Clear Sky Science · en
Autonomous navigation in unstructured outdoor environments using semantic segmentation guided reinforcement learning
Robots Learning to Hike the Woods
Imagine a small robot that can hike a forest trail on its own, weaving between trees and rocks without GPS or a human holding a joystick. This paper describes a system that teaches such robots to "see" paths in dense woods and decide, moment by moment, how to move safely forward. The work matters for future robots that could help with forest monitoring, wildfire prevention, search-and-rescue, and even outdoor delivery in places where satellite signals are weak or nonexistent.
Why Forests Are So Hard for Robots
Forests are some of the toughest places for autonomous machines. Trails can be narrow and winding, the ground is uneven, branches and bushes often block the view, and tall trees make GPS signals unreliable. Traditional navigation methods depend on precise maps, strong GPS, or expensive laser sensors, and often assume clear, structured spaces like city streets or factory floors. In the woods, these assumptions break down: shadows, changing seasons, and thick vegetation confuse simple vision systems, while rule-based controllers struggle to cope with all the messy, unexpected situations that arise on a real trail.
Three Brains Working Together
The authors propose a hybrid navigation system that gives robots three complementary "brains." First, a deep vision module examines each camera image and marks, almost pixel by pixel, which parts belong to the walkable trail. Second, a learning-based decision module uses reinforcement learning to choose smooth steering and speed commands, rewarding behavior that stays on the trail, avoids collisions, and reaches the goal efficiently. Third, a classical controller converts the predicted trail shape into stable wheel motions, ironing out sudden moves and keeping the robot’s path graceful rather than jerky. Instead of a single, opaque end-to-end network, these modules are separate but tightly linked, allowing engineers to understand and debug each stage.
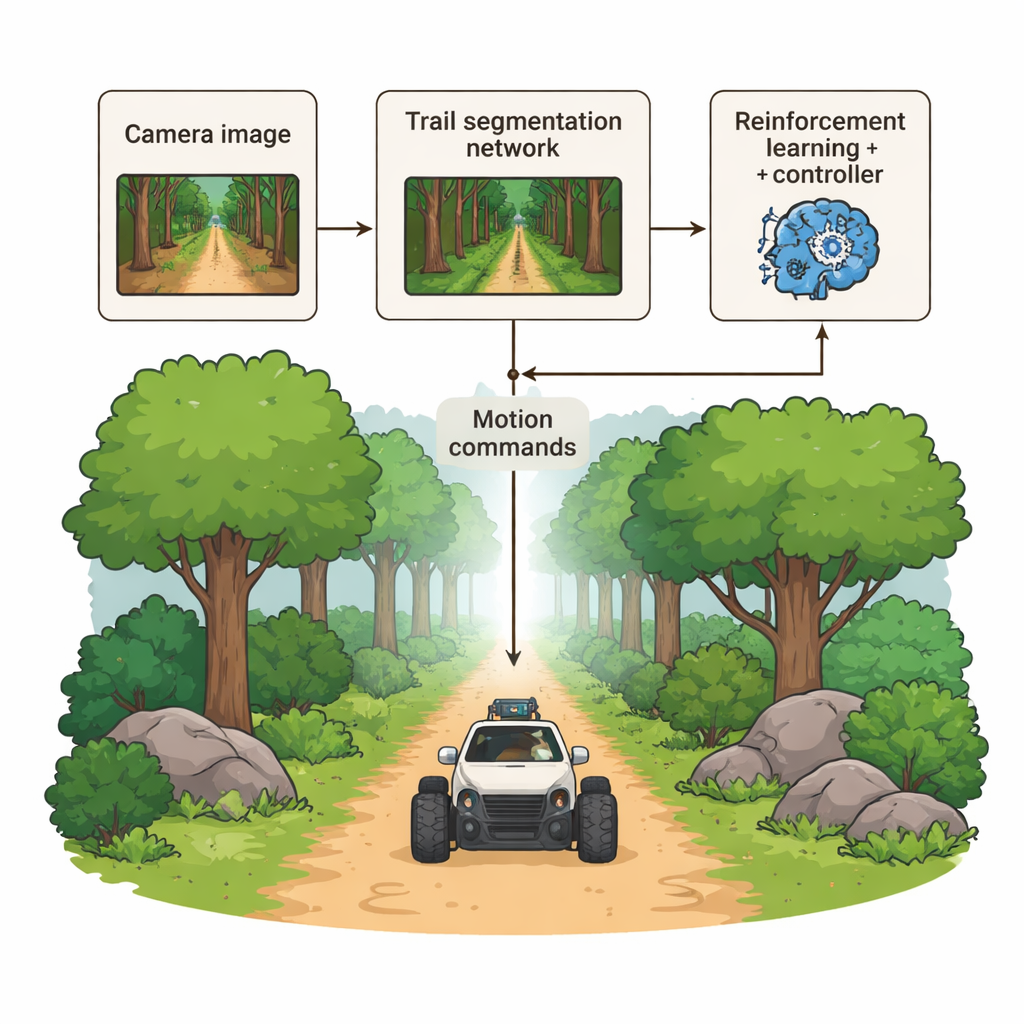
Teaching Vision to Recognize Trails
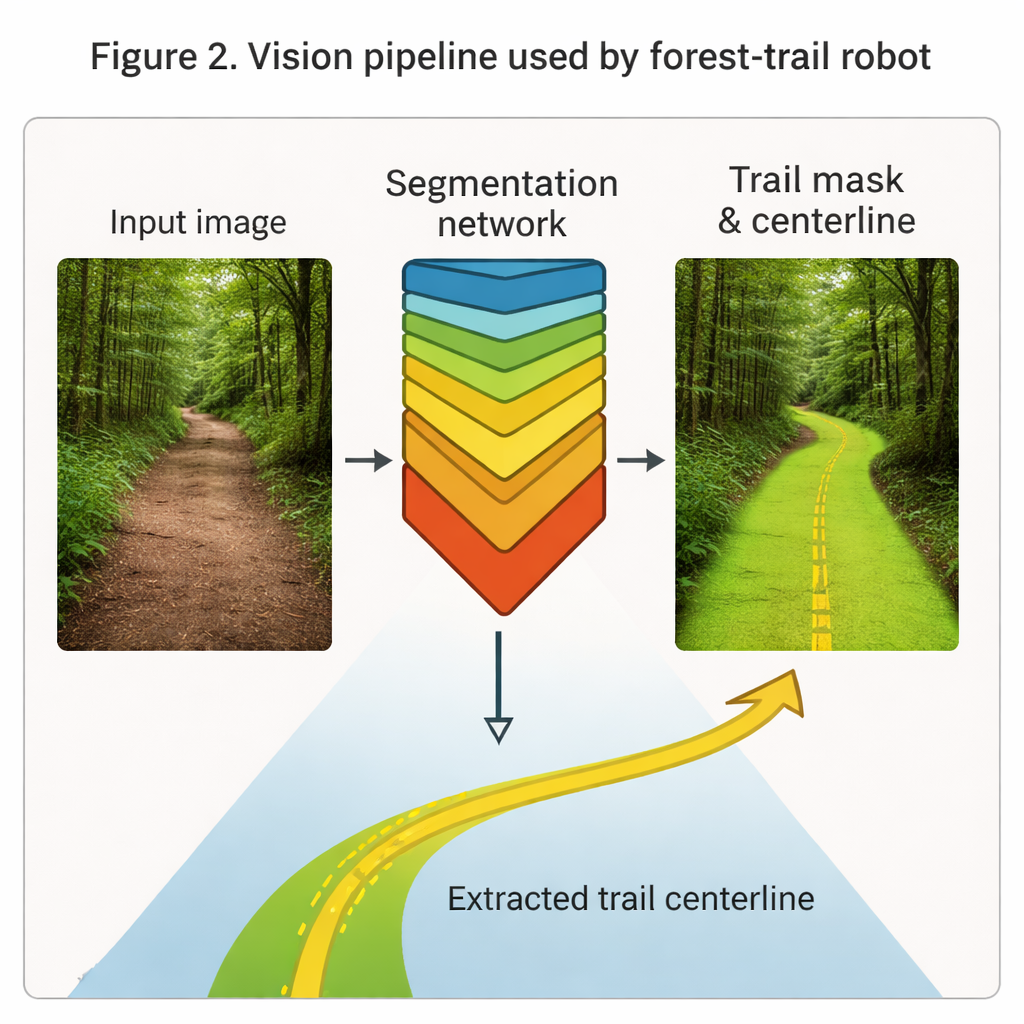
At the heart of the robot’s "eyes" is a deep network known as Mask R-CNN, here tuned to highlight forest trails in ordinary color images. Trained on nearly 24,000 labeled frames of real hiking footage shot from human height under varied light, weather, and trail types, the system learns to paint the trail region in each frame as a clean mask. From this mask it extracts a thin centerline curve that captures the direction and curvature of the path ahead. In tests, the vision module achieves high overlap with human-drawn labels and over 90% pixel accuracy, robustly outlining trails even when branches or shadows partially hide the way. These geometric cues feed directly into both the learning and control modules as a compact description of "where the path is."
