Clear Sky Science · en
Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models
Why theme-park safety needs smarter reading
Every year, hundreds of millions of people climb into roller coasters, drop towers, and spinning rides, trusting that complex machines and busy operators will keep them safe. Behind the scenes, regulators and engineers produce huge volumes of reports, accident records, and public complaints—but most of this information sits in text form that is hard to sift through quickly. This study explores how advanced artificial intelligence can "read" these documents at scale, spot patterns of danger earlier, and give authorities a clearer picture of where amusement rides are most likely to fail.
From scattered reports to a unified risk picture
China now hosts more than 25,000 large amusement rides and over 700 million visitors a year. Despite overall improvements in safety, rare but serious accidents still occur, often after inspections have failed to notice early warning signs buried in technical descriptions or user complaints. The authors argue that traditional supervision—based on periodic manual checks, expert judgment, and maintenance logs—is too slow and subjective for such a fast-moving environment. They assemble a large, real-world text collection that includes accident reports, laws and standards, inspection and maintenance records, and online complaints related to amusement facilities. After careful cleaning and filtering, this multi-source corpus becomes the raw material for an automated, data-driven risk monitoring system. 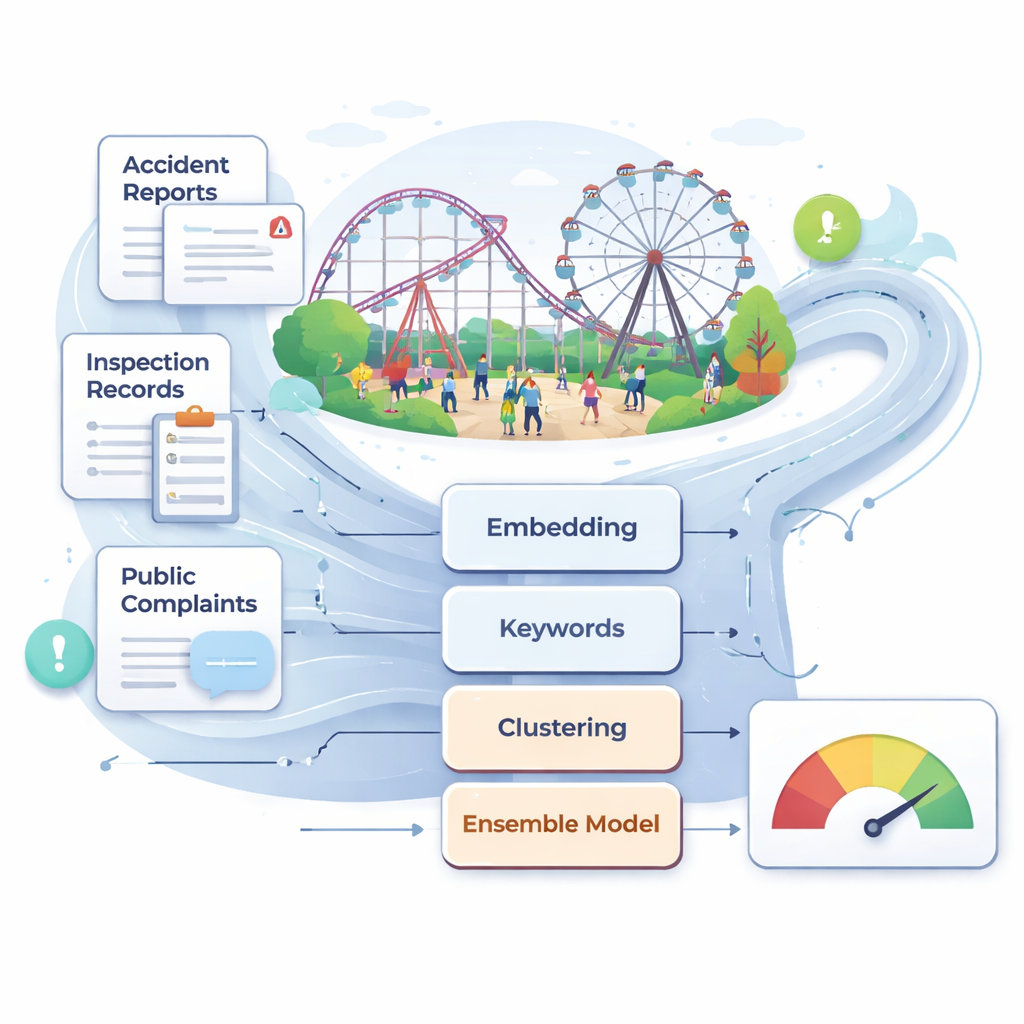
Teaching computers to understand risk language
To make sense of this messy text, the researchers rely on modern language models that convert sentences into numerical vectors capturing their meaning. They primarily use a Chinese model called BGE, which represents each piece of text as a 1,024-dimensional point in space, plus a compact set of 30 keyword-based features focused on terms like “maintenance,” “inspection,” and “rectification.” This dual view—deep semantic context plus hand-curated risk phrases—helps the system distinguish subtle differences between, for example, routine checks and serious faults. The team also experiments with another state-of-the-art embedding model, Qwen3, to test whether changing the language backbone improves performance; in practice, BGE proves slightly better on this safety task.
