Clear Sky Science · en
Content style decoupling for multi style image generation using latent diffusion architecture
Why smarter image styles matter
From movie posters and game art to social media filters, we increasingly expect images to be both visually striking and highly personalized. But behind the scenes, many style-transfer systems still struggle: they may warp a person’s face, bend buildings out of shape, or require heavy hardware. This paper introduces a new AI model that promises richer artistic styles while keeping the original picture intact and running efficiently enough for everyday devices.
Separating “what it is” from “how it looks”
At the heart of this work is a model called the Dual-Condition Lightweight Style Diffusion Model (DCLSDM). Its key idea is to treat the substance of an image—the objects, layout, and scene—as one “channel,” and the artistic treatment—colors, textures, brushstrokes—as another, and to control them separately. Instead of letting a single network muddle these two aspects together, DCLSDM uses two dedicated pathways: one for content and one for style. The content path focuses on understanding shapes and meanings in an input image or text description, while the style path focuses on learning the visual character of a chosen artwork or style description.
How the new model is built
DCLSDM builds on diffusion models, the same family of techniques behind many modern image generators. Rather than working directly on full-resolution pictures, it operates in a compressed “latent” space, which is far more efficient. A module called Perceiver IO extracts the content: it takes in an image or caption and distills the scene’s geometry and semantics into a compact representation. A separate style module reads one or more style images or texts and converts them into style feature vectors. These style features can be blended with a weighted interpolation scheme, allowing smooth transitions between, say, an impressionist and a minimalist look without the usual “muddy” average.
Keeping structure while changing style
Inside the diffusion network that actually generates the image, the two kinds of information are injected through independent routes. Content signals guide the network layers that care about structure—where edges, objects, and layouts should go. Style signals are injected through dedicated attention layers that mainly shape textures, colors, and brushwork. On top of this, a component called ControlNet adds extra structural guidance using edge or depth maps extracted from the original content. This combination means the system can repaint a summer landscape in a winter palette, or render a photograph as a Van Gogh–like painting, while still keeping mountains, trees, and buildings in the right place and free of distortion.
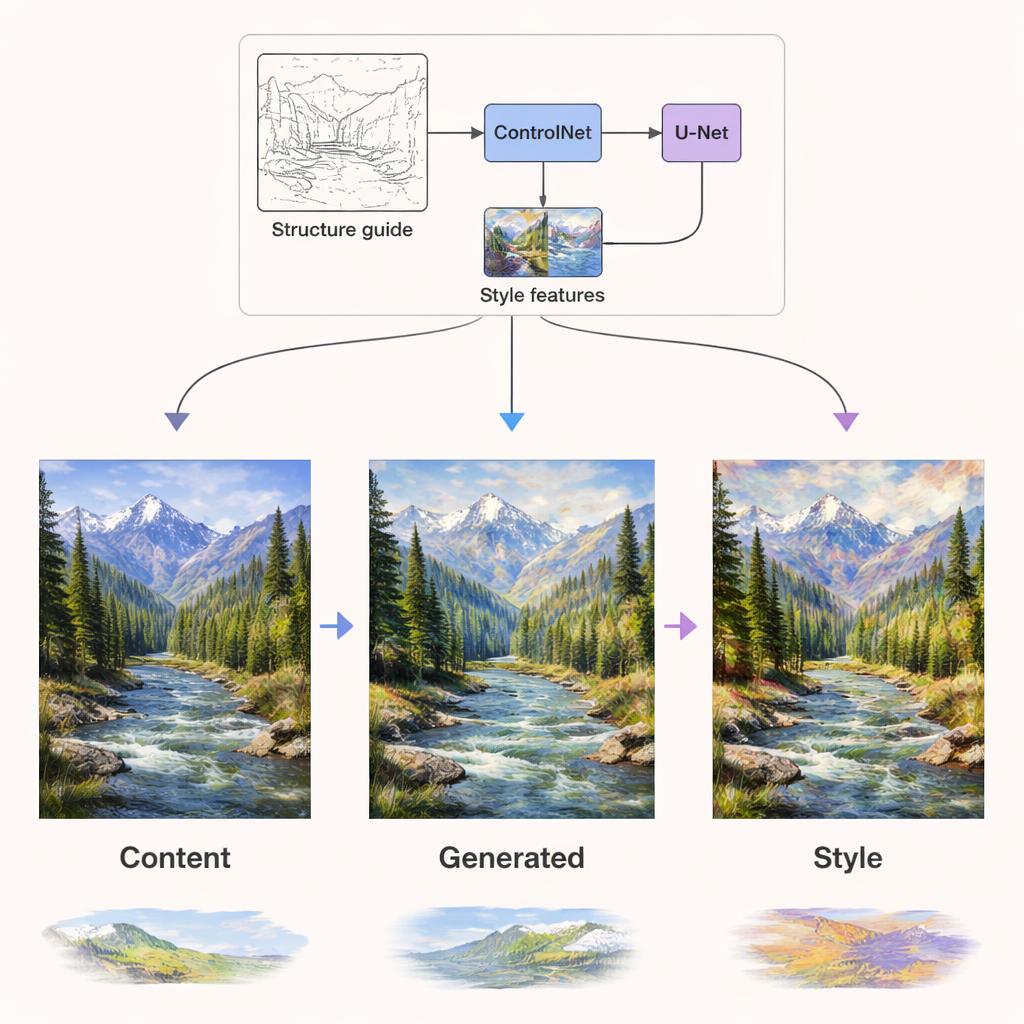
Better quality, more styles, less compute
The authors rigorously test DCLSDM on two public datasets: WikiArt, which covers dozens of art movements, and Summer2Winter Yosemite, which focuses on seasonal changes in a landscape. They compare their model against a range of state-of-the-art systems used in both research and industry. Across measures of structural similarity, perceived visual quality, and how closely the generated images resemble real artworks, DCLSDM consistently scores highest. It also runs faster, uses less memory, and has fewer parameters than many competitors, yet still offers flexible mixing of multiple styles and supports both image-based and text-based style input.
What this means for everyday creativity
In practical terms, this work shows that it is possible to give users fine-grained control over how an image looks without sacrificing what the image shows—and to do so on more modest hardware. Designers could quickly explore many artistic treatments of the same layout, mobile apps could offer richer filters that do not deform faces or scenes, and cultural-heritage projects could restyle old photos while preserving crucial structural details. By cleanly separating content from style within a modern diffusion framework, DCLSDM points toward a future where creative image tools are both more powerful and more reliable for everyday use.
Citation: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
Keywords: image style transfer, diffusion models, content-style decoupling, digital art generation, efficient image generation