Clear Sky Science · en
The multi-parameter optimized belief rule base for predicting student performance with interpretability
Why predicting grades is everyone’s business
Report cards may look simple, but the forces that shape a student’s grades are anything but. Schools increasingly turn to computer models to spot struggling students early and guide support. Yet many of these models are “black boxes”: they can be accurate, but even teachers and parents cannot see why a prediction was made. This paper presents a new approach that aims to be both highly accurate and easy to understand, so that educators can trust and act on its results.
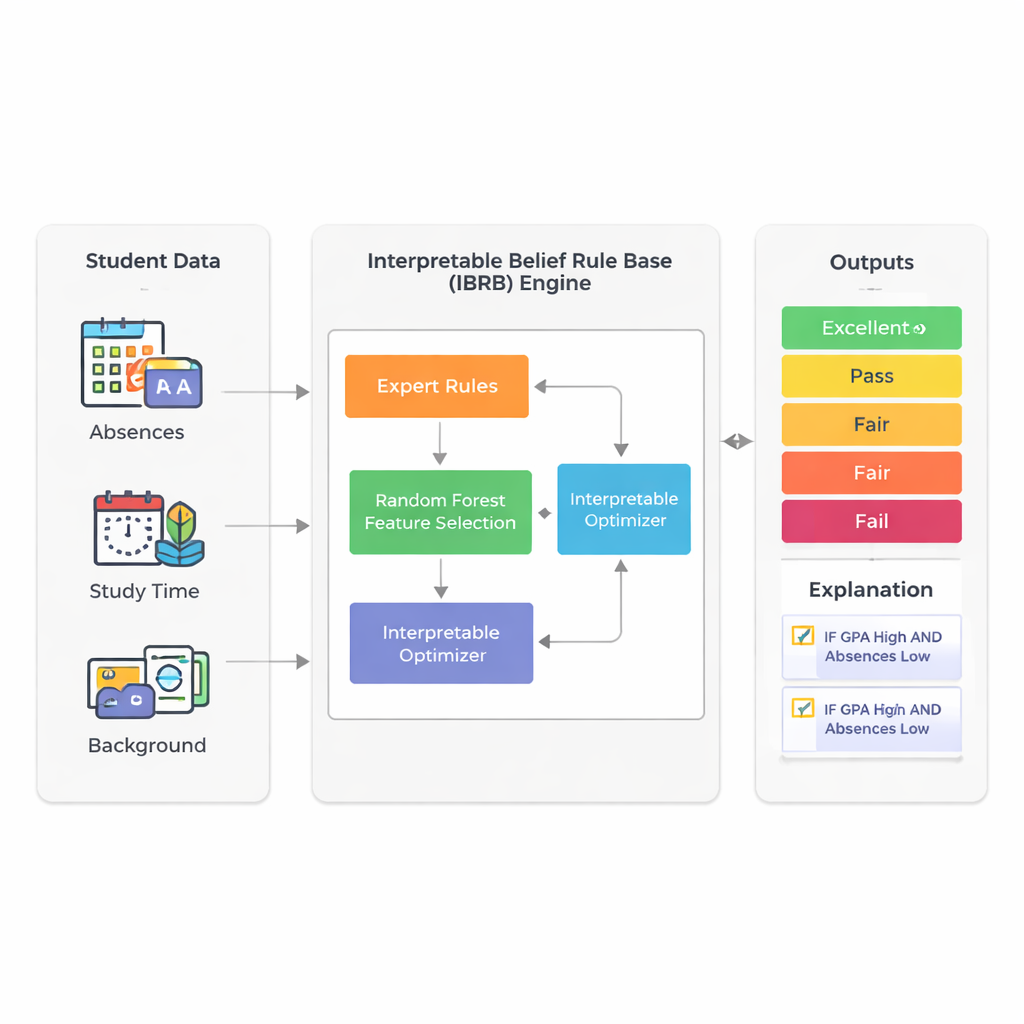
A smarter way to read the signals
The study focuses on predicting how well students will ultimately perform by using the information schools already collect: grade point average (GPA), absences, study time, background, and family and activity factors. Instead of relying on opaque deep-learning systems, the authors build on a technique called a belief rule base. In this framework, experts write rules that look a lot like what a teacher might say: “If GPA is high and absences are low, then the student is likely to do well.” Each rule carries a degree of belief about possible outcomes such as Excellent, Good, Pass, Fair, or Fail. This makes the reasoning process visible and, in principle, explainable to non-experts.
Taming complexity without losing meaning
A major challenge with rule-based systems is that they can grow out of control when many student attributes are included: every extra factor multiplies the number of possible rules. To avoid this “rule explosion,” the researchers first use a random forest—a widely used ensemble of decision trees—to measure which features matter most for predicting performance. In their real dataset of 2,392 students from a public source, GPA and number of absences account for about 73% of the model’s predictive power. By deliberately keeping only these two inputs, the final model stays compact and easier to interpret, while still reflecting most of the variation in student outcomes.
Building rules that people can follow
The core of the new model, called IBRB-m, is a carefully structured set of 25 rules combining levels of GPA and absences with belief degrees for the five performance categories. The authors formalize what it means for such a model to be “interpretable.” Among their requirements: every reference level (such as “low GPA”) must cover a clear and distinct range; the rule base must cover all realistic combinations of inputs; parameters like rule weights and attribute weights must have down-to-earth meanings; and the system’s internal calculations must transform information in a transparent, mathematically consistent way. On top of these traditional conditions, they add education-specific guidelines that force the model’s predictions to follow commonsense shapes—for example, avoiding bizarre cases where a student is judged simultaneously very likely to excel and to fail.
Letting data fine-tune what experts say
Human experts do not always agree, and their initial rules can be imprecise. To refine these rules without turning the model into a black box, the authors design an improved optimization algorithm that searches for better parameter values while obeying strict interpretability constraints. This algorithm adjusts not only rule weights and belief degrees but also the cut-off points that define categories like Excellent or Pass. It keeps all changes within expert-approved bounds and enforces reasonable, smooth belief patterns across grades. In effect, the computer “nudges” the expert system towards higher accuracy, but is not allowed to invent rules that would puzzle a knowledgeable teacher.
How well does it work in practice?
Tested on the Kaggle student performance dataset, the IBRB-m model correctly predicts final performance levels in more than 99% of cases, outperforming both earlier belief-rule systems and common machine-learning tools such as neural networks, random forests, and k-nearest neighbors. Just as important, the optimized rules remain close to the original expert assessments when measured by a simple distance metric, which means the reasoning behind each prediction can still be traced and justified. Cross-validation across multiple splits of the data shows that the model’s performance is stable, not a fluke of a lucky partition.
What this means for classrooms
For lay readers, the main takeaway is that it is possible to have student prediction tools that are both powerful and understandable. Rather than issuing mysterious risk scores, the model can highlight concrete patterns like “moderate GPA but frequent absences” and show how these feed into a Fair or Fail prediction. Teachers and counselors can then respond with targeted actions—such as attendance support or study-skills coaching—while confidently explaining to students and parents why the model reached its conclusion. The authors argue that this blend of accuracy and transparency is essential if data-driven systems are to play a trusted role in promoting fair and effective education.
Citation: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Keywords: student performance prediction, interpretable AI, belief rule base, educational data mining, Explainable machine learning