Clear Sky Science · en
HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention
Teaching Computers to Read Body Language
From fitness apps to driver-assistance systems, many technologies now rely on a computer’s ability to understand how people move. This skill, called human pose estimation, means finding the positions of body joints—like shoulders, knees, and ankles—in an image or video. The challenge is to do this both accurately and fast enough for real-time use on everyday hardware. This paper introduces HEViTPose, a new method that aims to keep high accuracy while using less computing power than many current systems.
Why Finding Joints in Pictures Is So Hard
At first glance, locating body joints might seem simple: just look for arms and legs. In practice, people appear at different sizes, in unusual poses, in crowded scenes, and often behind objects such as furniture or cars. Modern pose-estimation systems usually handle this by creating a detailed “heatmap” for each joint, where bright spots mark likely positions. Heatmaps are very precise but expensive to compute. Traditional systems rely mainly on convolutional neural networks, which are good at spotting local patterns but must grow deeper and heavier to capture long-range relationships across the whole body. More recent transformer-based models excel at capturing those long-range links, yet they often need large datasets and heavy computation, making them harder to use in real-time or on smaller devices.
Overlapping Glimpses for Smoother Vision
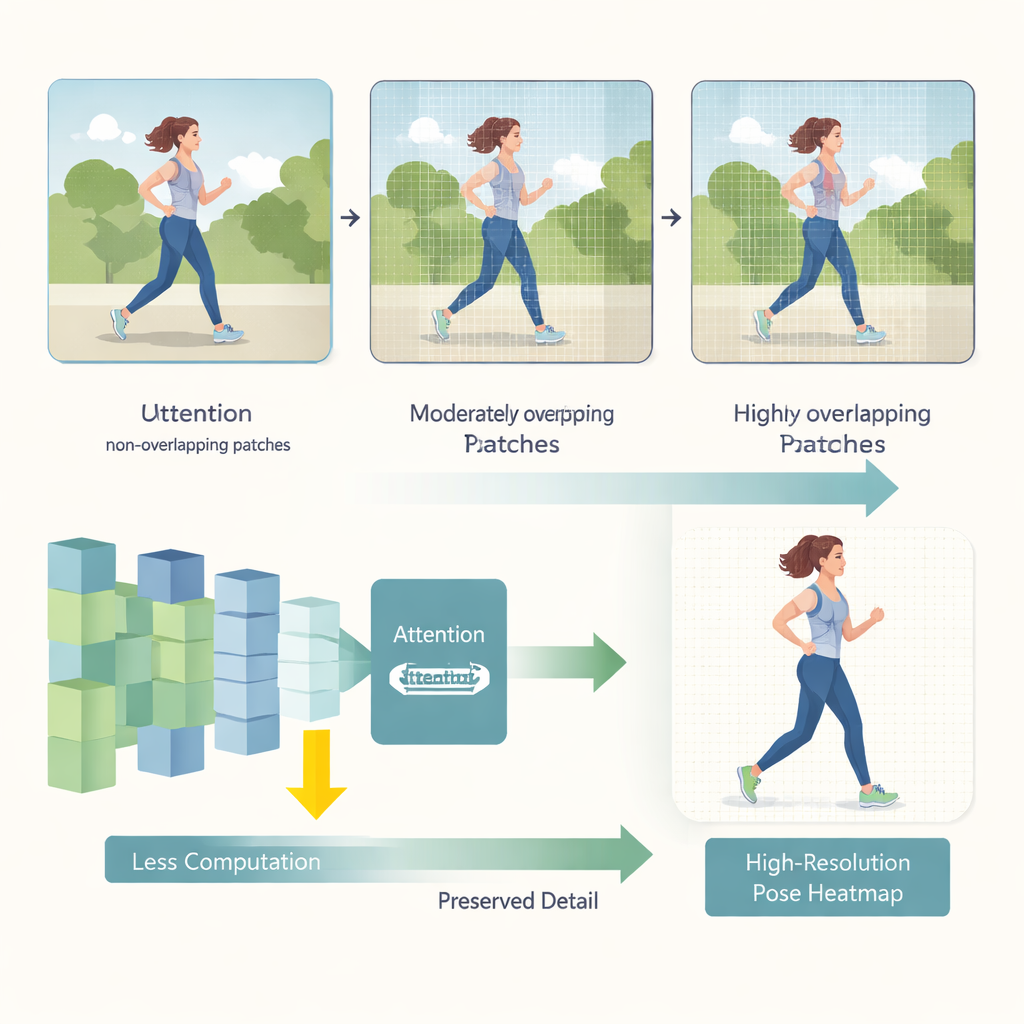
HEViTPose starts by rethinking how an image is broken into pieces for analysis. Earlier transformer models often chop images into non-overlapping tiles, which can break the visual continuity between neighboring regions—like cutting a person’s arm at the edge of a patch. HEViTPose builds on an idea called overlapping patch embedding and introduces a clearer, tunable measure named Patch Embedding Overlap Width (PEOW). PEOW simply counts how many pixels neighboring tiles share along their borders. By systematically varying this overlap, the authors show that moderate overlap allows the network to better “feel” the smooth change of color and shape from one tile to the next. That richer local continuity leads to more accurate joint locations, without blowing up the model size or computation.
Smarter Attention with Less Work
The second key innovation is a new attention module called Cascaded Group Spatial Reduction Multi-Head Attention (CGSR-MHA). Attention mechanisms tell the network which parts of the image should influence each prediction, but they typically scale poorly as images grow larger. CGSR-MHA tackles this in three ways. First, it splits features into groups, so each group handles only a portion of the information instead of everything at once. Second, it shrinks the spatial resolution inside each group before computing attention, greatly cutting the number of operations. Third, it uses several small attention heads rather than a few large ones, preserving diversity in what the model can “pay attention” to while keeping the cost low. Carefully chosen settings for how many groups to use, how much to shrink, and how many heads to include strike a balance between speed and accuracy.
Lightweight Models That Still Compete at the Top
To test HEViTPose, the authors evaluate it on two widely used benchmarks: the MPII dataset of everyday human activities and the larger COCO dataset with people in many different scenes. Across several model sizes, HEViTPose matches or nearly matches the accuracy of leading pose-estimation systems while using far fewer parameters and less computation. For example, one version reaches similar accuracy to a popular high-resolution network (HRNet) while cutting the number of learned parameters by more than 60% and reducing the amount of computation by over 40%. Compared to another modern hybrid model that mixes convolutions and transformers, HEViTPose delivers similar performance but runs about 2.6 times faster on a graphics processor. These savings translate directly into smoother real-time performance and lower hardware requirements.
What This Means for Everyday Applications
In simple terms, HEViTPose shows that we do not have to choose between accuracy and efficiency when teaching computers to read human body language. By carefully overlapping the image pieces it examines, and by redesigning how attention is computed inside the network, the system can pinpoint joints with high precision while remaining compact and fast. This makes it attractive for real-world uses such as sports tracking, video surveillance, human–robot interaction, and in-car monitoring, where both speed and power consumption matter. The ideas behind HEViTPose—smarter overlap and efficient attention—could also be adapted to related tasks like animal pose tracking or facial landmark detection, potentially bringing sharper “digital eyes” to many devices without requiring supercomputer-level hardware.
Citation: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Keywords: human pose estimation, computer vision, vision transformer, efficient deep learning, attention mechanism