Clear Sky Science · en
Cross-well machine learning prediction of sonic logs in Newfoundland and Labrador
Listening to Rocks Without a Microphone
Oil and gas companies rely on acoustic "sonic" tools to listen to how sound waves travel through underground rocks. These detailed measurements help engineers judge rock strength, plan safe wells, and match drilling data with seismic surveys. But sonic tools are expensive, can slow operations, and sometimes cannot be run at all. This study shows how machine learning can reconstruct sonic information from cheaper, routinely collected measurements, offering a way to "hear" the subsurface even when the microphone is missing.
Why Predicting Sonic Data Matters
In offshore drilling, operators record many types of well logs: natural radioactivity, drilling speed, pump rate, weight on the drill bit, and more. Sonic logs are special because they reveal how fast sound travels through rock, a key input for estimating rock stiffness, pressure, and stress. When sonic tools are not available, engineers must either work with gaps or rely on crude rules of thumb. By using machine learning to turn common non-sonic logs into accurate "pseudo-sonic" curves, companies can cut data acquisition costs, fill missing sections, and still make informed decisions about well stability and reservoir behavior.
A Careful Recipe to Avoid Cheating
The authors worked with data from two offshore wells in Newfoundland and Labrador. For each depth, they tried to predict compressional slowness (a way of expressing how long a sound wave takes to travel through rock) using only non-sonic measurements. Crucially, they banned any input that directly or indirectly used sonic data, such as derived elastic properties. They also built features using only information from the same depth or shallower depths, mimicking real-time drilling where the future is unknown. Outliers in the sensor readings were identified using statistics from just one "training" well and then handled in both wells the same way, ensuring the models could not quietly learn from the test data. All scaling and feature choices were also fixed on the training well before being applied, unchanged, to the other well.
Turning Raw Logs Into Learnable Signals
Simply feeding raw logs to an algorithm is rarely enough. The team engineered a rich set of depth-aware features: they tracked how each log changed with depth, smoothed noisy signals at several scales, and computed slopes and curvatures that highlight local trends. They also expressed depth relative to segments of the hole, capturing patterns that repeat when bit size changes. To keep the models from being overwhelmed, they ranked features using three different methods and combined the rankings into a single ordered list. A compact group of the most informative features was then chosen using a time-aware split within the training well, so that the process itself respected the natural ordering with depth.
Tree-Based Models Beat Deep Learning
The study compared three types of models: Random Forests, XGBoost (a popular gradient-boosting method), and bidirectional LSTM neural networks, which are often used for sequence data. Each model was trained on one well and tested blindly on the other, a demanding setup that exposes differences between wells in depth range, operating conditions, and rock types. Under this test, XGBoost performed best, achieving high agreement between predicted and measured sonic logs when trained on the first well and applied to the second. Random Forests were close behind and sometimes more stable in noisy zones. LSTM networks, despite their complexity, lagged in both accuracy and robustness, likely because there were only two wells and the data varied strongly with depth, conditions that do not favor large neural networks.
