Clear Sky Science · en
Meta-learning for few-shot open task recognition
Why teaching AI with very few examples matters
Modern AI systems can recognize faces, animals, and everyday objects with remarkable accuracy—but usually only after seeing millions of labeled images. In many real situations, such as diagnosing a rare disease or spotting a new type of defect on a factory line, we simply do not have that much data. This paper explores how to train AI models that can learn new visual tasks from just a handful of examples, even when those tasks look quite different from what the model was trained on. It introduces a method called Open-MAML that aims to make this kind of flexible, low-data learning more reliable and predictable.
From fixed classroom drills to open-ended pop quizzes
Most research on “few-shot learning” evaluates AI systems under tightly controlled conditions. The model is trained and tested on very similar tasks, for example always having to distinguish between exactly five categories (called “5-way”) with one example per category (“1-shot”). This is like drilling a student only on five-question quizzes with one practice example per question type. Real-world deployments are far messier: the number of categories can change, and the amount of labeled data for each can go up or down over time. The authors call this more realistic situation the open-task setting, where models must handle tasks with different numbers of classes and examples than they ever saw during training. 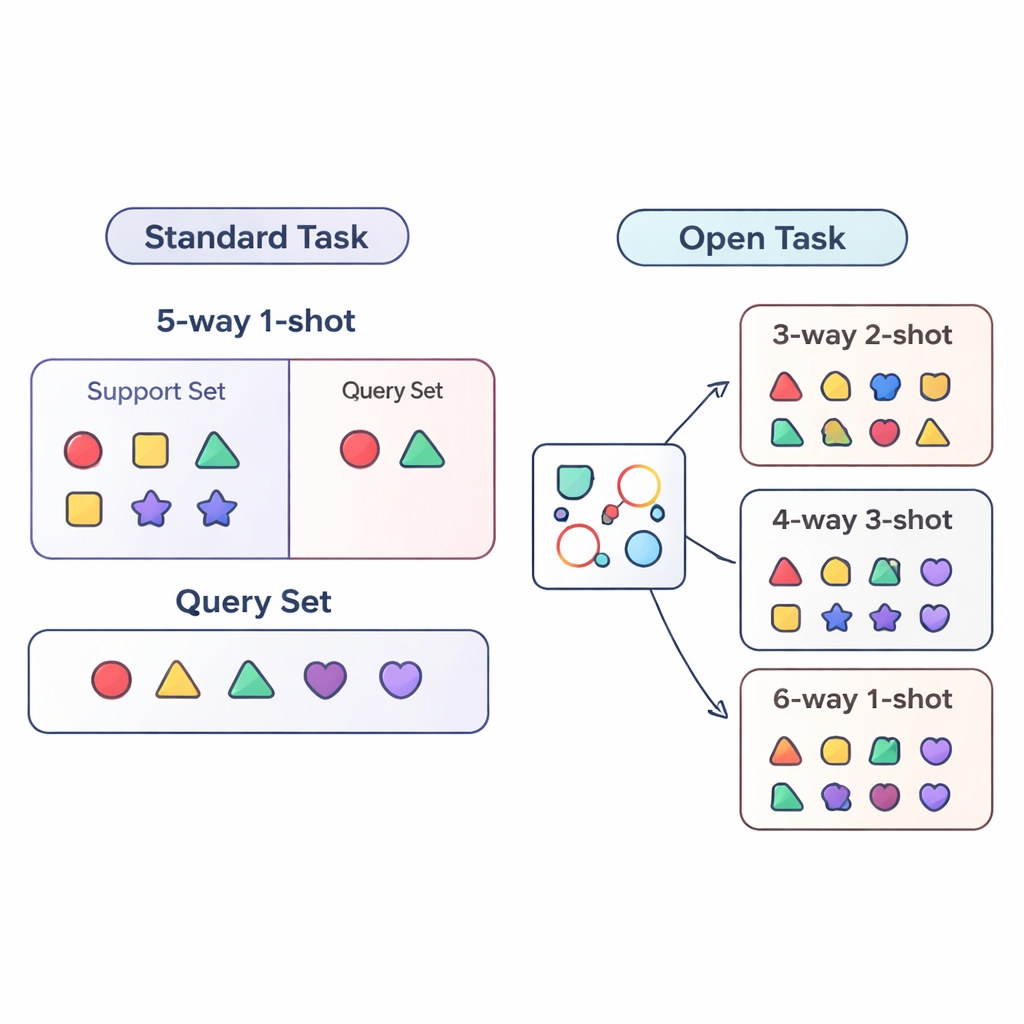
Redefining how we test few-shot learners
To study this open-task world in a systematic way, the paper proposes three evaluation regimes. In the cross-way regime, only the number of classes changes: the model might train on five classes but be tested on three or fifteen. In the cross-shot regime, the number of examples per class varies, from a single labeled image to several. The hardest case is cross-way–cross-shot, where both the number of classes and the amount of data per class change together. The authors also examine what happens when the visual style of the data shifts, training on a generic object dataset and testing on a fine-grained bird dataset. These setups are designed to expose whether a method can truly generalize beyond a single, fixed training recipe.
