Clear Sky Science · en
Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach
Smarter tests for the digital classroom
Anyone who has sat through a long, one‑size‑fits‑all exam knows how dull and unfair it can feel. Some questions are far too easy, others impossibly hard, and the final score may not really capture what you know. This paper presents a new way to build computer‑based tests that adapt, in real time, to each person’s answers. By borrowing ideas from modern artificial intelligence, the authors aim to make exams shorter, more accurate, and better matched to every test‑taker’s true ability.
Why fixed tests fall short
Traditional exams give every student the same collection of questions. That makes test creation simple, but it wastes information: strong students slog through many easy items, while struggling students are quickly overwhelmed. Computerized adaptive testing tries to fix this by choosing each next question based on previous answers, but most current systems still rely on decades‑old statistical models and hand‑crafted rules. These older approaches have trouble capturing complex answer patterns and often cannot fully account for the wide differences among learners in modern, large‑scale online settings.
Bringing modern AI into testing
The authors propose a new framework that combines deep learning and reinforcement learning to guide adaptive exams from start to finish. The system operates in repeated cycles. First, a one‑dimensional convolutional neural network (1D‑CNN) analyzes a person’s recent answers, the difficulty of the questions, and other summary statistics. From this stream of data it produces a single number that represents the person’s current skill level on a normalized scale, similar to how traditional testing theories describe ability but learned directly from data. This network is trained to recognize subtle patterns such as consistent success on harder questions or unexpected mistakes on easier ones. 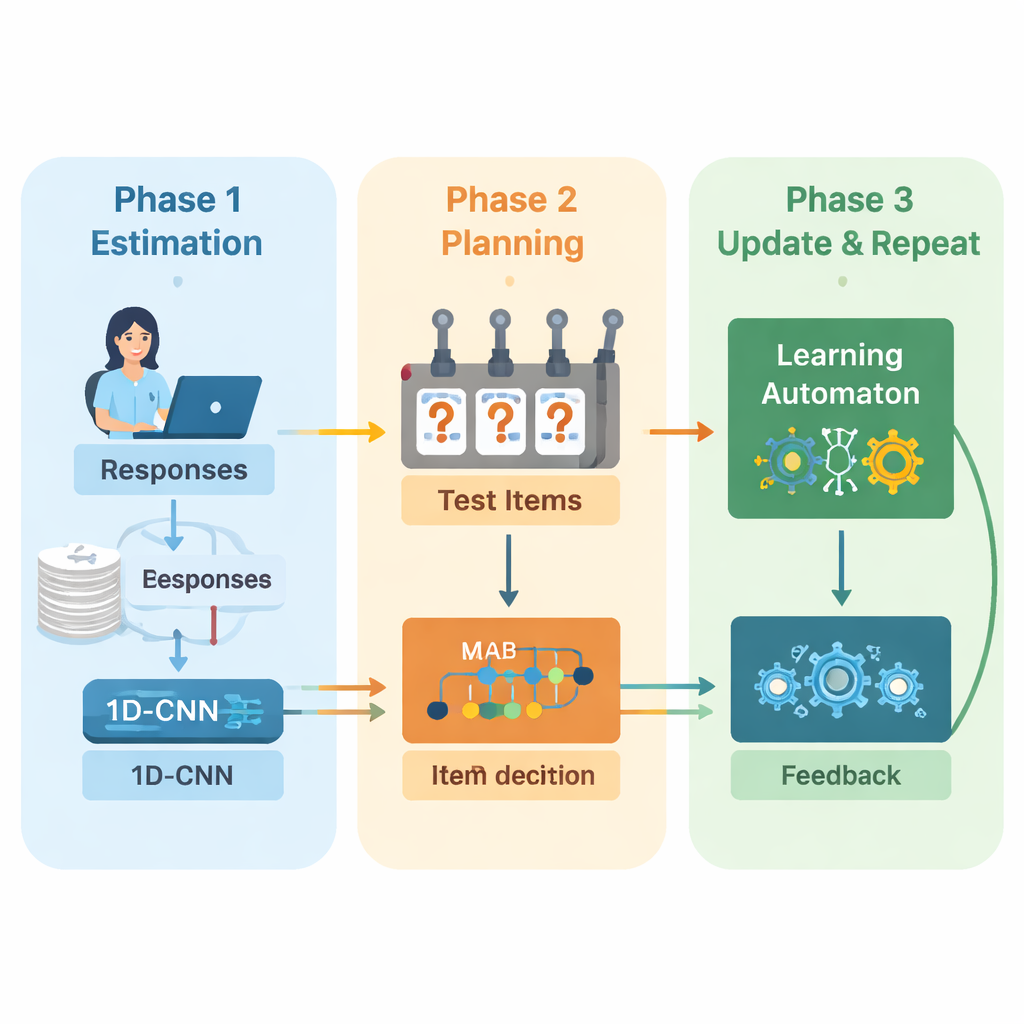
Choosing the right next question
Once the system has an updated sense of ability, it must decide what to ask next. Here the authors use a "multi‑armed bandit" strategy, a classic tool from decision theory where each possible action is treated like pulling a lever on a slot machine. In this context, every question in the item bank is an arm. The algorithm looks at questions whose difficulty roughly matches the current skill estimate and then chooses those that are expected to be most informative. It balances two goals: getting a good difficulty match, so answers are neither too easy nor too hard, and covering as many different content areas as possible, so the test does not ignore important topics. A reward score that mixes these two goals guides the selection process.