Finding hidden patterns and key weak spots
Before classifying texts into concrete risk categories, the authors use unsupervised methods to uncover natural groupings. They apply k-means clustering to the embeddings and use a visualization method called UMAP to show that reports fall into several clear topic clusters. They then build a semantic graph in which each node is a safety-related keyword and links indicate strong co-occurrence and semantic similarity. A community-detection algorithm groups these nodes into clusters corresponding to broad themes such as equipment and structural safety, daily operation and maintenance, emergency response, and management and supervision. Within this network, certain words—like “maintenance,” “inspection,” and “responsibility”—act as bridges between clusters, highlighting cross-cutting weaknesses that can trigger accidents in multiple ways. From this structure they extract 31 core risk factors spanning four main dimensions, from real-time monitoring of equipment to clarity of job responsibilities. 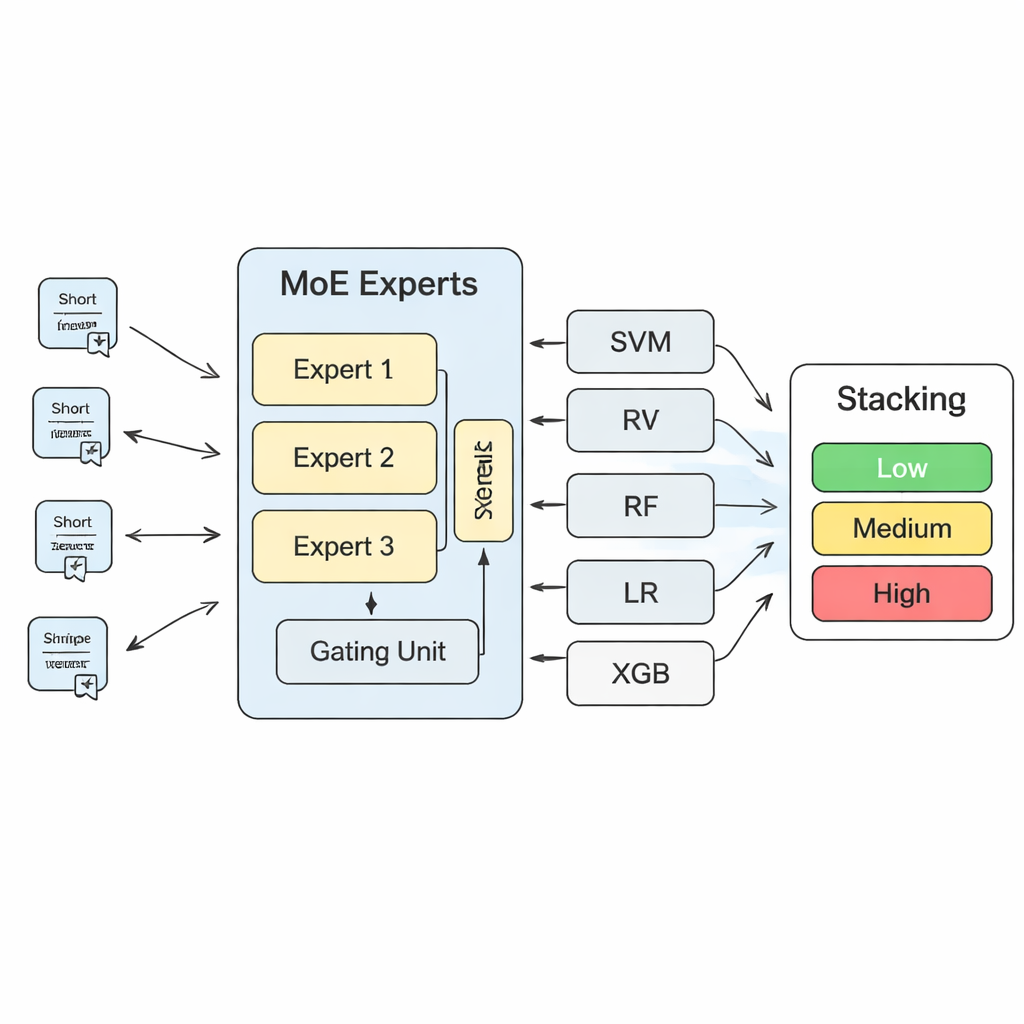
Blending many models into one stronger safety judge
To turn these insights into concrete risk predictions, the study builds a layered machine-learning system. At its heart is a “mixture of experts” (MoE) model: several neural networks, or experts, each learn to specialize in different kinds of risk patterns, while a gating component decides which experts to trust most for each new text. The outputs of this MoE model are then combined with the predictions of more traditional algorithms, such as support vector machines, random forests, logistic regression, and gradient-boosted trees. A final “Stacking” layer—another machine-learning model—learns how to weight all of these opinions to reach a final decision. Through extensive cross-validation, the authors find that using three experts in the MoE layer strikes the best balance between model capacity and stability.
What the gains mean for real-world supervision
Compared with any single model, the MoE-plus-Stacking system substantially improves accuracy, precision, recall, and a reliability measure called LogLoss. In practical terms, this means fewer missed warnings and fewer false alarms when screening large volumes of safety text. The model can run on an ordinary workstation and deliver rapid risk assessments for new inspection reports or complaints, making it suitable as a decision-support tool rather than a replacement for human judgment. The authors stress that their approach could be adapted beyond amusement rides to other special equipment such as elevators or cable cars. For lay readers, the key takeaway is that by teaching computers to read the language of safety—across technical documents, regulations, and everyday complaints—regulators can detect patterns of danger earlier, target inspections more intelligently, and make a day at the park a little safer for everyone.
Citation: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Keywords: amusement ride safety, risk text analysis, machine learning, mixture of experts, public safety monitoring