Clear Sky Science · en
Deep inception neural network with residual connections for Tamil handwritten character recognition
Saving handwriting in the digital age
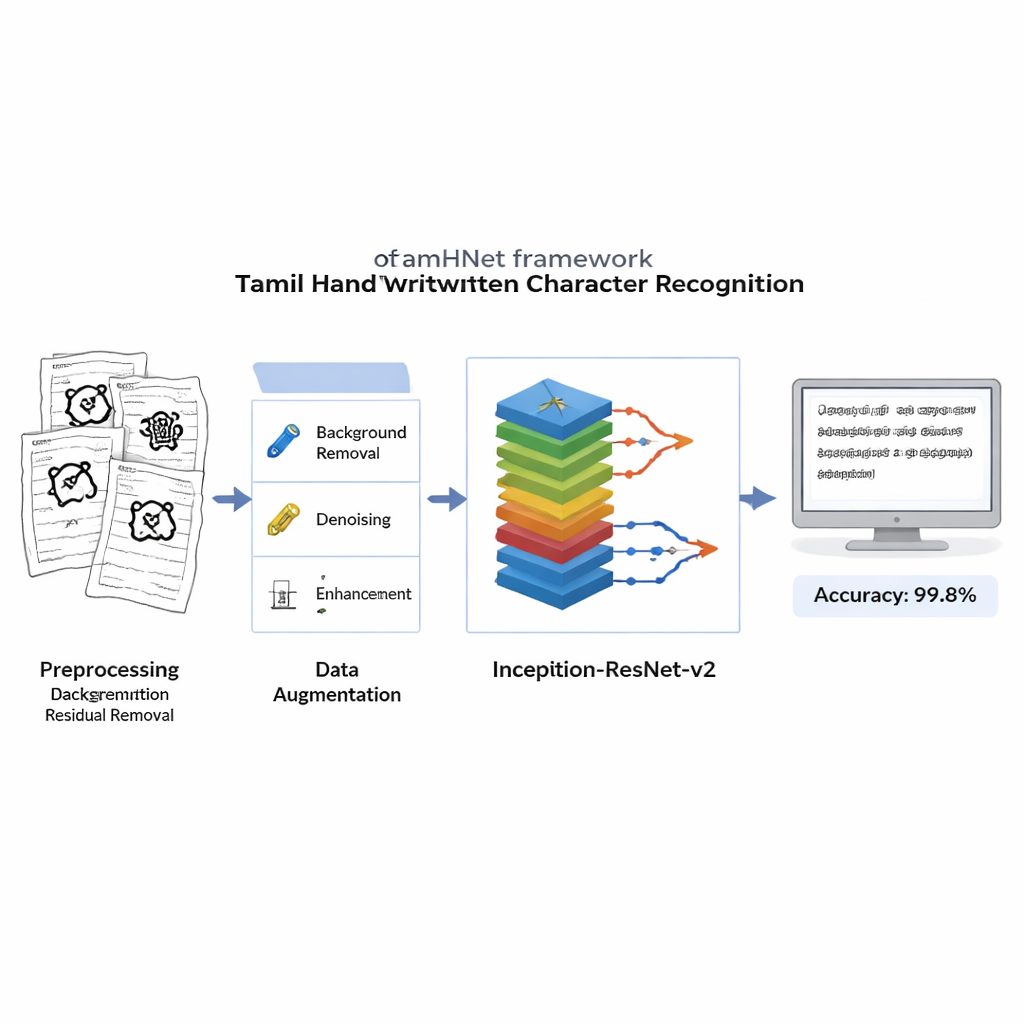
From old palm-leaf manuscripts to everyday notes, much of Tamil’s written heritage still lives on paper. Turning this rich mix of handwritten pages into searchable, digital text is essential for preserving culture, supporting education, and building better language technologies. This article presents a new computer vision system, called TamHNet, that reads Tamil handwriting with near-perfect accuracy, even when letters look confusingly similar to one another.
Why Tamil letters are hard for computers
Tamil is spoken by more than 80 million people and uses a script with 247 characters, including vowels, consonants, and many combinations of the two. Many letters differ only by tiny curls or extra strokes, and writers vary widely in how they form each character. Pairs such as எ/ஏ or ஒ/ஓ may look almost identical at a glance, and characters like ல and வ can be easily mistaken for one another. Earlier computer programs and even modern machine-learning systems often struggled with these subtleties, leading to misread words and unreliable digitization of documents.
Building a real-world handwriting dataset
To train and test their system in realistic conditions, the researchers created a new Tamil Isolated Character Dataset using handwritten samples from 1,000 university students. Instead of relying on synthetic or computer-generated images, they collected genuine pen-on-paper characters covering 12 vowels, 18 consonants, and 214 common combinations. The team carefully labeled these samples and made the dataset publicly available so other groups can compare methods and build on this work. By organizing the script into 104 base symbols that capture all 247 characters, they reduced redundancy while still representing the full range of shapes that appear in real handwriting.
Cleaning, stretching, and teaching the images
Before any learning takes place, each scanned image is cleaned to remove noisy backgrounds, smudges, and uneven lighting while preserving the delicate strokes that define each letter. The pictures are converted to crisp black-and-white images and resized to a standard format so the computer sees each example in the same way. To make the system robust to different writing habits, the authors then use controlled distortions: they slightly shift key points in the image and apply smooth warping, generating new versions of each character that still look like the same letter to a human. This expanded training set helps the model recognize characters even when they are slanted, compressed, or written with unusual proportions.
