Clear Sky Science · en
ADAT novel time-series-aware adaptive transformer architecture for sign language translation
Bridging the communication gap
For millions of Deaf and hard-of-hearing people, everyday tasks like visiting a doctor or watching a weather report can be harder than they should be, simply because skilled sign language interpreters are scarce. This paper introduces a new artificial intelligence system called ADAT that turns sign language videos into written sentences more accurately and more efficiently than many existing systems, bringing us closer to real-time, widely available sign language translation on phones, tablets, and hospital computers.
Why sign language is hard for computers
Sign languages are rich, complex languages with their own grammar, and they rely on much more than moving hands. Facial expressions, body posture, and subtle timing all change the meaning of a signed sentence. Modern translation systems often use a powerful AI design known as a transformer, which is very good at understanding long sentences in spoken or written language. But when it comes to high‑speed video—30 to 60 frames every second—these systems can become slow and struggle to notice the quick, fine-grained movements that distinguish one sign from another. They also need a lot of computer power and training time, which makes it harder to keep them up to date as sign languages evolve.
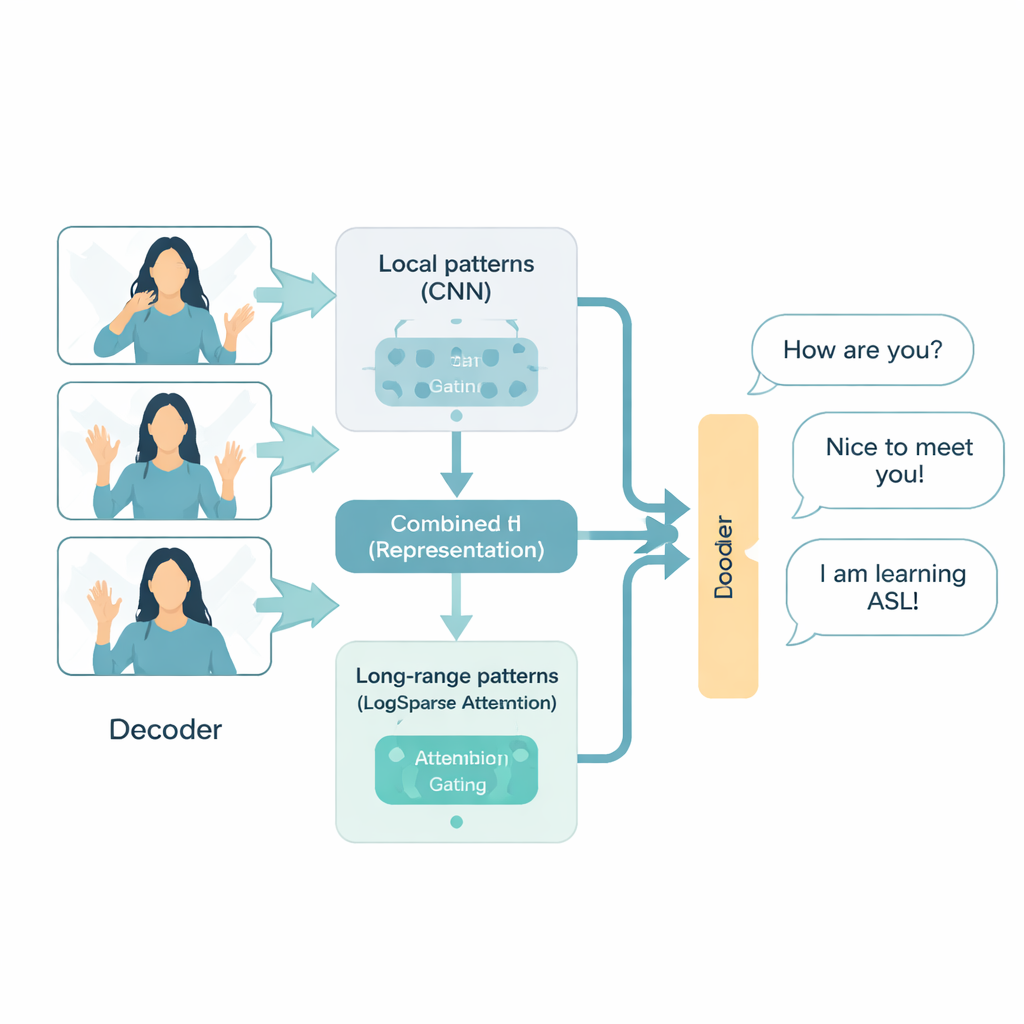
A smarter way to read signing
The ADAT architecture is designed specifically for sign language video, treating it as a time series: a fast stream of visual events unfolding over time. It combines three ideas. First, it uses convolutional neural networks, a proven image technique, to zoom in on local patterns like hand shapes and facial cues. Second, it uses a more efficient form of attention, which selectively looks back at key moments in the video rather than comparing every frame with every other frame. Third, an adaptive “gate” learns how to blend detailed short-term information with broader long-term context, deciding on the fly which matters more for each part of a sentence. Together, these parts allow ADAT to capture both the quick flick of a finger and the overall structure of a conversation without wasting computation.
From signs to words in two ways
Sign language translation can be organized in two main steps: first recognizing the basic units of signing, known as glosses, and then turning those glosses into spoken or written text. This is called sign-to-gloss-to-text. Alternatively, a system can try to go directly from video to text in one shot, called sign-to-text. The authors test ADAT on both styles. They compare it with several strong transformer-based baselines, including a well-known system called SLTUNET, across three datasets: a large German weather forecast corpus, an Indian Sign Language collection, and a new American Sign Language medical dataset that the authors created to reflect realistic doctor–patient conversations.
