Clear Sky Science · en
A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features
Why Your Voice Can Be a Digital Key
Imagine unlocking your bank account, front door, or phone using nothing but your voice. For that to be safe, computers must reliably tell one person from another, even when there is background noise, emotion, or a bad microphone. This paper explores a new way to teach machines to recognize who is speaking, not just what they are saying, by combining modern deep-learning tricks with a form of trial-and-error learning borrowed from robotics.
From Sound Waves to Voice Fingerprints
Every person’s voice carries subtle clues shaped by the size and shape of their vocal tract, how their vocal folds vibrate, and their speaking style. The researchers began by asking: which measurable properties of recorded speech actually differ from one person to another? Using 2,703 audio clips from 40 English speakers in the LibriSpeech dataset, they analyzed 22 simple acoustic features, such as loudness variation, energy in different frequency bands, rhythm, and a measure called entropy that captures how complex or unpredictable the sound is. Statistical tests showed that 21 of these 22 features carried strong speaker-specific information, with entropy and high-frequency energy standing out as especially distinctive. In other words, a person’s “voice fingerprint” is spread across many aspects of the sound, not just pitch or volume.
Two Ways of Turning Sound into Images
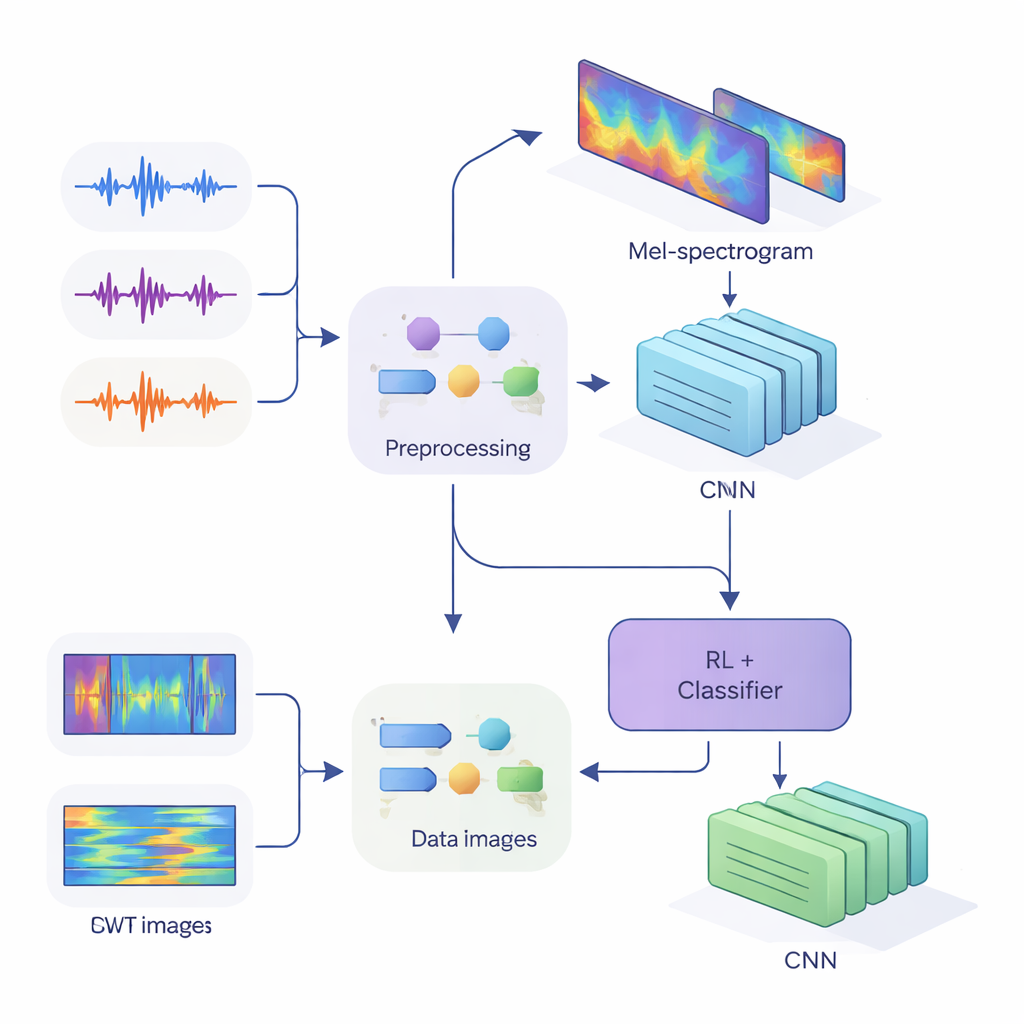
To feed these clues into modern neural networks, the team converted one-dimensional audio into two-dimensional pictures that capture how energy changes across time and frequency. In the first method, they used Mel-spectrograms, which mimic how the human ear groups frequencies and are standard in speech technology. In the second method, they used continuous wavelet transforms, a more flexible way of zooming in on both short, sharp sounds and longer vowels. After carefully cleaning the audio—removing silences, standardizing volume, and adding small distortions like noise and pitch shifts to make the system more robust—they produced Mel “images” of size 80 by 313 and wavelet “images” of size 128 by 128, ready to be processed by convolutional neural networks (CNNs).
