Clear Sky Science · en
Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness
Why everyday Arabic confuses smart computers
Many apps now read Arabic text to judge sentiment, sort news, or answer questions. Yet these systems mostly learn from Modern Standard Arabic (MSA), while real people mix in regional dialects every day. This article shows how swapping just one word into Egyptian or Gulf Arabic can trick cutting-edge language models, raising concerns for anyone who relies on Arabic AI in customer service, media monitoring, or online safety.
One language, many voices
Arabic is not a single, uniform way of speaking. MSA is used in schools, news, and official writing, but daily conversations rely on dialects such as Egyptian and Gulf Arabic. These varieties differ in vocabulary, word forms, and even sentence structure. For example, a simple word like “now” has very different forms across regions. To human readers, these variations are natural and easy to understand. For computer models trained almost entirely on MSA, however, dialect words can look unfamiliar, turning a clear sentence into something puzzling.
Turning dialects into a stress test for AI
To probe how fragile Arabic language models really are, the author designs a simple two-step test. First, a model is queried repeatedly to find the single word in a sentence that matters most for its decision—often a strong adjective, a key verb, or a topical noun. Second, that one word is replaced with an equivalent from Egyptian or Gulf Arabic using a large, carefully fine-tuned "dialectizer" model. The rest of the sentence is left intact, and the meaning remains the same for human readers. This makes the changed sentence a realistic adversarial example: a tiny, natural-looking tweak crafted to fool the system without altering the intended message.
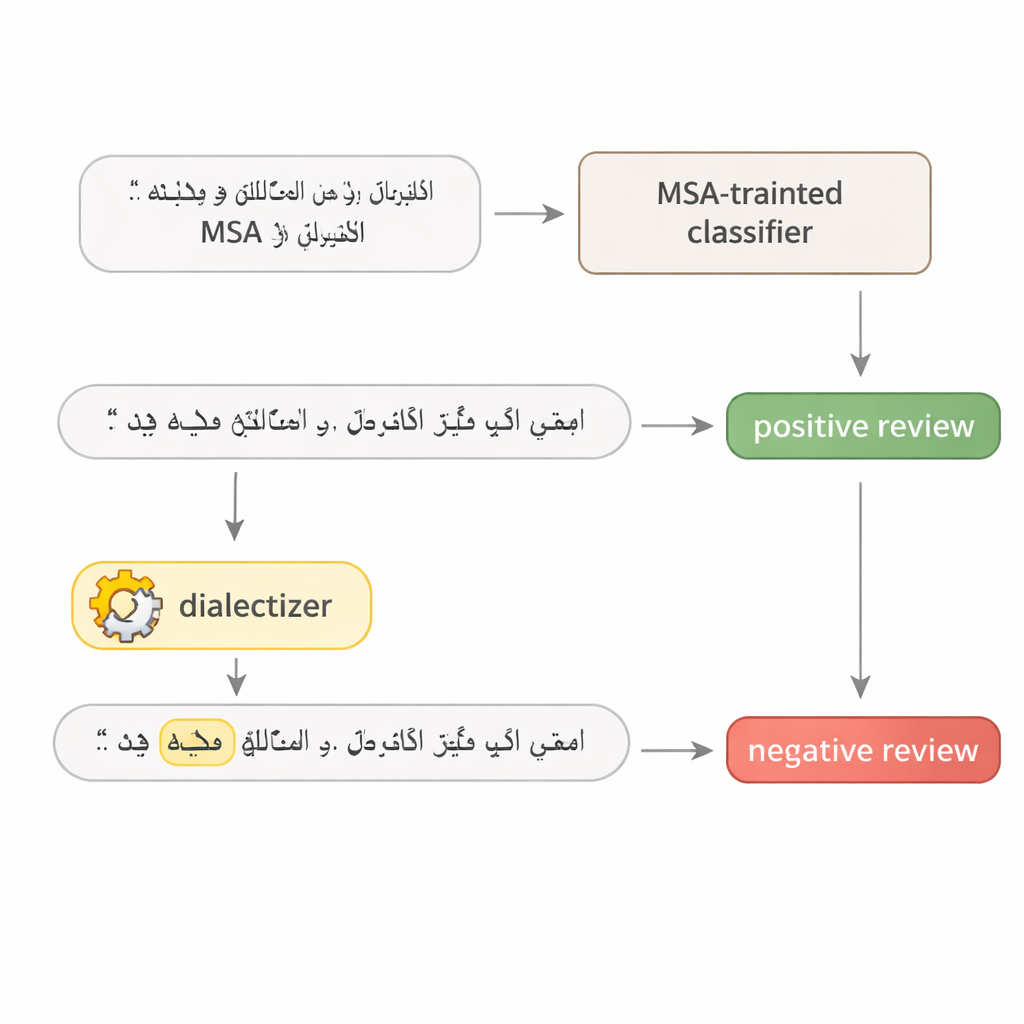
Putting hotel reviews and news stories to the test
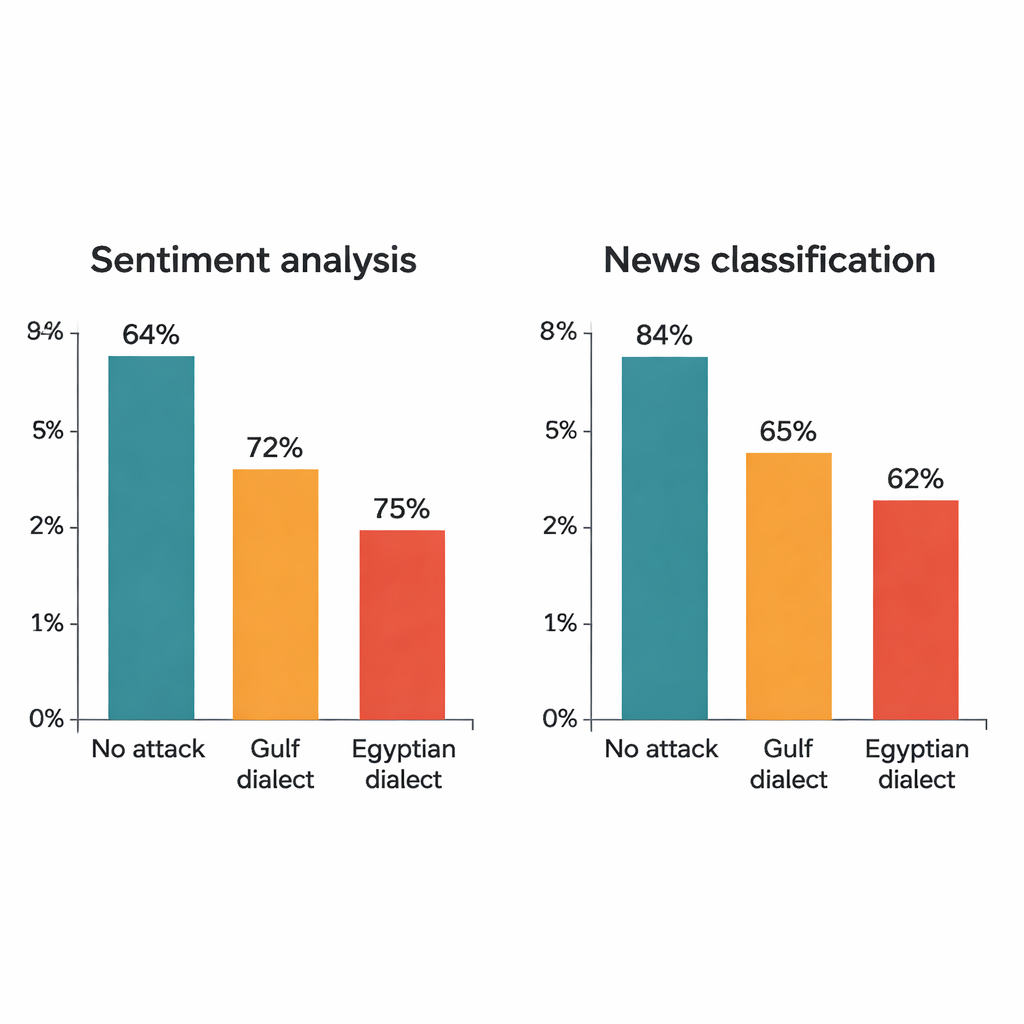
The study attacks four well-known deep learning models: two large transformer models (AraBERT and CAMeLBERT) and two smaller networks (a convolutional model and a bidirectional LSTM). They are trained on two major MSA datasets: hotel reviews for sentiment analysis and news articles for topic classification. From each test set, the author draws 1,280 examples and applies the dialectal substitution procedure. Even though only one word in each sentence is changed, the impact is striking. For hotel reviews, AraBERT’s accuracy drops from 94 percent on clean text to about 72 percent with Gulf substitutions and 65 percent with Egyptian ones. CAMeLBERT falls even further, down to roughly 63 and 55 percent. News classifiers also suffer: the convolutional model loses around 18 to 22 percentage points, and the LSTM shows similar declines.
