Clear Sky Science · en
Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction
Why it matters for everyday images
In an era where anyone can generate a lifelike picture with a few clicks, it is getting harder to tell whether an image is a real photograph, a traditional painting, or something crafted entirely by algorithms. This study explores how modern artificial intelligence can automatically distinguish human-made paintings from camera-taken photos, and even from AI-generated imagery, helping protect art markets, archives, and online users from confusion and forgery.
Art, photos, and the rise of machine-made pictures
Paintings and photographs may look similar at first glance on a screen, but they carry very different visual fingerprints. Paintings tend to show visible brushstrokes, stylized colors, and more abstract compositions, while photographs usually contain sharper details and natural lighting. At the same time, new image generators are producing works that imitate both media with growing skill. Museums, galleries, collectors, and digital platforms increasingly need tools that can quickly and reliably tell what kind of image they are dealing with, both to authenticate artworks and to manage the flood of synthetic content.
A new pipeline for teaching machines to see
The researchers built a complete image-analysis pipeline based on a Vision Transformer, a recent deep learning model originally developed for language processing and now adapted to pictures. They trained this system on a public Kaggle dataset containing 1,361 paintings and 3,747 photographs, representing a wide variety of scenes and styles. Each image is first standardized: it is resized, lightly cropped, and then augmented through flips, small rotations, brightness changes, and noise removal so that the model experiences many realistic variations. After this preparation, the Vision Transformer divides each image into small patches and learns how different parts of the image relate to one another across the whole frame. 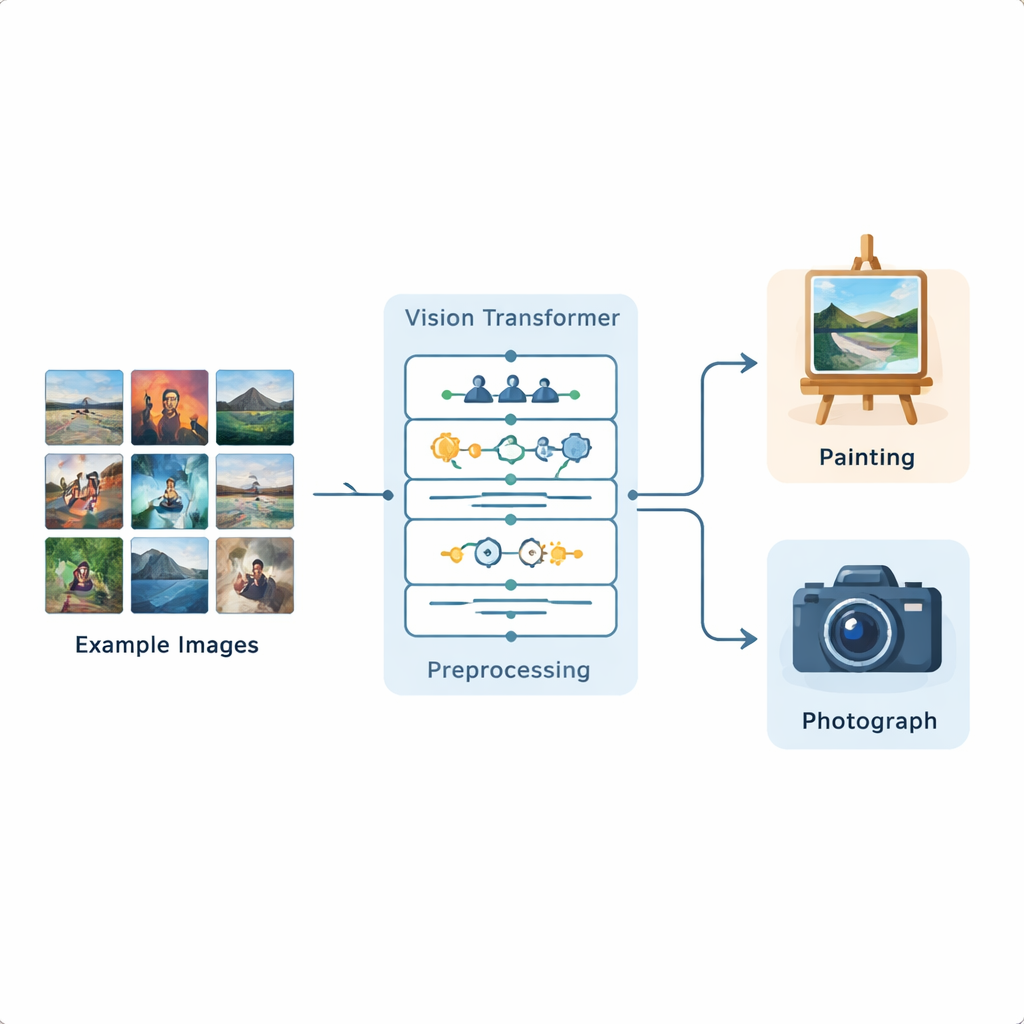
How the model focuses on the right details