How Open-MAML adapts on the fly
Open-MAML builds on a popular meta-learning strategy called Model-Agnostic Meta-Learning (MAML), which trains a model so it can quickly adapt to a new task with a few gradient steps. Standard MAML, however, assumes that the number of categories at test time matches training, and it uses a fixed final classification layer. Open-MAML introduces three key tweaks to break this limitation. First, it uses dynamic classifier construction: when a new task has more classes than before, it creates extra output units by copying the average of the existing ones, giving the model a neutral but sensible starting point. Second, it adjusts the inner learning rate based on how many classes and examples the task has, so adaptation remains stable whether data are scarce or plentiful. Third, it adds a regularizer called AdaDropBlock that temporarily hides contiguous regions in feature maps during training, nudging the model to use more diverse visual cues instead of overfitting to small, brittle details. 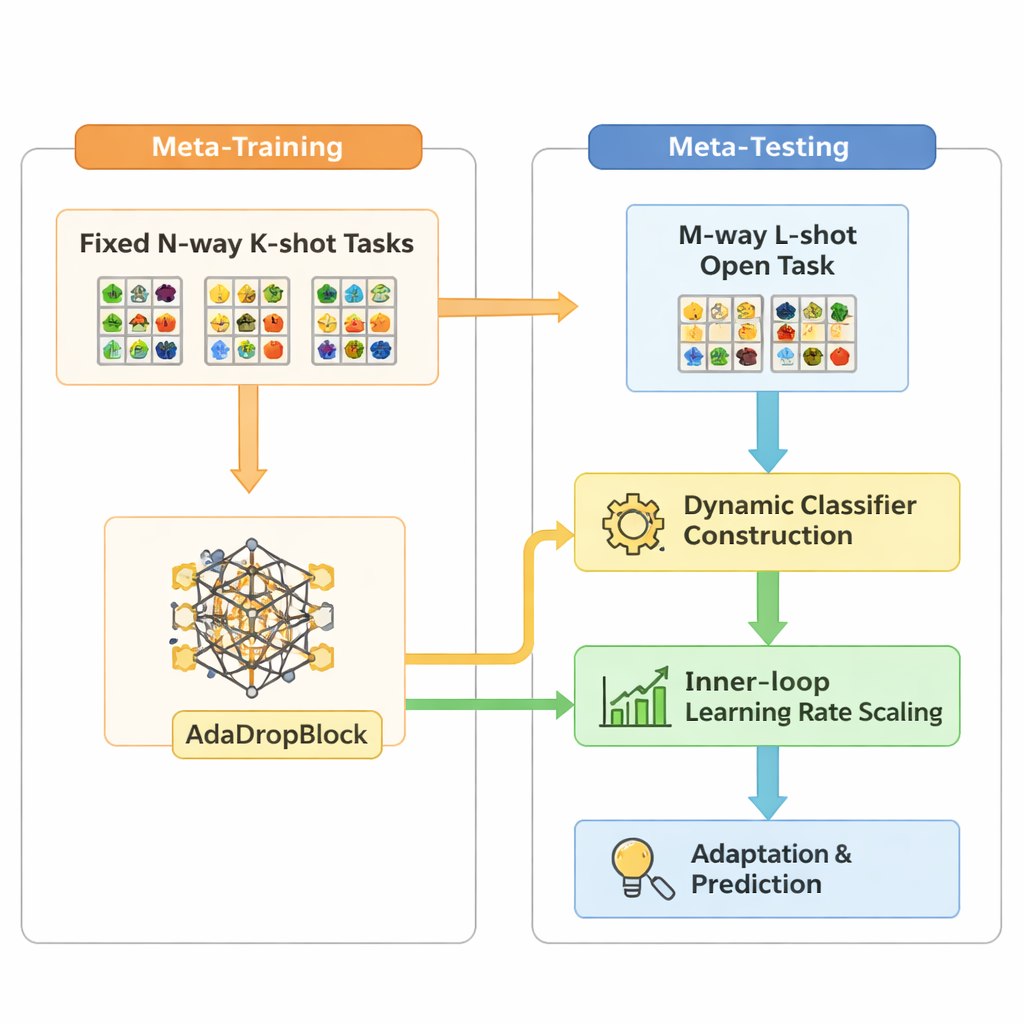
Putting flexible learning to the test
The researchers evaluate Open-MAML on standard few-shot benchmarks and under the new open-task scenarios, comparing it to several well-known baselines. These include models that are simply trained from scratch per task, models that use a strong pre-trained feature extractor plus a fine-tuned classifier, and metric-based methods that classify images based on their distance to class “prototypes.” All methods share the same backbone network so that differences come from the learning strategy, not the architecture. Across tens of thousands of test tasks, Open-MAML consistently achieves higher accuracy—typically 1–7 percentage points better when only the number of classes or examples changes, and 3–6 points better when both vary. The gains are even more pronounced on harder settings with more classes, more shots, or a shift to the bird dataset, suggesting that its adaptation mechanisms really do help in complex, unfamiliar territory.
What this means for real-world AI systems
For a general reader, the take-home message is that not all few-shot learners are created equal once we leave the lab’s comfort zone. A method that shines on a single, fixed benchmark can stumble when the number of categories or the amount of labeled data changes. Open-MAML shows that by explicitly planning for such structural changes—letting the classifier grow or shrink, scaling the learning rate with task size, and regularizing features in a task-agnostic way—AI systems can better cope with the shifting conditions they will face in practice. In settings like medical imaging, satellite monitoring, or industrial inspection, where both the set of categories and the availability of labels are in constant flux, this kind of open-task robustness could make few-shot learning far more usable outside of carefully curated research benchmarks.
Citation: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Keywords: few-shot learning, meta-learning, open-task recognition, image classification, generalization