Clear Sky Science · en
Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection
Why smarter cameras matter
From busy train stations to shopping malls, modern life is filled with security cameras quietly recording everything that happens. Yet most of these videos are still watched—if at all—by tired human eyes that can easily miss a crucial moment. This paper explores a new kind of "smart" surveillance system that can automatically spot unusual or risky behavior, such as theft or vandalism, in real time by understanding both what appears in a scene and how it changes over time.

Seeing more than pixels
A traditional camera feed is just a sequence of pictures. Older computer systems tried to detect trouble by looking at each frame separately, searching for shapes and edges that resembled people or objects. The authors first test a modern version of this idea that uses a compact image-recognition network combined with classic edge detectors. This setup works fairly well in neatly framed scenes, especially for noticing clear visual cues like someone grabbing an item. But because it focuses on single snapshots, it struggles when people block each other, when crowds get dense, or when the same pose can mean either normal or suspicious behavior depending on how it unfolds over time.
Understanding motion and behavior
To capture the story behind an action, not just the appearance of a single frame, the study then evaluates a video-focused model that analyzes short clips instead of still images. This model learns how motion flows across several frames and can better identify sudden changes like running, fighting, or snatching. It proves good at catching many abnormal events, which leads to high sensitivity. However, it also suffers from a classic real-world problem: truly unusual events are rare compared with everyday activity. As a result, the model can become unstable, raising too many false alarms and requiring carefully pre-cut video segments that do not reflect the messy, continuous nature of real surveillance footage.
Blending where and when
Building on the strengths and weaknesses of these two baselines, the authors propose a new hybrid system called HybridModel-1 that aims to “think” both in space and time at once. It combines a network that is very good at understanding what objects are present in each frame with a fast detector that locates those objects in the scene. A special fusion module learns to emphasize the most informative visual details—such as people and key objects—while downplaying background clutter like walls, trees, or passing cars. At the same time, a new training strategy gently punishes the system whenever its confidence jumps wildly from one frame to the next, nudging it toward smoother, more consistent decisions across a whole video.
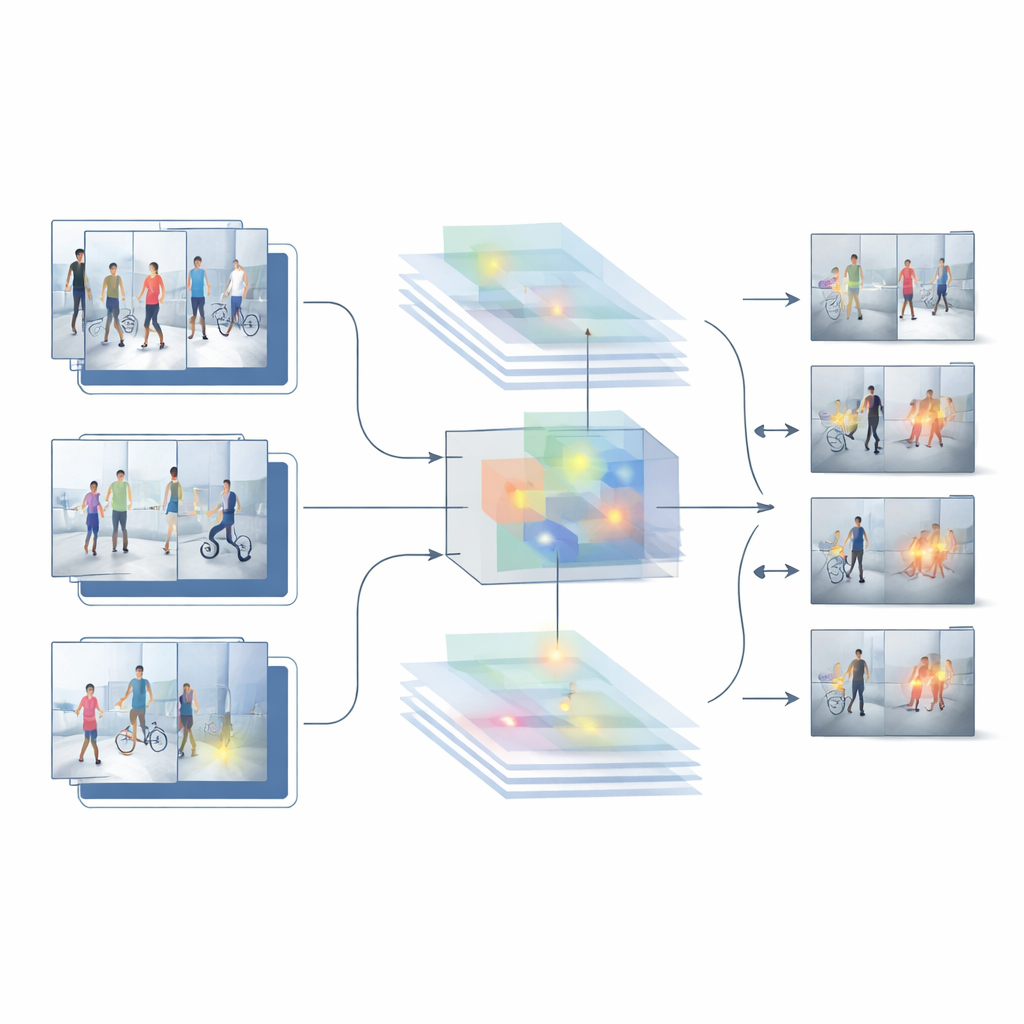
Putting the system to the test
To see whether this design works outside the lab, the researchers test it on several challenging public datasets of real surveillance footage. These collections include everything from indoor theft scenes to outdoor campus walkways, with varying camera positions, lighting, crowd sizes, and types of incidents. Across these benchmarks, the hybrid model outperforms both the image-only and video-only baselines. It achieves higher overall accuracy, makes far fewer false alarms, and maintains strong performance even when evaluated on footage it was not trained on. Detailed comparisons and ablation studies—where pieces of the system are removed or altered—show that the feature-fusion module and the smoothness-focused training step each contribute meaningfully to these gains.
What this means for everyday safety
In simple terms, this work shows that surveillance systems become more reliable when they learn to pay attention to the right parts of a scene and remain steady in their judgments over time. Instead of treating each frame as an isolated image or relying solely on raw motion, the proposed approach blends "what" and "when" in a single, carefully tuned framework. While challenges remain in extremely dark or heavily blocked views, the results suggest a practical path toward camera networks that can quietly screen vast amounts of video, surface genuinely suspicious events, and reduce the burden of false alarms for human operators. For the public, that could mean safer spaces monitored by systems that are not just watching, but truly understanding what they see.
Citation: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Keywords: video surveillance, anomaly detection, smart cameras, crime detection, machine learning