Clear Sky Science · en
A short text entity disambiguation method based on BERT model and shortest path algorithm
Why Sorting Out Confusing Names Matters
Every day, we search, scroll, and chat using short, often messy snippets of text—tweets, search queries, chat messages. These snippets are filled with names of people, places, companies and things that can mean more than one thing, like “Apple” the fruit or “Apple” the company. Computers have to guess which meaning we intend, and when they guess wrong, search results, recommendations and online services become much less useful. This paper presents a new way to help machines correctly interpret such ambiguous names in short texts, especially in Chinese social media and search, by combining modern language models with a clever graph algorithm.
From Messy Short Texts to Clear Targets
Short texts are surprisingly hard for computers to understand. Unlike long articles, they contain very little context and are packed with slang, abbreviations and incomplete sentences. Traditional methods tried to match a name in the text to entries in a knowledge base, or used hand‑crafted rules and simpler machine‑learning models. These approaches often treat each word as having a single fixed meaning, which fails badly when the same word can represent a job title, a company, or a song, depending on how it is used. The result is frequent confusion over which real‑world entity a word in a tweet or query actually refers to.
Teaching the System to Spot Ambiguous Names
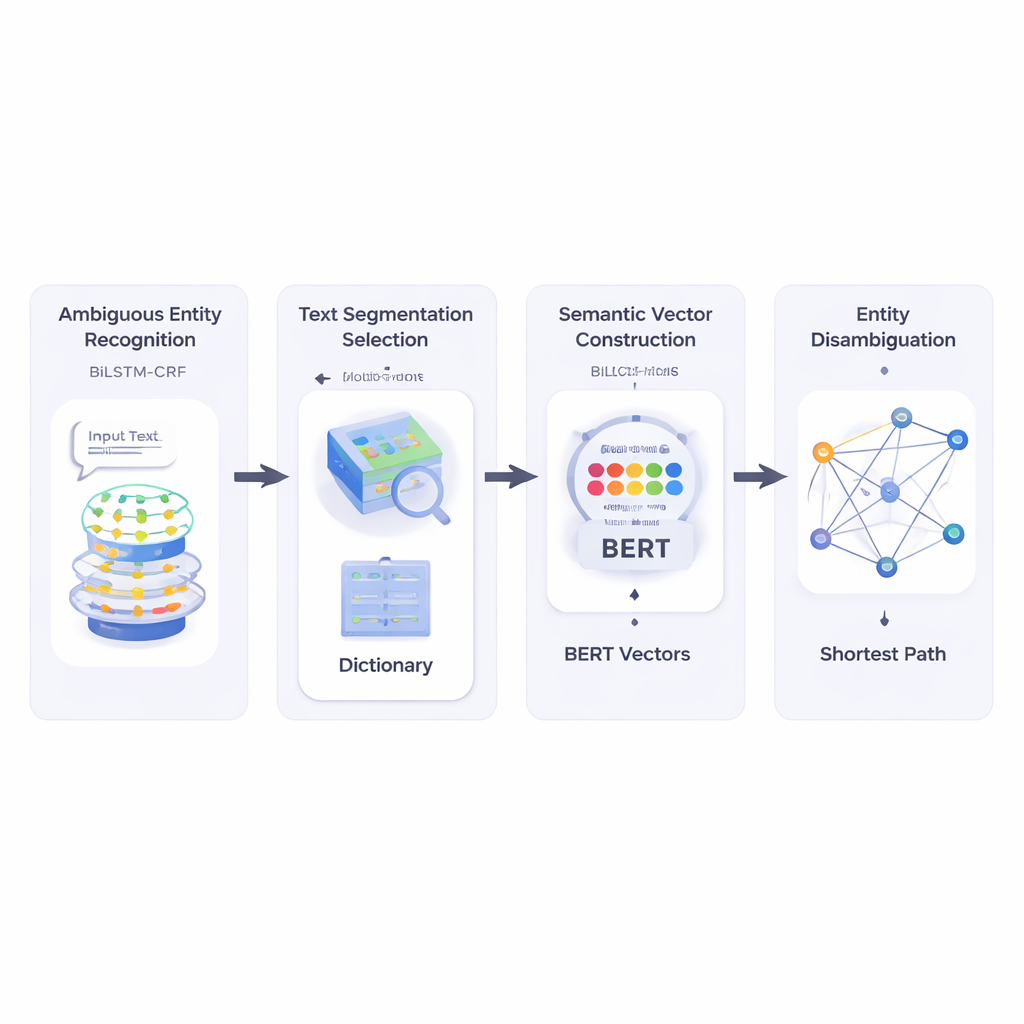
The authors first build a system that reads a short text and identifies which parts are entity names and which of those might be ambiguous. They use a neural network combination called BiLSTM‑CRF, which is good at tagging sequences of words by looking at both left and right context. Once potential entities are marked, the system consults a large lexical resource called HowNet. If HowNet lists several meanings for a word, that word is flagged as ambiguous; if there is only one meaning, the word is treated as already clear. This step gives the system a focused list of names that truly need disambiguation.
Turning Meanings Into Points in Space
Next, the method breaks the short text into candidate word segments and chooses the best segmentation by checking how well each possible cut aligns, in meaning, with clearly understood reference words in the same sentence. To measure this, the authors rely on BERT, a powerful pre‑trained language model that produces a numerical “semantic vector” for each word usage, capturing its context‑dependent meaning. By computing cosine similarity between these vectors, the system finds the segmentation whose pieces are most semantically compatible with the unambiguous reference terms. This allows the model to represent each possible sense of each word as a point in a multi‑dimensional space.