A deep network that learns subtle differences
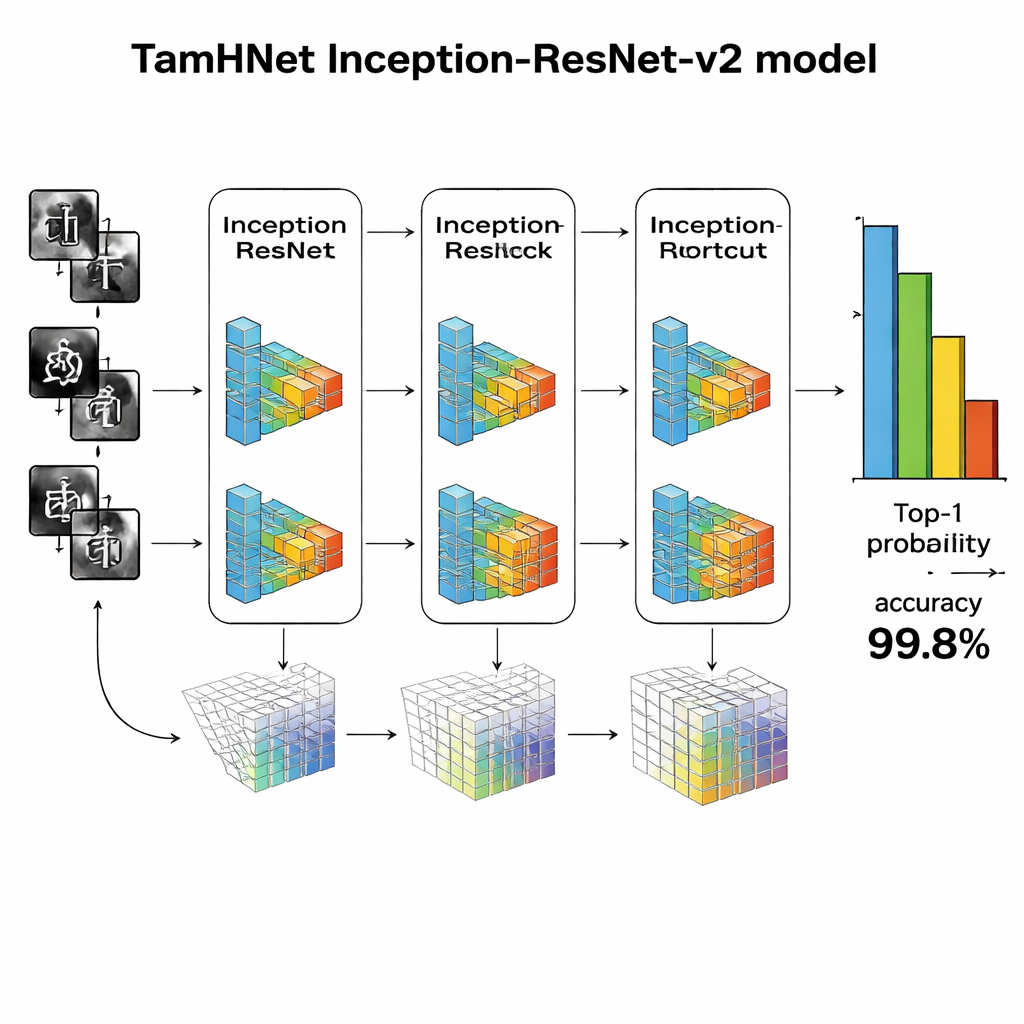
At the heart of TamHNet is a powerful deep-learning architecture called Inception-ResNet-v2, originally designed for general object recognition. The authors adapt and fine-tune this network specifically for Tamil handwriting. The model processes each image through many layers that gradually transform raw pixels into higher-level patterns, such as edges, curves, and character parts. Special shortcut connections, known as residual links, stabilize training and help the network focus on small but crucial differences between similar letters. Instead of adjusting all internal settings at once, the team selectively “unfreezes” the most useful layers and tunes them for this task. They use an optimization technique called Adam, which automatically adapts how quickly each parameter changes, allowing the network to learn efficiently from complex and sometimes messy handwriting.
How well the system reads handwriting
The researchers evaluate TamHNet on the new dataset using standard measures of recognition quality. The system achieves about 99.8% accuracy across 104 character classes, outperforming a wide range of earlier methods based on support vector machines, traditional convolutional networks, and other advanced deep-learning designs. Detailed tests show that even letters with extremely similar shapes are correctly distinguished in most cases, and statistical curves confirm that the model very rarely confuses one character for another. Compared with previous work, this represents a clear step forward in reliability for Tamil handwritten character recognition.
What this means for readers and archives
For non-specialists, the main takeaway is that computers are getting dramatically better at reading Tamil handwriting. A system like TamHNet can power tools that turn stacks of notebooks, historical manuscripts, and handwritten forms into searchable digital text with minimal human correction. While the current model does not yet handle certain dot-based symbols and older script variants, the authors outline plans to extend it to ancient writing styles as well. In practical terms, this research brings us closer to large-scale, accurate digitization of Tamil documents, helping safeguard cultural heritage and making written knowledge easier to access for future generations.
Citation: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Keywords: Tamil handwritten character recognition, optical character recognition, deep learning, Inception-ResNet, digital preservation