Clear Sky Science · en
Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems
Smart Surfaces for the Next Wave of Wireless
As our phones, cars, and sensors demand ever-faster and more reliable connections, today’s wireless networks are being pushed to their limits. This study explores a new way to make future 6G networks both greener and more dependable by combining "smart" reflecting surfaces on buildings with an artificial intelligence technique that learns, on its own, how to steer radio signals using less power.
Turning Walls into Helpful Signal Mirrors
Future 6G systems must serve huge numbers of devices with high data rates, rock-solid reliability, and very low delay. Meeting all those demands with traditional base stations alone would require a lot of extra hardware and energy. Reconfigurable Intelligent Surfaces (RIS) offer a different approach: panels coated with many tiny, low-power elements that can reflect incoming radio waves in controlled directions, like a programmable mirror. By carefully choosing the phases of these reflections, a RIS can redirect signals around obstacles, strengthen weak links, and reduce interference, all without actively transmitting its own power. This gives network designers a powerful new knob to turn when trying to expand coverage and improve efficiency.
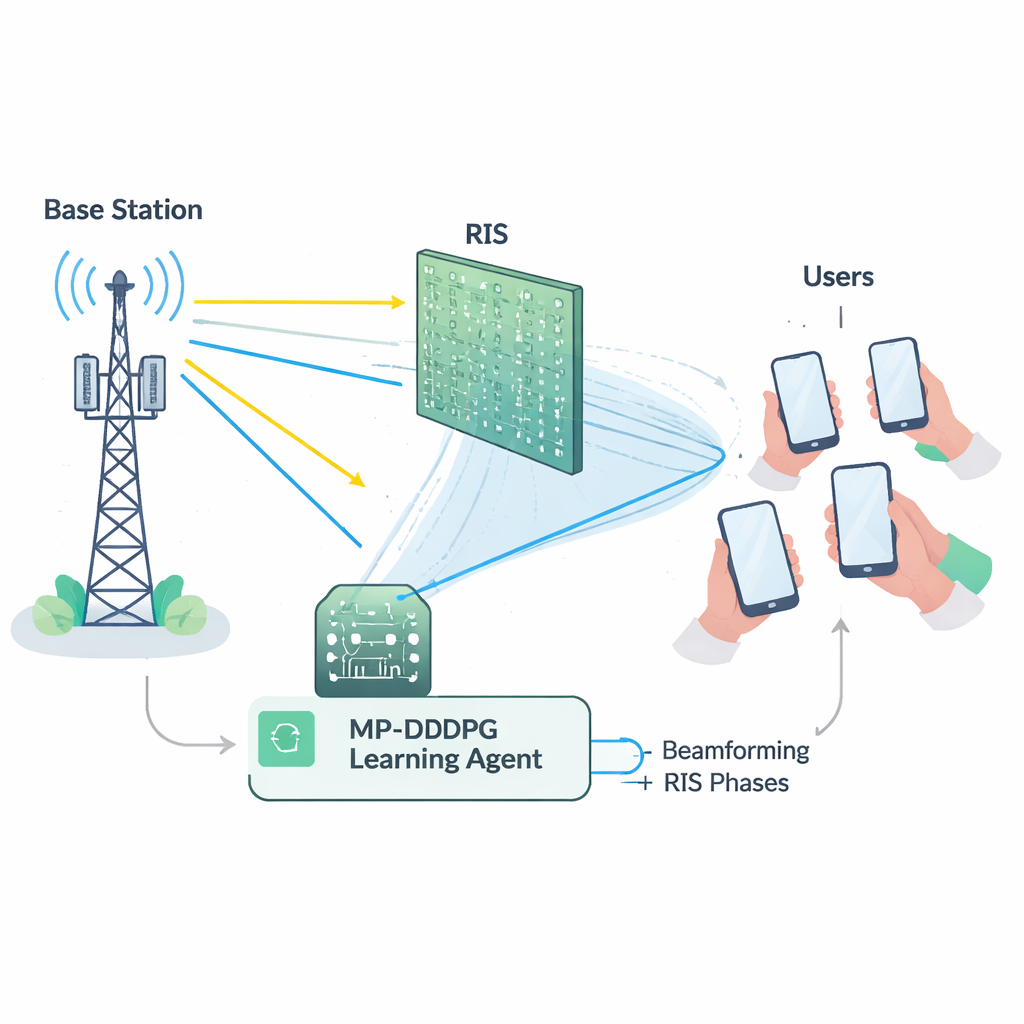
A Difficult Balancing Act for the Network
Making good use of a RIS is not straightforward. The base station has to decide how to point its antennas (beamforming), while the RIS must set the phase of each of its many reflecting elements. These choices are tightly connected, and they must satisfy several limits at once: keep the total transmit power below a maximum, guarantee each user a minimum signal quality, and respect physical limits on the RIS hardware. Mathematically, this joint tuning problem is highly non-linear and "non-convex," meaning that conventional optimization tools tend to be slow, fragile, or stuck in sub‑optimal solutions, especially as networks grow larger. On top of that, accurately measuring the detailed state of every radio link (the so‑called channel state information) is itself costly and error‑prone in real deployments.