Finding the Shortest Route to the Right Meaning
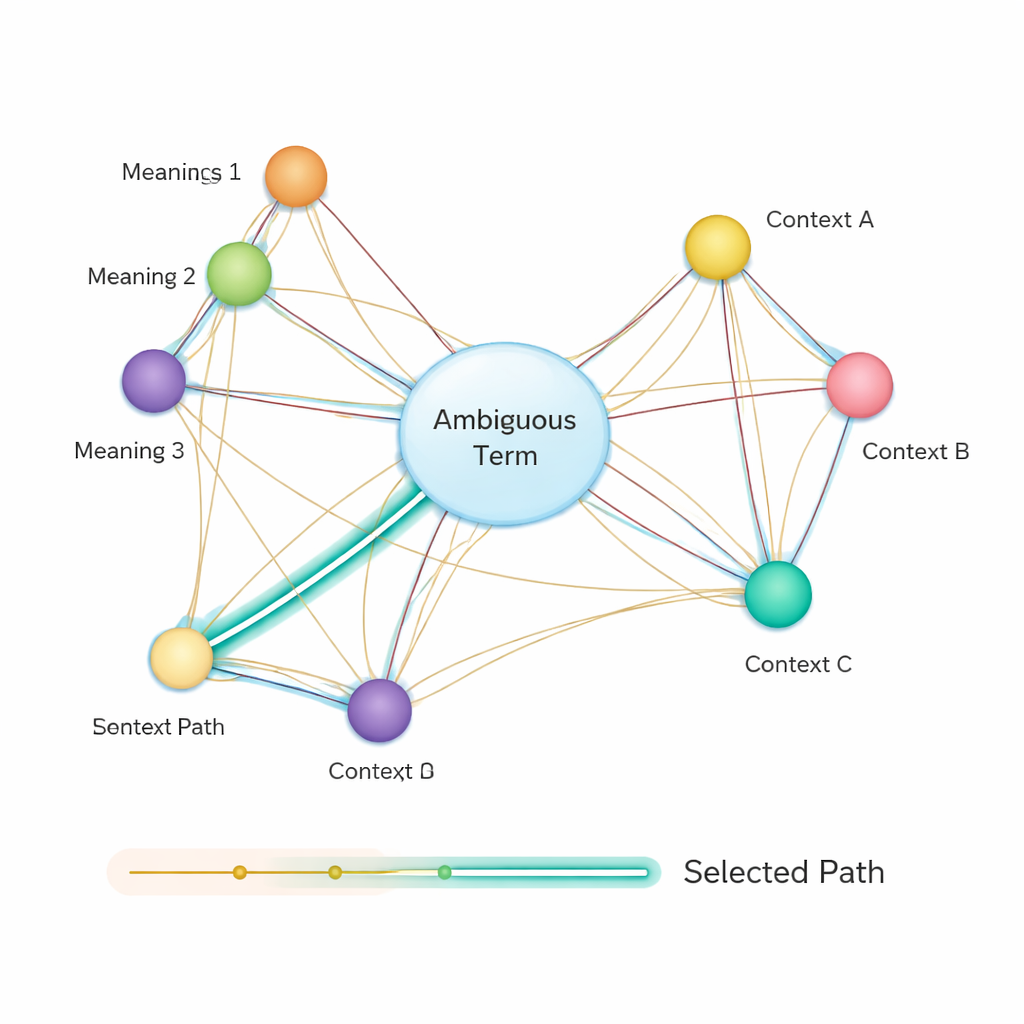
After that, the method builds a semantic network: a graph where each possible meaning of each term is a node, and edges connect meanings that might co‑occur in the same sentence. The strength of each edge is based on how similar the meanings are, again using BERT‑based vectors. To decide which sense of an ambiguous word best fits the sentence, the authors apply a classic algorithm known as Dijkstra’s shortest path algorithm. Intuitively, the system looks for the path through this meaning graph that keeps the overall semantic “distance” as small as possible. The chosen path corresponds to a consistent interpretation of all terms, and the sense of the ambiguous entity that lies on this path is selected as the final answer.
How Much Better Does This Work?
The researchers tested their method on a public Chinese dataset from the CLUE benchmark, which simulates real short‑text scenarios such as social media posts and queries. They compared four approaches: versions using traditional Word2Vec embeddings, the ELMo language model, a BERT‑based system without the shortest‑path step, and their full BiLSTM‑CRF‑BERT‑SPA pipeline. Across thousands of texts, their complete method improved accuracy, recall and F1 score by roughly one quarter on average compared with the others. In practical terms, the system was both better at spotting the correct entities and at doing so consistently across many different data sizes.
What This Means for Everyday Technology
For non‑specialists, the takeaway is straightforward: by combining a powerful language understanding model (BERT) with a graph‑based shortest‑path search, the authors give computers a more reliable way to decide what an ambiguous name really refers to in short, noisy texts. This can make search engines smarter, help social platforms better understand posts, and improve downstream tools like recommendation systems and knowledge graphs. While the method is currently geared toward Chinese and still has room for efficiency improvements, it showcases how blending modern AI with classic algorithms can sharply reduce confusion in how machines interpret our everyday language.
Citation: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Keywords: entity disambiguation, short text, BERT, knowledge graph, natural language processing