Clear Sky Science · en
Performance comparison of large language models in boron neutron capture therapy knowledge assessment
Smart Tutors for a New Kind of Cancer Radiation
Boron neutron capture therapy, or BNCT, is an emerging type of radiation treatment that aims to destroy tumors while sparing nearby healthy tissue. As this complex therapy spreads from research labs into hospitals, doctors and trainees need to master a lot of new, specialized knowledge. This study asks a timely question: can today’s popular artificial intelligence chatbots help teach and support BNCT, and if so, how reliable are they?
What Makes BNCT Different from Regular Radiation?
BNCT works very differently from standard X‑ray or proton treatments. Patients receive drugs containing a special form of boron that gathers inside tumor cells. When those cells are later exposed to a beam of neutrons, the boron atoms undergo a tiny nuclear reaction that releases short‑range particles, killing the cancer cell from within while leaving nearby tissue largely unharmed. This highly targeted approach is especially promising for hard‑to‑treat or oxygen‑poor tumors. Until recently, BNCT depended on nuclear reactors as neutron sources, limiting its clinical use. The approval of accelerator‑based BNCT machines in Japan in 2020, and new centers now operating in countries such as China, have turned BNCT into a realistic option for more patients—and created an urgent need for focused training and certification.
Putting Four Leading AIs to the Test
To see how well general‑purpose chatbots handle BNCT topics, the researchers built a 47‑question test that covered basic ideas, the latest research, clinical practice, and calculation and reasoning tasks. The questions were written in both Chinese and English and included simple facts (such as definitions) and more demanding problems requiring logic or numerical work. Four major AI families—represented by widely used systems from different companies—were each tested across five separate time periods, in two languages and with two ways of asking questions (simple direct questions and questions wrapped in a short clinical scenario). Human cancer‑care specialists scored every answer against a standard key, and the team also tracked how often the AIs admitted uncertainty by saying things like “I don’t know.”
Who Answered Best, and on What Kinds of Questions?
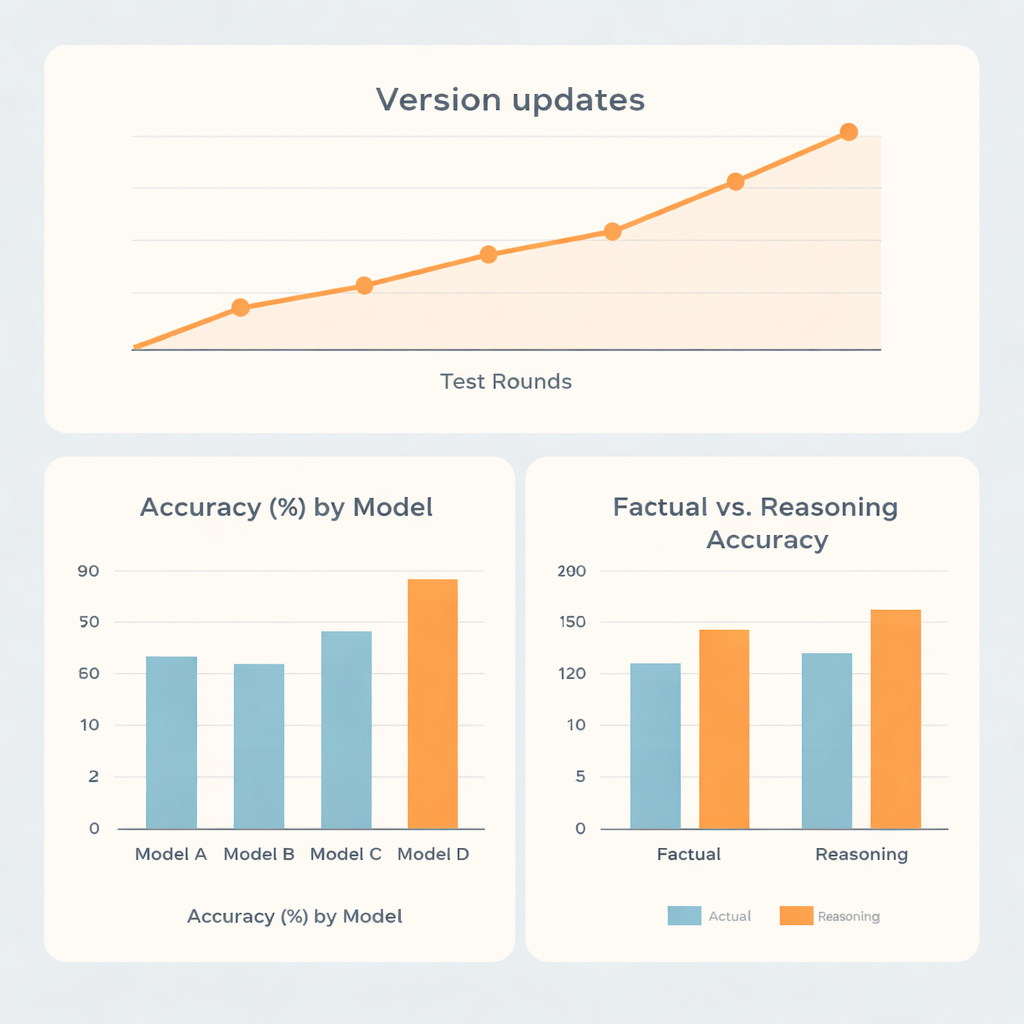
Overall, two model families performed clearly better than the other two. The strongest system reached about 73% accuracy, and the second‑best about 70%, while the remaining models scored around 62% and 56%. Interestingly, the top performers did not simply excel at memorized facts. They were noticeably better on reasoning‑heavy questions than on straightforward recall, suggesting that these systems are relatively strong at multi‑step thinking tasks, such as dose calculations or planning‑style problems, within this narrow medical field. One model showed almost the same scores on fact and reasoning items, while another lagged behind overall despite doing somewhat better on reasoning than on facts.
Updates, Languages, and Willingness to Say “I Don’t Know”
Because AI systems are updated frequently, the researchers also examined how performance changed over five test rounds spread from late 2023 to mid‑2025. Major version upgrades tended to bring clear jumps in accuracy, whereas minor tweaks within the same version made little difference. One family climbed from under 60% to over 80% accuracy over time, highlighting how quickly the technology is advancing. Surprisingly, whether questions were asked in Chinese or English, or posed directly versus wrapped in a role‑playing prompt, had only small effects compared with the built‑in strengths of each model. More striking were the differences in how candid the systems were when they were wrong. Some models admitted uncertainty in nearly one out of five incorrect answers, while another rarely did so, often offering confident but mistaken replies instead.
What This Means for Doctors, Students, and Patients
The study concludes that today’s best general‑purpose chatbots can already provide reasonably accurate explanations and practice questions about BNCT, making them promising helpers for education and self‑study. However, none of the systems can yet be trusted to answer all BNCT questions correctly, and their styles of expressing—or hiding—uncertainty differ in ways that matter for safety. For now, these tools are best seen as smart assistants that can support, but not replace, expert judgment. The authors argue that dedicated BNCT‑focused AI models, along with clear standards for how such tools should be used in clinics and classrooms, will be needed before AI can play a reliable frontline role in this highly specialized form of cancer care.
Citation: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Keywords: boron neutron capture therapy, cancer radiation, medical education, artificial intelligence, large language models