Training a Robot to Make Good Choices
The second key piece is the decision module, which uses a technique called reinforcement learning. Instead of being told exactly what to do, the robot tries actions in a realistic simulated forest and gets rewards for good outcomes and penalties for bad ones. Moving forward along the trail is good; drifting away, colliding with obstacles, or getting stuck is bad. Over about 150,000 training steps, the system gradually discovers strategies that keep it centered on the trail, handle bends gracefully, and react sensibly when branches or rocks appear in its way. To keep motions smooth and safe, the learned actions can be blended with those from the classical controller, which is especially helpful in tight curves or noisy conditions.
Putting the System to the Test
To judge how well this combination works, the researchers built three detailed virtual forests: one with narrow, cluttered trails, another with steep, uneven ground and large obstacles, and a third filled with forks, dead ends, and distracting false trails. Across 90 trials in these maps, the robot reached its goal without collision in about 87% of episodes, with an average of only 0.2 bumps per run and typically staying within about 30 centimeters of the trail center. It also finished routes quickly and consistently. When the authors removed or simplified one module at a time, performance dropped sharply—showing that all three components are necessary. Compared with other recent systems, including those using laser scanners, this vision-only hybrid approach delivered the best overall blend of success rate, precision, and safety.
What This Means for Real-World Robots
For a non-specialist, the takeaway is that robots are getting better at hiking like cautious, competent trail users. By combining a strong sense of visual context ("this is the path"), practice-based decision making ("these moves worked well before"), and a steady steering mechanism, the proposed system lets a small wheeled robot navigate complex forests without maps or GPS. While the work was tested in simulation and still faces challenges like extreme lighting and rare trail types, it offers a practical blueprint for future field robots that can safely share wild environments with people, helping us inspect forests, support rescue teams, and manage natural resources more effectively.
Citation: Tibermacine, A., Tibermacine, I.E., Akrour, D. et al. Autonomous navigation in unstructured outdoor environments using semantic segmentation guided reinforcement learning. Sci Rep 16, 2633 (2026). https://doi.org/10.1038/s41598-026-36022-2
Keywords: autonomous navigation, forest robotics, computer vision, reinforcement learning, semantic segmentation