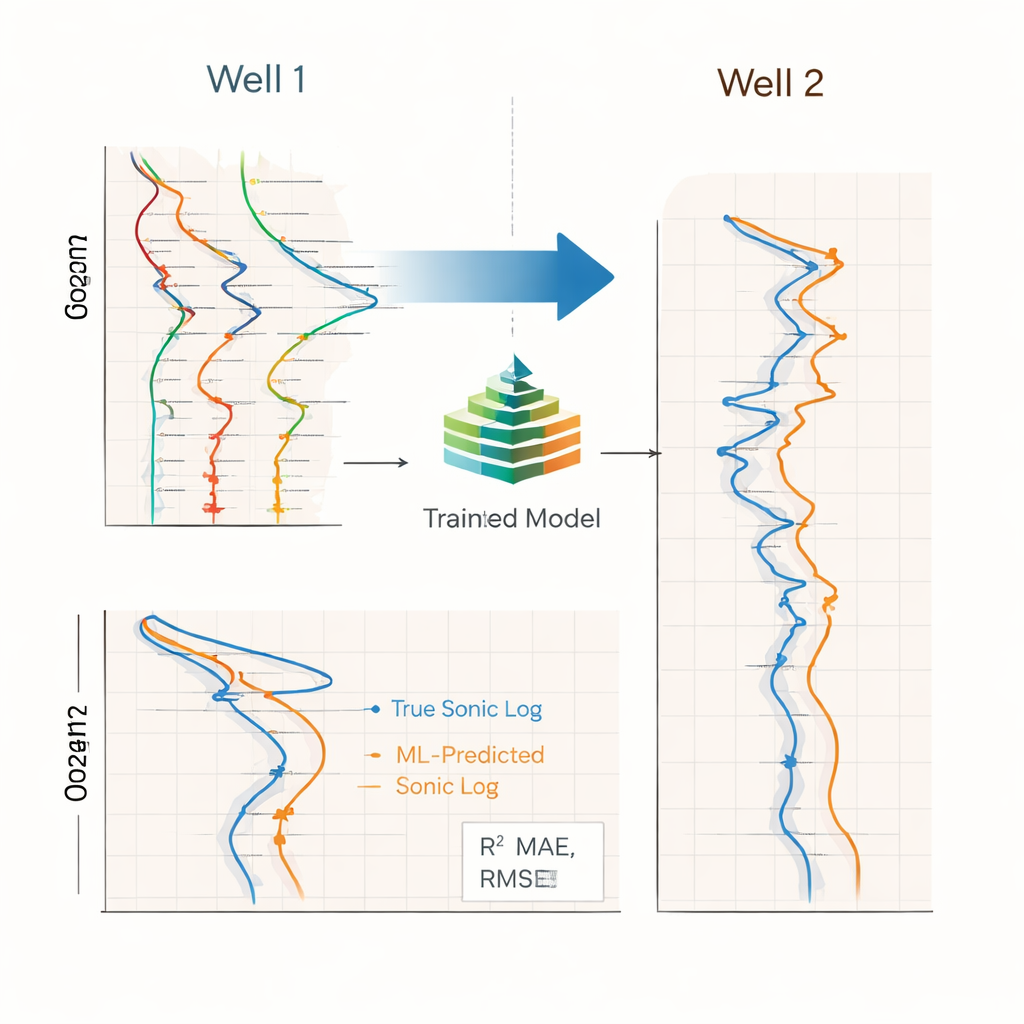
What Drives Accuracy and Where It Helps
By turning different pieces of their preprocessing on and off, the authors showed that smart feature generation and selection made the biggest difference in performance, more than simply adding longer history windows or basic outlier filtering alone. When these steps were included, both tree-based models generalized much better across wells. The resulting pseudo-sonic logs were accurate enough to support downstream tasks such as estimating rock stiffness, modeling pore pressure and stress, calibrating seismic data, and planning wells in zones where direct sonic measurements are missing, delayed, or unreliable. Because all transformations are fixed on a reference well and then reused, the workflow could operate nearly in real time while drilling.
Take-Home Message for Non-Specialists
This work shows that with disciplined data handling and well-chosen machine learning models, it is possible to recreate high-value sonic information from cheaper drilling and logging channels in a new well that the model has never seen. The approach does not replace dedicated sonic tools, especially where safety margins are tight, but it offers a practical and cost-effective backup, as well as a quality check when measured data look suspicious. As more wells and regions are added and newer models are tested under the same strict rules, this kind of cross-well prediction may become a standard part of the digital toolkit for safer, more efficient offshore drilling.
Citation: Zare, B., Huque, M.M., James, L.A. et al. Cross-well machine learning prediction of sonic logs in Newfoundland and Labrador. Sci Rep 16, 5292 (2026). https://doi.org/10.1038/s41598-026-36053-9
Keywords: machine learning, sonic logs, well logging, offshore drilling, reservoir characterization