Clear Sky Science · en
Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs
Why this matters for energy and the environment
Oil and gas companies rely on measurements made down a borehole to decide where hydrocarbons are hiding and whether a field is worth developing. In many reservoirs, especially those rich in clay and silt, these measurements are notoriously hard to interpret, so engineers may underestimate how much oil or gas is actually there. This study presents a new way to squeeze more trustworthy information out of existing data by combining physics-based optimization with modern machine learning, potentially improving recovery while reducing the need for costly core samples.
The problem with muddy rocks
Many of the world’s hydrocarbon reservoirs are “shaley sands” – mixtures of sand grains, pore fluids, and conductive clay minerals. These clays distort electrical measurements used to estimate how much of the rock’s pore space is filled with water versus hydrocarbons. Classic tools and charts, developed for cleaner sands, assume simple rock fabrics and little clay. In shaley sands, those assumptions break down, often making the rocks look wetter than they are, and leading engineers to write off intervals that may actually hold significant oil or gas.
Turning sparse measurements into a solid anchor
The authors tackle a central quantity called formation water resistivity, which describes how well the water in the pores conducts electricity. If this value is off, every subsequent water saturation estimate is skewed. Instead of relying on a few laboratory measurements or subjective graphical methods, they pose the problem as an optimization task: find the single water resistivity value that makes a physics-based shaley-sand model best match the resistivity measured along the well. They test several search algorithms and show that simple, derivative-free methods such as Powell and Nelder–Mead can recover the true water resistivity with extremely small error when compared against core and water-sample data from 11 wells in the Norwegian North Sea and Egypt’s Western Desert.
Creating a “pseudo-core” log for machine learning
Once this optimized water resistivity is in hand, the same physical model is used to compute a continuous water saturation profile along each well. This profile is treated as a high-quality, physics-informed label – a kind of “pseudo-core” – that exists at every depth, not just at a few sampled intervals. The researchers then feed standard well logs, such as gamma ray, neutron porosity, density, and deep resistivity, into a wide range of machine learning models. These include tree-based ensembles (Random Forest, XGBoost, CatBoost), support vector machines, and several neural network architectures, including a special recurrent network called LSTM that can recognize patterns evolving with depth. Careful preprocessing, outlier screening, and normalization help ensure that the models learn genuine geological relationships rather than noise.
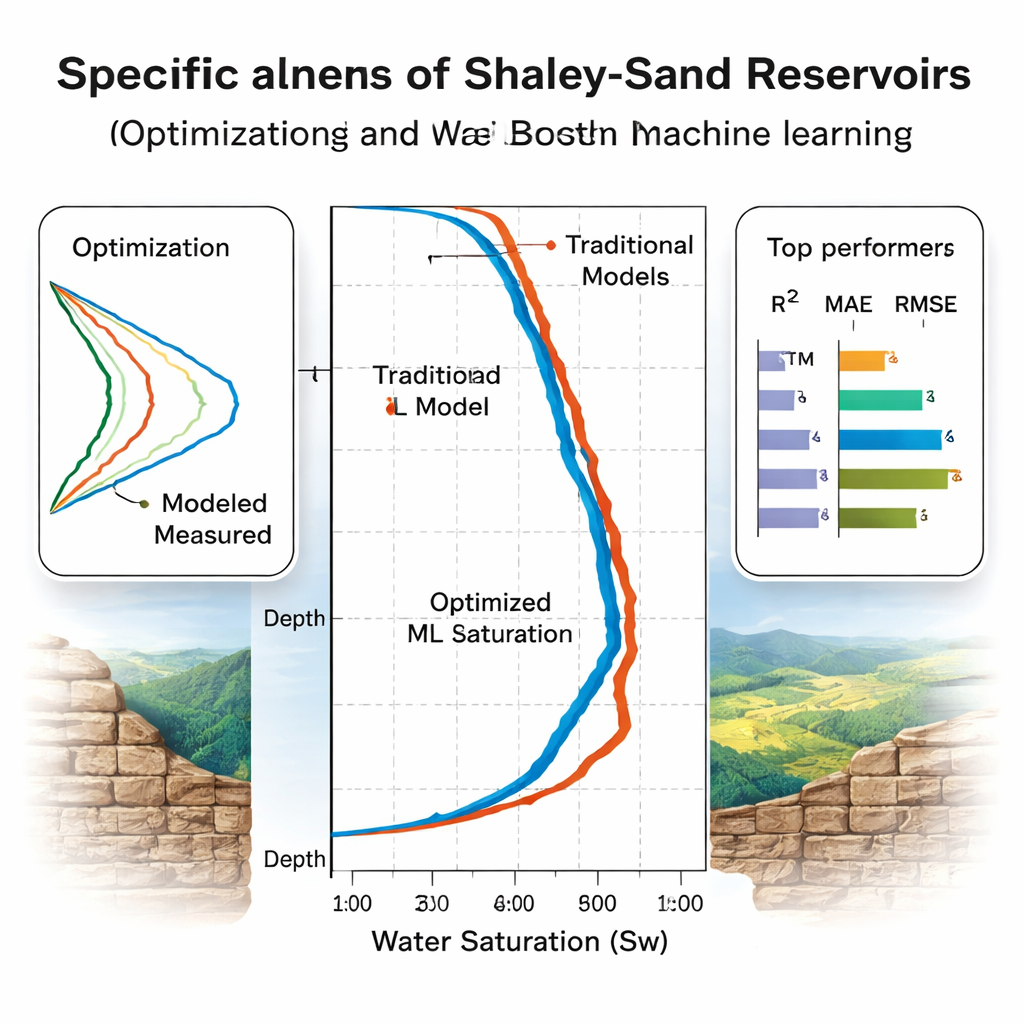
Which models really generalize?
The team evaluates the models in two stages. First, they use five-fold cross-validation on eight North Sea wells to tune and rank them, finding that Random Forest appears to win on standard accuracy scores. Then comes the more telling test: three “blind” wells, including two from a geologically different Egyptian basin that were never used in training. Here, some models stumble. Random Forest performance drops, signaling overfitting to the original basin. In contrast, gradient-boosted trees (CatBoost and XGBoost) and the LSTM and Bayesian-regularized neural networks maintain high accuracy, explaining over 93–94% of the variation in water saturation with modest errors. Feature-importance analysis using SHAP, a modern interpretability tool, confirms that the models lean most heavily on physically sensible inputs like resistivity, porosity, and shale volume.
What this means in plain terms
For non-specialists, the key idea is that the authors first use physics to clean up and anchor the problem, and only then unleash machine learning. By letting an optimization routine find the best-fitting water resistivity and then turning that into a dense, physics-respecting training set, they avoid the usual bottleneck of scarce and expensive core data. Their results show that this “optimization-first, ML-second” approach can deliver trustworthy estimates of how much of a shaley reservoir is filled with water versus hydrocarbons, even in new basins not used for training. In practical terms, this can help operators map out pay zones more reliably, reduce unnecessary coring, and improve estimates of hydrocarbons in place – all by making smarter use of data they are already collecting.
Citation: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Keywords: shaley sand reservoirs, water saturation, formation water resistivity, machine learning in petrophysics, reservoir characterization