Letting an AI Agent Learn How to Beam
To overcome these hurdles, the authors build a learning agent using deep reinforcement learning, a branch of AI where an agent discovers good strategies through trial and error with an environment. Their method, called Modified Prioritized Deep Deterministic Policy Gradient (MP‑DDPG), observes the current network status—previous beam directions, RIS settings, received power, and signal quality—and then chooses new beamforming and RIS phase values. After each choice, it receives a reward that encourages three things at once: lower transmit power, satisfaction of quality‑of‑service targets for users, and respect of the base station’s power limit. Over many simulated interactions, the agent gradually learns a control policy that balances these goals without being explicitly told any formula for the radio channel.
Learning Faster by Focusing on What Matters
The key innovation lies in how the algorithm learns from its past experience. Standard approaches store many past situations and sample them at random during training, which can be wasteful and slow. MP‑DDPG instead assigns each stored experience a priority that depends both on its reward and on how different its state is from its closest neighbors. Experiences that are both informative and diverse are sampled more often, while redundant ones are ignored. This "modified prioritized replay" makes each learning step more useful, speeding up convergence and helping the agent avoid poor local solutions. The authors also analyze the extra computation this adds and show that, although the bookkeeping is more complex than in the basic method, the faster learning more than compensates for it in practice.
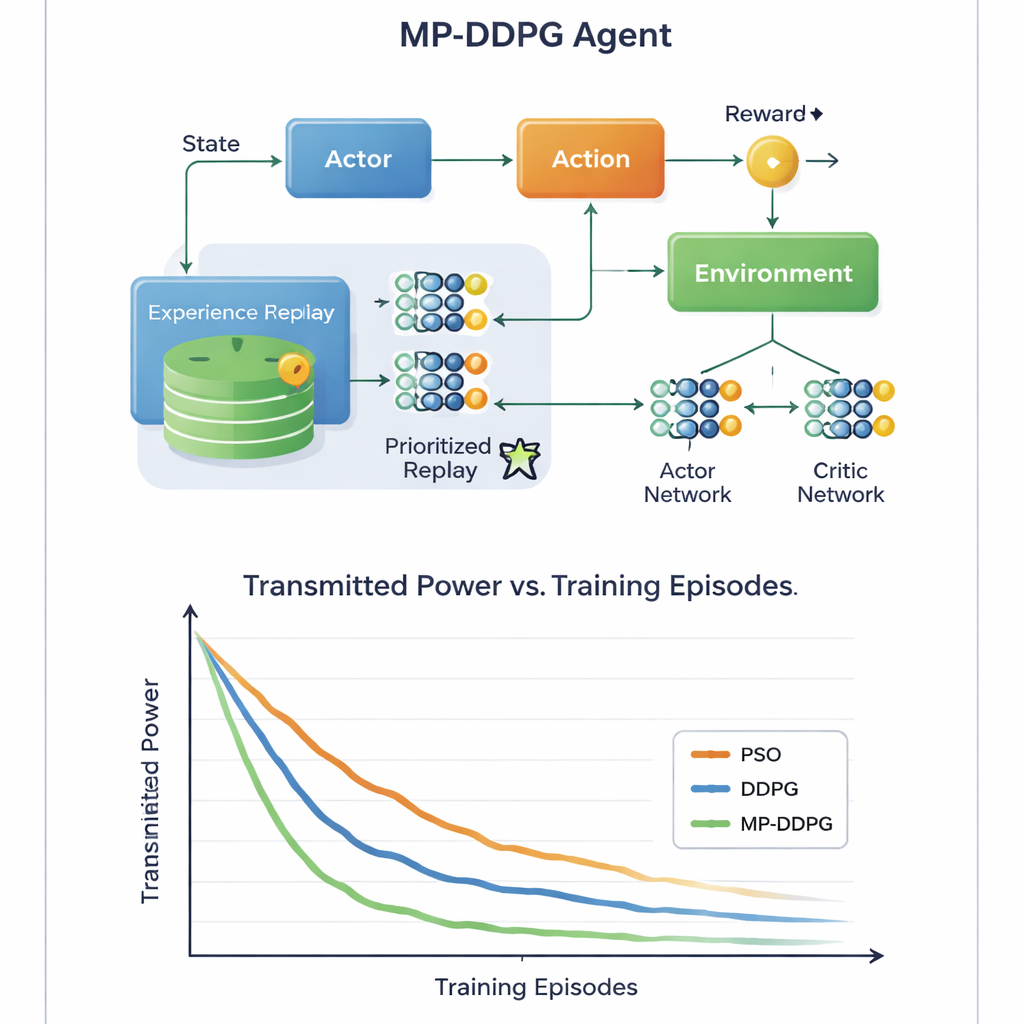
Greener Signals with Less Hardware
Through detailed computer simulations of a downlink cellular scenario, the study compares MP‑DDPG with two alternatives: a traditional particle swarm optimization method and the original DDPG learning algorithm. The new method consistently reaches lower transmit power in fewer training episodes, and it does so using fewer RIS elements and fewer base station antennas for the same performance level. In simple terms, the network learns to squeeze more benefit out of each reflecting tile and each antenna. For a lay reader, the message is that by letting an AI controller intelligently tune both the base station’s beams and the smart surfaces on nearby walls, future 6G networks could deliver strong, reliable signals using less energy and less hardware, helping make our increasingly connected world more sustainable.
Citation: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Keywords: reconfigurable intelligent surface, 6G wireless, deep reinforcement learning, beamforming optimization, energy-efficient networks