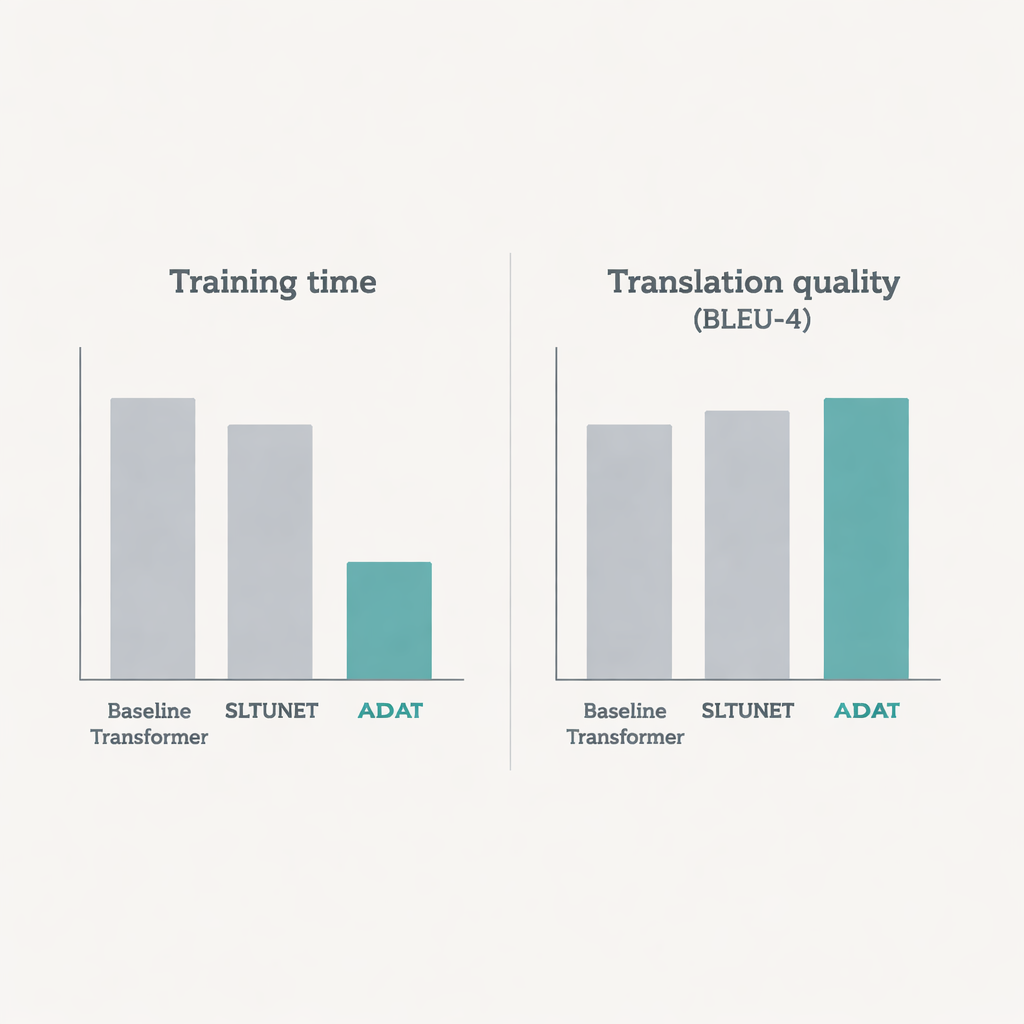
Faster training and sharper translations
Across these tests, ADAT either matches or beats the best competing models in translation quality, measured by standard BLEU scores, while training noticeably faster. In the two-step sign-to-gloss-to-text setup, it delivers similar or slightly better scores than a classic transformer but reduces training time by about one-fifth on average. In the tougher direct sign-to-text setup, ADAT clearly outperforms encoder-only, decoder-only, and unified transformer baselines, often improving accuracy by around one percentage point or more, again with roughly 20% faster training. Detailed analysis of the underlying math shows that ADAT’s more selective attention and dual-path design cut the number of required operations substantially, especially when dealing with long or high-frame-rate videos.
New data for critical conversations
To make sure these methods extend beyond lab settings, the authors introduce MedASL, the first American Sign Language dataset focused on medical communication. It consists of 500 unique, carefully designed sentences that simulate real interactions between patients and healthcare professionals and includes both gloss and text annotations. This medical focus matters because misunderstandings in a hospital or clinic can have serious consequences, and existing datasets rarely cover this domain. ADAT performs strongly on MedASL, although the results also reveal how challenging it is for any system to generalize perfectly to new, real-world sentences.
What this means for everyday life
In plain terms, the study shows that we can build sign language translation systems that are both smarter and leaner: they need less time and computing power to train, yet they better capture the subtleties of signing. ADAT is not yet a plug‑and‑play interpreter for every sign language in every situation, and it still lags behind systems that rely on huge pre-trained models. But by focusing on time‑sensitive video patterns and efficiency, it points the way toward practical tools that could one day run on everyday devices, support multiple sign languages, and help Deaf users communicate more easily in critical settings such as healthcare, emergency response, and public services.
Citation: Shahin, N., Ismail, L. ADAT novel time-series-aware adaptive transformer architecture for sign language translation. Sci Rep 16, 6551 (2026). https://doi.org/10.1038/s41598-026-36293-9
Keywords: sign language translation, adaptive transformer, time-series attention, medical ASL, accessible AI