Clear Sky Science · en
IASUNet: building extraction based on impoved attention Swin-UperNet
Why spotting every building from space matters
As cities grow and the climate changes, knowing exactly where buildings are—and how they change over time—has become vital. From planning safer neighborhoods and tracking illegal construction to guiding disaster response after floods or earthquakes, detailed building maps are now a core ingredient of smart, resilient cities. This paper introduces IASUNet, a new artificial intelligence system that learns to pick out buildings automatically from high‑resolution satellite images with remarkable precision, even in messy, crowded real‑world scenes.
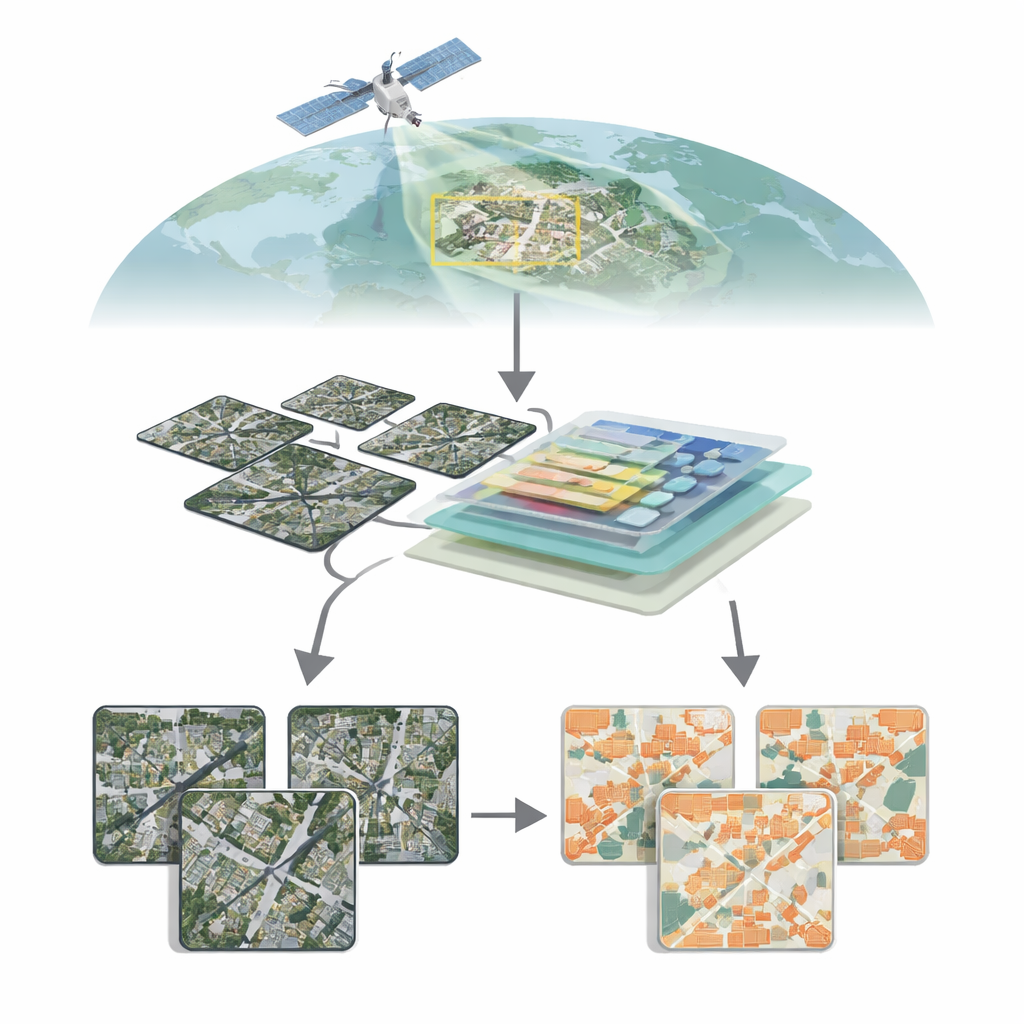
Seeing cities from above
Modern satellites can photograph Earth in extraordinary detail, revealing individual rooftops, roads, and even narrow alleyways. Turning this sea of pixels into clean building maps, however, is far from trivial. Buildings vary wildly in size, shape, color, and surroundings: glass towers in downtown cores, low houses in suburbia, scattered farm buildings in the countryside. In rural or mixed areas, buildings may occupy only a tiny fraction of each image, while vegetation, soil, and water dominate. Traditional computer vision methods, based mainly on convolutional neural networks, can struggle to capture the big picture across an entire scene while still respecting fine boundaries, leading to missed small structures or blurred edges.
A smarter attention to detail
IASUNet tackles these challenges by combining two powerful ideas: a Transformer-based encoder called Swin Transformer, and a flexible decoder known as UperNet. The Swin Transformer breaks an image into many small patches and learns how they relate to one another across the whole scene, rather than only looking through a fixed-sized window. This helps the model understand broader context—such as whether a bright rectangle sits inside a dense city block or an isolated field—while still preserving detail. On top of this, the authors weave in an attention mechanism called the Convolutional Block Attention Module (CBAM) at several stages. CBAM learns, channel by channel and region by region, which image features are most likely to belong to buildings and which are background clutter, boosting the former and suppressing the latter before the decoder pieces everything back into a full building map.