Teaching Networks to Listen and Doubt
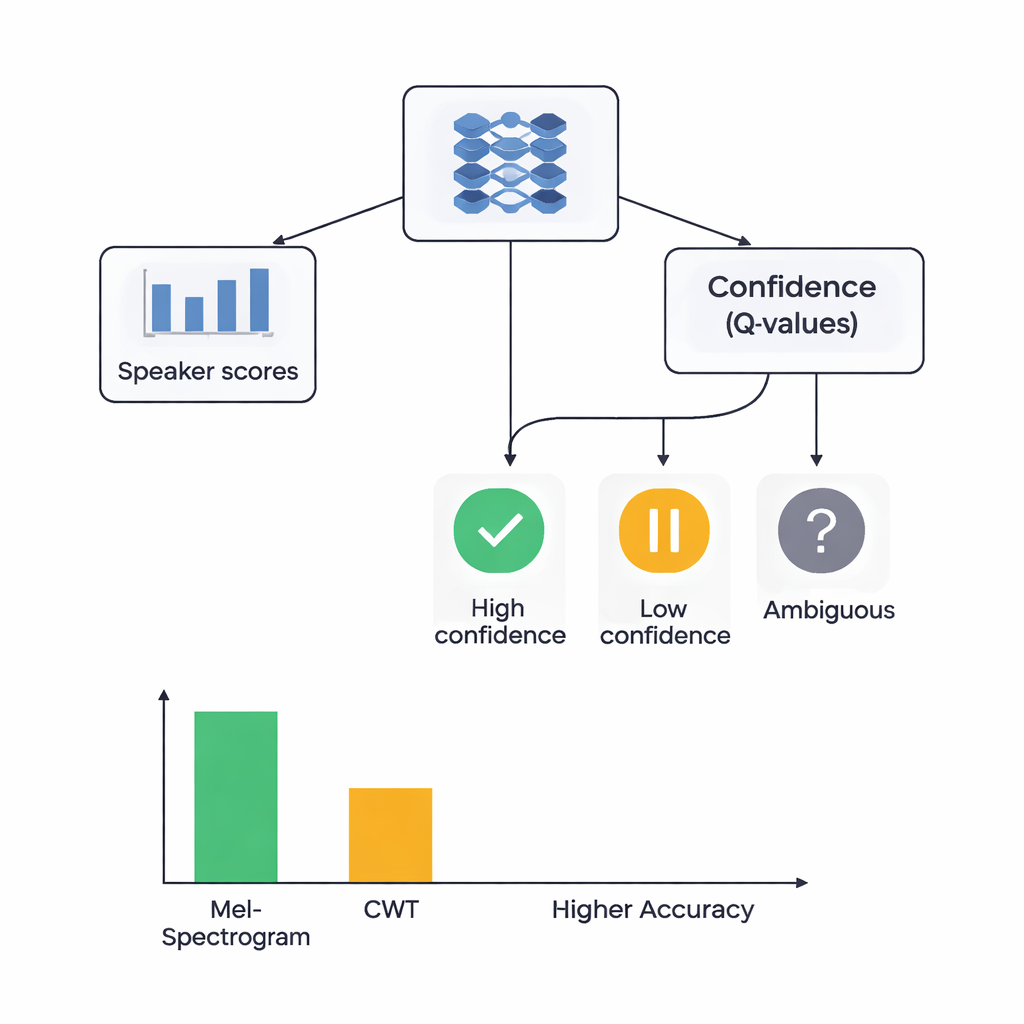
At the heart of the study is a hybrid architecture that joins two learning styles. First, CNNs scan the Mel or wavelet images to extract patterns that tend to belong to particular speakers, similar to how image-recognition networks learn to spot eyes or edges. For the Mel-based system, the authors add a self-attention module that allows the network to focus on the most informative time segments. On top of these feature extractors, they place a reinforcement learning (RL) component that learns how confident the system should be in each decision. Instead of always making a hard choice, the RL part assigns values to actions such as “accept this as a high-confidence guess,” “treat this as low confidence,” or “mark as ambiguous.” Over many training rounds, it is rewarded when confident decisions are correct, nudging the network toward better-calibrated judgments.
How Well Does the Hybrid System Work?
The researchers compared four models: Mel-based with RL, Mel-based without RL, wavelet-based with RL, and wavelet-based without RL. All were tested using a careful five-fold cross-validation, meaning each audio clip served both for training and for testing in different rounds. The Mel plus RL system performed best, correctly identifying the speaker about 88% of the time and showing near-perfect separation between speakers according to a standard measure of discriminative power. The wavelet plus RL system reached about 78% accuracy. Crucially, adding the RL component improved performance for both feature types by roughly 3 percentage points and made results more consistent across different data splits. More speaker classes achieved high-quality recognition when RL was included, suggesting that the confidence-aware decisions helped especially with difficult, easily confused voices.
What This Means for Everyday Voice Security
For non-specialists, the key takeaway is that reliable voice-based identity checks require both rich representations of the sound and a healthy sense of doubt from the machine. This work shows that ear-inspired Mel-spectrograms, combined with attention and a reinforcement learner that can say “I’m not sure,” outperform more exotic wavelet pictures for the task of telling speakers apart. While the study uses a relatively small, clean dataset and is not yet tuned for noisy, real-world conditions, it demonstrates that adding a confidence-aware layer on top of deep neural networks can make voice authentication both more accurate and more trustworthy—an important step if our voices are to become secure digital keys.
Citation: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Keywords: speaker identification, voice biometrics, deep learning, reinforcement learning, Mel-spectrograms