Learning from its own decisions
To keep improving as the test proceeds, the system adds another learning component called a learning automaton. This module watches how the estimated ability changes across rounds and whether the person’s accuracy is improving or declining. It adjusts a small set of probabilities that summarize whether the model expects ability to go up, stay the same, or go down. These probabilities are then fed back as extra input to the neural network in the next round. In this way the test engine not only learns about the student, it also learns about its own past decisions—rewarding trends that led to accurate estimates and penalizing trends that did not. 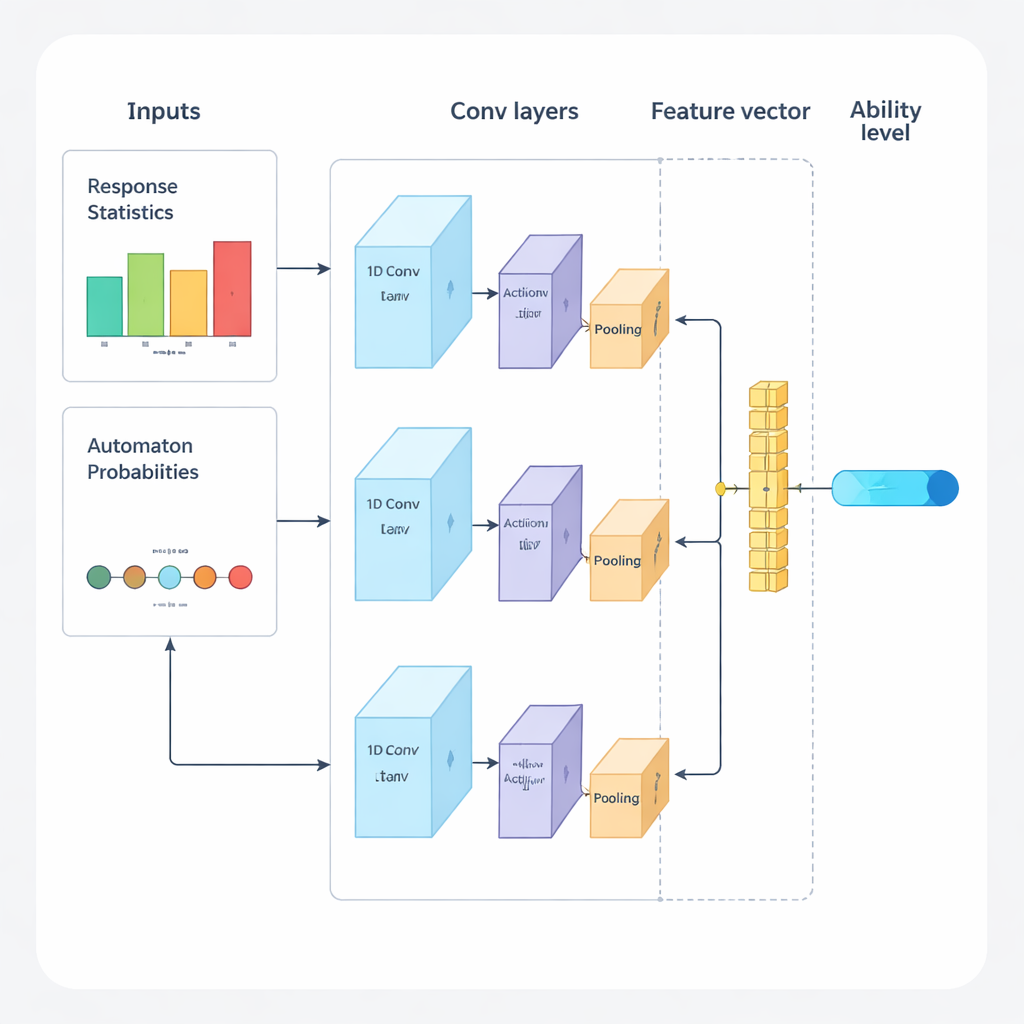
How well does it work in practice?
The researchers evaluated their framework using a large, multilingual exam dataset and thousands of simulated test‑takers whose true skill levels were known. They compared their approach with several leading adaptive testing methods. Across a range of error and correlation measures, the new system produced more accurate estimates of ability while requiring fewer questions. Its errors—measured by common statistics such as root mean squared error and mean absolute error—were clearly lower than those of competing methods. At the same time, it spread question use more evenly across the item bank, reducing the risk that certain questions would be over‑exposed and leaked.
What this means for future exams
In everyday terms, this work suggests that future computer‑based tests could feel more like a tailored tutoring session than a rigid exam. Questions would quickly zero in on the right difficulty for each person, explore the full range of topics that matter, and finish once the system is confident about your level—often in fewer items than today’s tests. While the method still depends on good training data and computing power, and has so far been tried on a single dataset, it points toward a new generation of smarter, fairer, and more efficient assessments that adapt naturally to individual learners.
Citation: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Keywords: computerized adaptive testing, educational assessment, deep learning, reinforcement learning, multi-armed bandit