Clear Sky Science · en
Object-guided contrastive language-image pre-training for zero-shot target recognition
Smarter Eyes for Crowded Skies and Seas
Modern security and disaster‑response systems rely on cameras in the sky and at sea to spot aircraft, ships, and other critical objects. But teaching computers to tell a fighter jet from a passenger plane, or a warship from a cargo vessel, is surprisingly hard when scenes are cluttered, data are scarce, and new models of equipment keep appearing. This paper introduces OG‑CLIP, a new AI system designed to recognize military and civilian targets it has never been explicitly trained on, by combining large‑scale prior knowledge with a sharper visual focus on the objects that matter most.
Why Traditional AI Misses the Target
Most image recognition systems learn from huge collections of labeled pictures: each image is tied to a fixed list of categories, such as “cat” or “car.” That approach breaks down in specialized domains like defense and remote sensing, where data are sensitive, labeling requires experts, and the variety of equipment is enormous. Newer vision‑language models such as CLIP pair images with short text captions gathered from the web, allowing them to recognize new concepts described in words. Yet in military imagery, these models still struggle: captions are often vague, backgrounds like clouds and waves dominate the pixels, and their internal features are not flexible enough to run efficiently on everything from small drones to powerful servers. OG‑CLIP tackles all three problems head‑on.
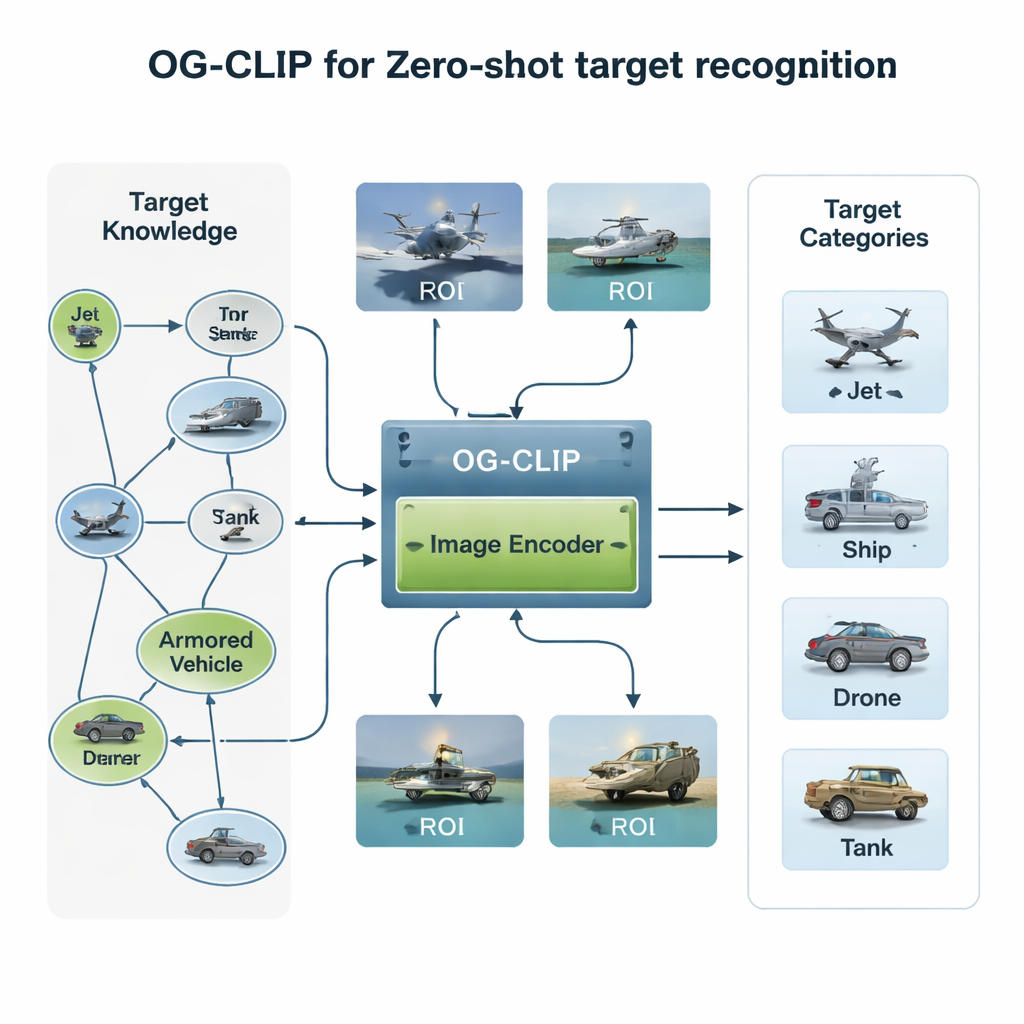
Building a Knowledge‑Rich Training World
The first ingredient of OG‑CLIP is a carefully engineered training universe. The authors assembled a database of 5,000 types of targets—ranging from fighters and bombers to warships and civilian aircraft—and organized them into a detailed knowledge graph. Each entry includes structured facts such as range, weight, and weapon configuration, drawn from public defense references, encyclopedias, and technical documents. They then collected about one million images using public datasets, web search, older in‑house archives, and even simulated scenes from game engines. To keep the data trustworthy, they clustered images using an existing model to spot outliers, followed up with expert review, and filtered out bad labels. Finally, they used advanced language‑vision tools to turn the knowledge graph into rich, natural‑language descriptions of each image, so the system learns not just “this is a jet,” but “a single‑aisle aircraft with upward‑curving winglets” or “a stealth bomber with a flying‑wing shape.”
Teaching the Model to Ignore the Noise
