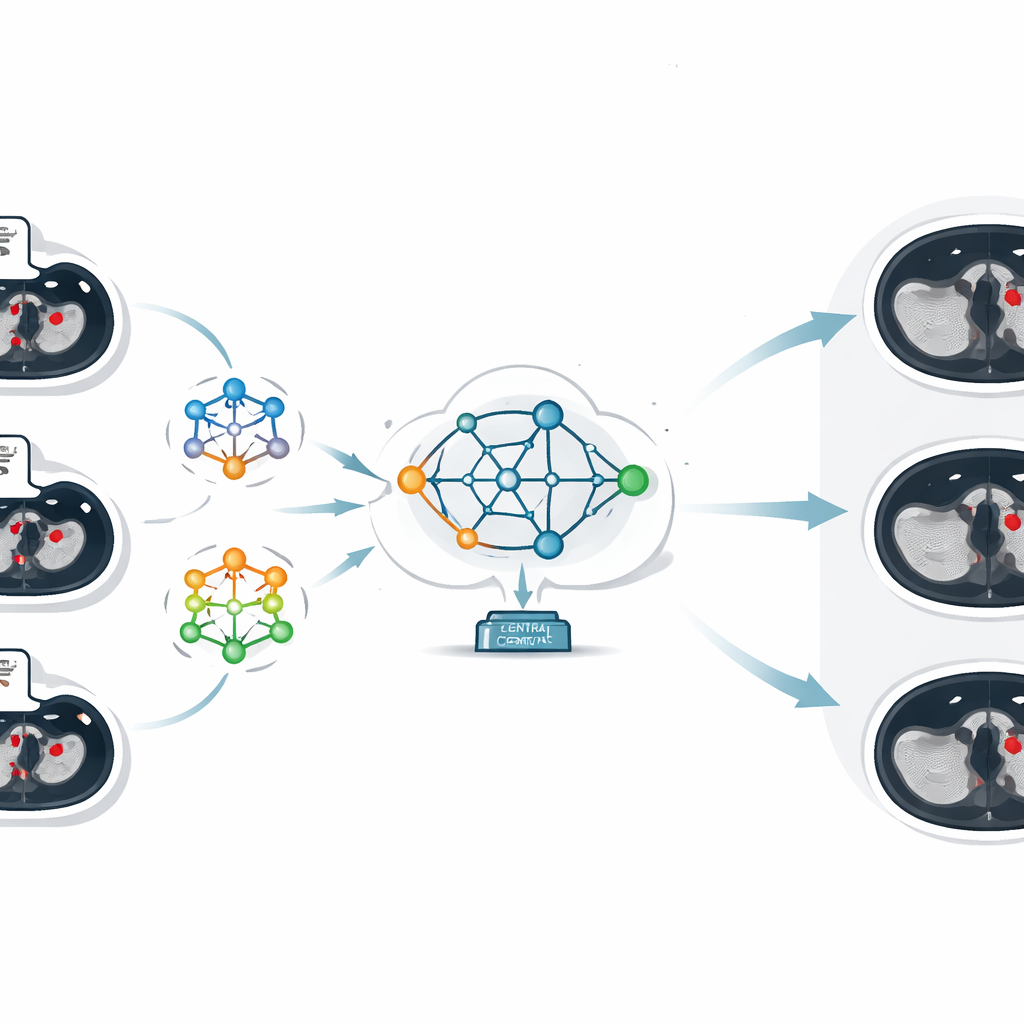
Many styles of AI looking at the same veins
A key innovation in this study is that the researchers did not rely on just one type of neural network. They assembled seven different model designs, each good at seeing different aspects of the CT images. Simpler models, such as basic convolutional networks and sequential models, are faster and easier to run on limited hardware. More advanced architectures, including U‑Net, VGG‑19, and two customized networks with residual, inception, attention, and multi‑scale processing blocks, are better at tracing fine vessel boundaries, spotting small clots, and coping with noisy images. By allowing each hospital to use the model that best matches its data and computing power, the system mirrors the messy reality of real‑world clinical environments rather than assuming every site looks the same.
Learning from uneven and imperfect data
In medicine, data from one hospital rarely looks exactly like data from another. Scanners, imaging protocols, and patient populations differ, so the study deliberately worked with "non‑IID" data—collections that are uneven and not identically distributed. This normally makes training more unstable. Here, the authors embraced that diversity and showed that pooling knowledge across multiple, differently structured models actually improved the global system’s ability to generalize. They ran three experimental phases, first with three clients, then five, and finally seven, using datasets of 1,000, 2,000, and 3,000 CT images. At each step, they tracked not just how often the global model correctly segmented clots, but also how much communication was needed, how long training took, how different each client’s data was, and how well privacy protections held up.