Balancing the odds when buildings are rare
Another practical obstacle is imbalance: in many satellite scenes, most pixels show roads, fields, trees, or water, while buildings occupy only small islands. Standard training methods tend to favor whatever appears most often, which risks teaching a model to treat less frequent buildings as afterthoughts. To counter this, the authors adapt a loss function called Focal Cross‑Entropy. This strategy reduces the influence of “easy” background pixels and amplifies the impact of hard‑to‑classify building pixels during training. As a result, the model pays extra attention to small, faint, or unusual structures that might otherwise be overlooked, improving recall without flooding the map with false alarms.
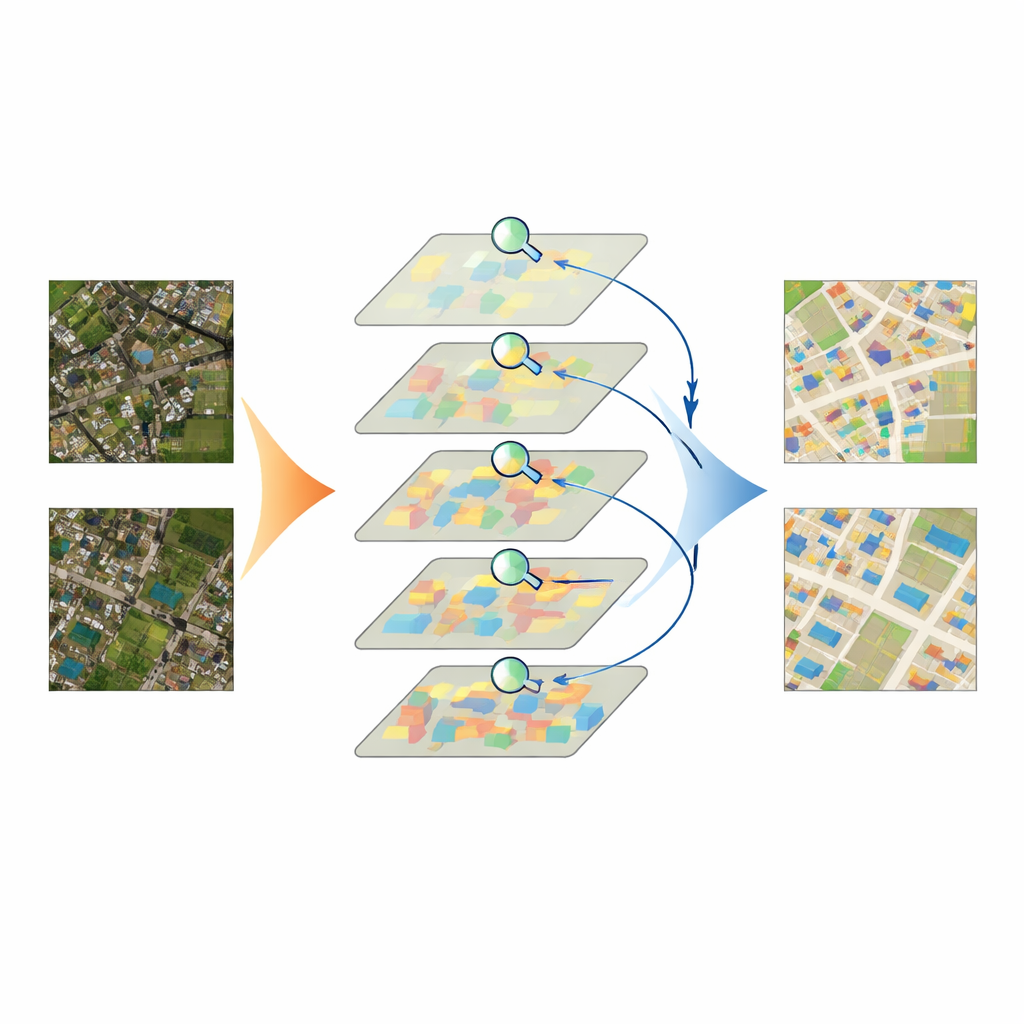
Putting the model to the test
The team tested IASUNet on three well‑known building datasets from Germany, New Zealand, and the United States, as well as on a carefully curated collection of Chinese satellite images they prepared and quality‑checked themselves. Across these benchmarks, IASUNet consistently matched or outperformed leading approaches, including strong convolutional networks and other Transformer‑based models. On the ultra‑detailed Potsdam dataset, it reached near‑perfect overlap between predicted and true building regions, while still running at practical speeds on modern graphics hardware. Even on more irregular landscapes, where buildings are scattered, partly hidden, or tightly packed, IASUNet drew cleaner outlines, captured more small targets, and avoided many of the omissions and boundary errors seen in competing methods.
From pixels to better cities
In everyday terms, the study shows that we can now teach computers to read cityscapes from orbit with unprecedented clarity. By carefully directing the model’s “attention” to the right parts of an image and deliberately weighting rare but crucial building pixels, IASUNet turns raw satellite pictures into accurate, up‑to‑date building maps with modest extra computing cost. Such maps can feed into urban planning, energy and heat‑island studies, land‑use regulation, and rapid damage assessment after disasters. While the work is technical at its core, its conclusion is simple: smarter AI can give decision‑makers a sharper, more reliable view of the built environment, helping cities grow in safer and more sustainable ways.
Citation: Zhang, H., Ma, Y., Wang, G. et al. IASUNet: building extraction based on impoved attention Swin-UperNet. Sci Rep 16, 7969 (2026). https://doi.org/10.1038/s41598-026-36270-2
Keywords: remote sensing, building extraction, semantic segmentation, transformer networks, urban mapping