Unlike earlier neural networks that mainly look at local patterns, the Vision Transformer uses an "attention" mechanism to decide which parts of an image matter most for the task at hand. It effectively asks, for every patch, how strongly it should pay attention to every other patch. This makes it better at noticing global structure: the way colors flow across a canvas, how light falls across a scene, or how textures repeat. To check that the model is not guessing blindly, the authors also apply a visualization method called Grad-CAM, which highlights the specific regions that influenced each decision. For paintings, these highlights tend to fall on brushstroke textures and stylized areas; for photographs, they cluster around fine edges, realistic surfaces, and lighting transitions. 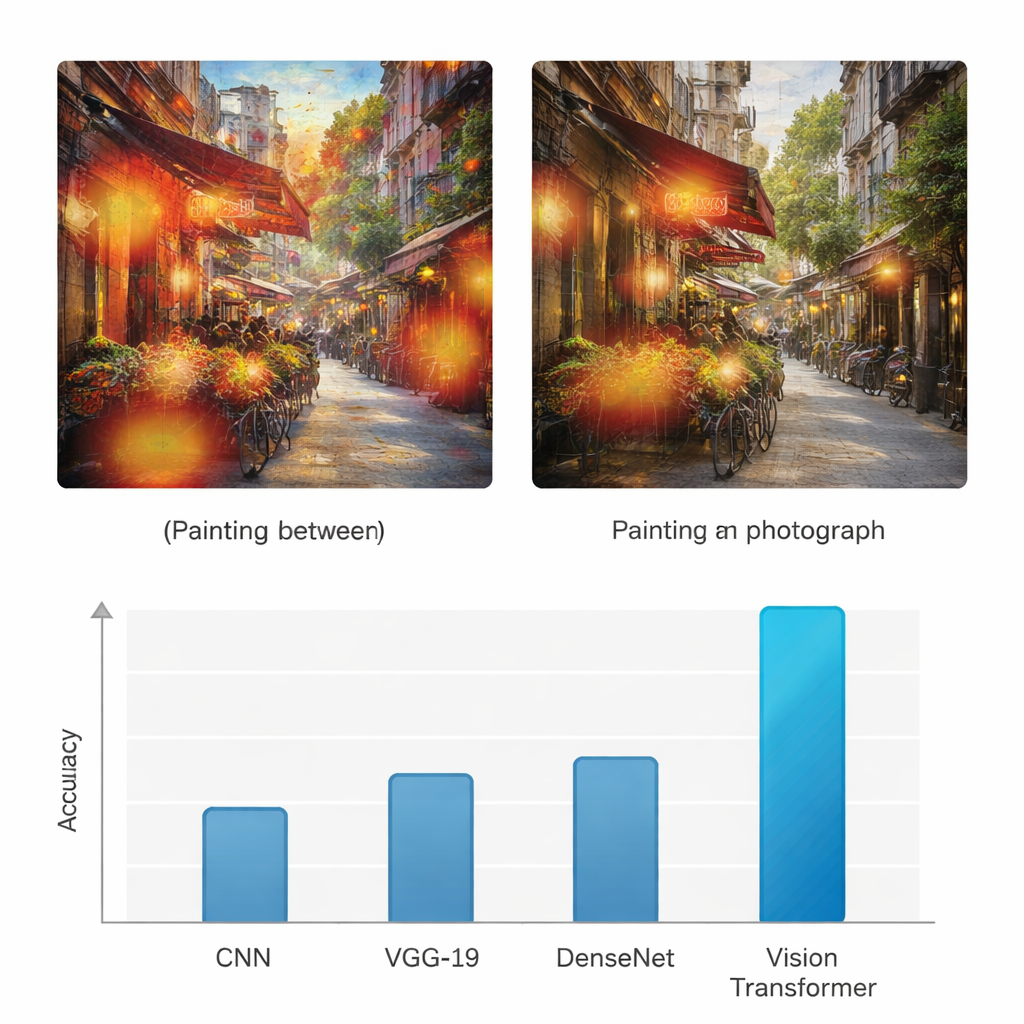
Outperforming earlier image-recognition methods
To see whether this approach truly adds value, the study compares the Vision Transformer with three widely used deep learning architectures: a standard convolutional neural network (CNN), the VGG-19 network, and DenseNet. All models are trained and tested on the same dataset, and evaluated with common measures such as accuracy, precision, recall, and F1-score, which balance correct detections and mistakes for both classes. While the baseline networks reach accuracies in the mid-70s to mid-80s percent range, the Vision Transformer achieves 95% accuracy for both paintings and photographs, with similarly high precision and recall. The authors further run multiple statistical tests to confirm that this improvement is not due to chance, showing that the transformer-based model is reliably better across repeated trials and different evaluation criteria.
What this means for art, trust, and technology
The findings suggest that modern transformer models can serve as powerful and explainable tools for separating paintings from photographs and for flagging AI-generated images that mimic either medium. For non-specialists, the takeaway is that computers can now detect subtle cues—such as brushwork, smoothness, or lighting gradients—that even careful human observers might miss, and do so at scale. Such systems could help galleries and collectors verify works, assist curators and archivists in organizing vast digital collections, and support online platforms in labeling or filtering synthetic content. As image generators continue to blur the line between reality and invention, methods like the one presented here offer a practical way to maintain trust in what we see.
Citation: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Keywords: AI-generated images, art authentication, image classification, vision transformer, digital art analysis