Better clot detection, at a computational price
Across all phases, the combined global model consistently outperformed any single local model. As the number of images grew and more sophisticated models joined the federation, segmentation accuracy rose from about 91% to over 96%, and a balanced quality measure called the F1‑score climbed from roughly 0.89 to 0.95. At the same time, an error‑focused loss measure fell by more than half, signaling cleaner, more reliable clot outlines. These gains did not come for free: communication between clients and server swelled from a few tens of megabytes to several gigabytes, and average training time increased from seconds to many hours as the architecture matured. Nonetheless, the system maintained a strong formal privacy guarantee, indicating that the shared updates leak very little information about any individual patient. 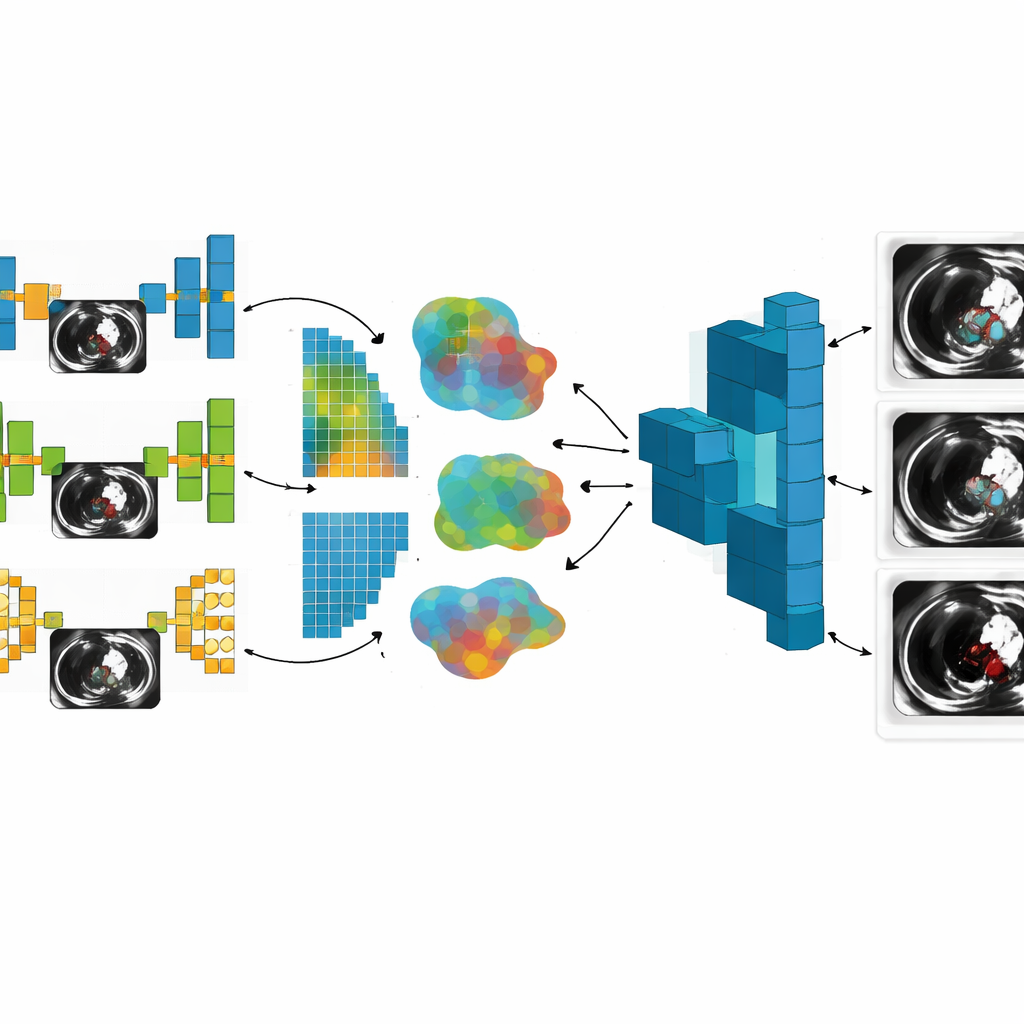
What this means for patients and hospitals
To a layperson, the bottom line is that this work shows how hospitals can teach a shared AI to spot dangerous blood clots more accurately, without surrendering control of their sensitive data. By blending several complementary model designs and carefully aggregating what each one learns, the authors build a clot‑segmentation system that is both powerful and respectful of privacy. Although the approach requires substantial computing resources and network bandwidth, it points toward a future in which medical centers routinely collaborate on smarter diagnostic tools, improving care for patients at risk of DVT and related conditions while keeping their personal scans safely behind institutional walls.
Citation: B, P.L., S, V. Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm. Sci Rep 16, 11333 (2026). https://doi.org/10.1038/s41598-026-36432-2
Keywords: deep vein thrombosis, federated learning, medical image segmentation, privacy-preserving AI, CT imaging