What goes wrong inside the models
A closer look reveals that the most vulnerable words line up with how people actually read text. In hotel reviews, almost half of the targeted words are adjectives such as “good” or “terrible,” which carry clear emotional weight. In news articles, most selected words are nouns and names that signal topics like politics, sports, or finance. When those trigger words are swapped into dialect forms, models trained on MSA alone often fail to recognize them. Transformer models prove especially brittle: their reliance on subword fragments and attention to a few highly weighted tokens makes a single dialect word enough to overturn a prediction. Smaller models, which spread attention more evenly across a sentence, are still fooled but slightly more robust.
Egyptian versus Gulf: not all dialects are equal
The attacks also show that Egyptian Arabic tends to derail models more than Gulf Arabic. Linguistic studies back this up: Gulf varieties often stay closer to MSA in vocabulary and structure, while Egyptian Arabic has absorbed more distinct forms from history and contact with other languages. As a result, Gulf substitutions sometimes resemble the MSA original enough that the model can still cope, whereas Egyptian substitutions are more likely to fall outside what the model has seen before. Statistical tests confirm that the observed performance drops are not random—they reflect systematic blind spots in how current systems handle Arabic diglossia.
What this means for Arabic AI
For everyday users, the takeaway is simple: today’s Arabic AI can be easily confused by ordinary dialect words, even when humans find the text perfectly clear. A single dialectal term in a hotel review can flip a model’s judgment from positive to negative, or mislabel a news story’s topic. For researchers and developers, the message is a call to build "diglossia-aware" systems that train on both MSA and regional dialects, and to use realistic stress tests like dialectal substitution when judging robustness. Until then, any application that assumes “Arabic is just MSA” risks serious misunderstandings in the wild.
Citation: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Keywords: Arabic NLP, dialectal variation, adversarial examples, sentiment analysis, text classification