A second innovation lies in where the model looks. In many satellite or aerial pictures, the actual ship or aircraft occupies only a small patch, surrounded by distracting sky, sea, or terrain. OG‑CLIP adds a region‑of‑interest (ROI) module that mimics how a human would glance at the key object rather than the whole frame. A state‑of‑the‑art segmentation tool automatically outlines likely objects in the image, producing soft masks that highlight the target and dim the background. These masks are fed, alongside the original image, into the visual backbone of the model, so that its attention naturally concentrates on distinctive features like wing shape, deck layout, or hull silhouette. This plug‑in design can be added to existing systems without rewriting their core architecture, giving them a more “object‑guided” gaze.

Adapting Detail to the Hardware
The third piece addresses a practical but crucial concern: not all devices can afford the same level of detail. A satellite ground station might process rich, high‑dimensional features, while a small drone needs faster, lighter computations. Traditional methods fix a single feature size, or train several separate models for different sizes. OG‑CLIP instead uses a “Matryoshka” style of representation, packing information at multiple levels of detail into one vector, like nested dolls. The system can slice off shorter or longer portions of this vector—coarser or finer descriptions of what is in the image—without retraining. A weighting mechanism encourages each level to keep the most useful information for classification, and an extra loss term nudges the levels to stay semantically consistent with one another.
How Well Does It Work in Practice?
To test OG‑CLIP, the researchers built a challenging evaluation set of 99 target categories, including 51 types of military aircraft, 29 types of warships, and 19 civilian or mixed targets. Crucially, none of these categories appears in the training data, so the system must rely on its learned understanding of language and visual patterns—a “zero‑shot” test. Compared with several strong CLIP‑based baselines, OG‑CLIP improved mean accuracy by more than 11 percentage points, reaching 84.28 percent overall. It performed especially well on crowded, complex scenes and on fine distinctions between similar models, such as different fighter jets, where the ROI module and knowledge‑rich descriptions gave it a clear edge. Ablation studies showed that each component—the knowledge‑graph data, the ROI focus, and the adaptive representations—contributed measurable gains.
What This Means for Real‑World Monitoring
For non‑specialists, the key takeaway is that OG‑CLIP is a step toward security and monitoring systems that can more reliably recognize unfamiliar aircraft and ships from real‑world imagery, even when labeled examples are scarce. By combining structured expert knowledge, automatic focus on the object of interest, and adjustable levels of detail, the approach makes vision‑language AI both smarter and more practical. Beyond defense, similar ideas could help environmental monitoring, disaster response, and industrial inspection systems make sense of complex scenes while running on a wide range of hardware.
Citation: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Keywords: zero-shot recognition, vision-language models, object detection, remote sensing, knowledge graphs