Clear Sky Science · en
Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection
Why picking the right data matters
Modern life runs on data, from medical scans and bank records to social media feeds. But more data is not always better. When computers are asked to learn from thousands of raw measurements at once, they can become slower, more expensive to run, and surprisingly less accurate. This paper presents a smarter way to sift through all those measurements and keep only the ones that truly matter, using a new algorithm called Binary Adaptive Generalized Normal Distribution Optimizer, or BAGNDO.
The problem of too many clues
Imagine diagnosing a disease with hundreds of lab tests, scans, and questionnaire answers. Many of these “features” may be noisy, redundant, or simply irrelevant, and feeding them all into a classifier can confuse rather than help. Feature selection aims to choose a smaller, more informative subset of inputs so that machine-learning models become faster, cheaper, and more reliable. Simple statistical filters can remove obviously unhelpful features, but they do not tailor their choices to the specific model being used and often miss subtle combinations of variables. More advanced “wrapper” methods judge feature sets by directly testing how well a classifier performs, but this creates an enormous search problem: the number of possible subsets explodes as the feature count grows.
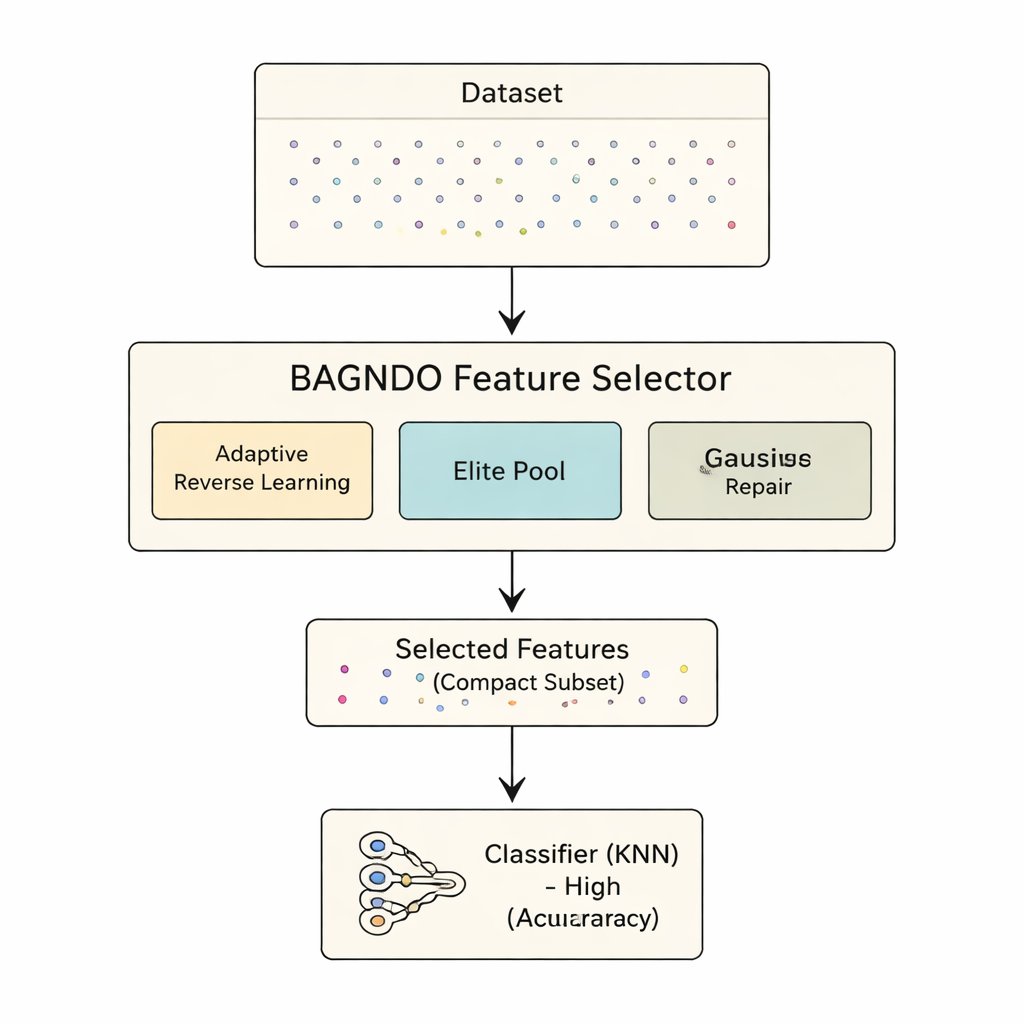
Searching smartly instead of blindly
To handle this explosion, researchers rely on metaheuristic algorithms—search strategies inspired by natural or physical processes that balance broad exploration with focused refinement. One such method, the Generalized Normal Distribution Optimizer (GNDO), treats candidate solutions as if they were drawn from a flexible bell-shaped curve and gradually shifts this curve toward better answers. GNDO has worked well in engineering and energy applications, but it tends to settle too early on merely decent solutions and struggles to balance its global wandering with local fine-tuning when applied to feature selection. The authors identify this as a critical gap: GNDO’s elegant math does not automatically translate into strong performance on high-dimensional, yes-or-no decisions about which features to keep.
A three-part upgrade to a classic engine
The proposed BAGNDO framework upgrades GNDO with three coordinated ideas. First, an Adaptive Cauchy Reverse Learning strategy regularly generates “mirror” versions of current solutions using a heavy-tailed probability distribution. This encourages bold jumps into unexplored regions of the search space, preventing the algorithm from getting stuck in local ruts. Second, an Elite Pool Strategy keeps not just a single best solution, but a small group of top performers plus a blended “guide” candidate. This richer leadership group helps maintain diversity while still steering the search toward promising regions. Third, a Gaussian Distribution-based Worst-solution Repair method looks at the weakest candidates and nudges them toward patterns learned from the elite group, effectively recycling bad solutions into better ones instead of discarding them outright.
Putting the method to the test
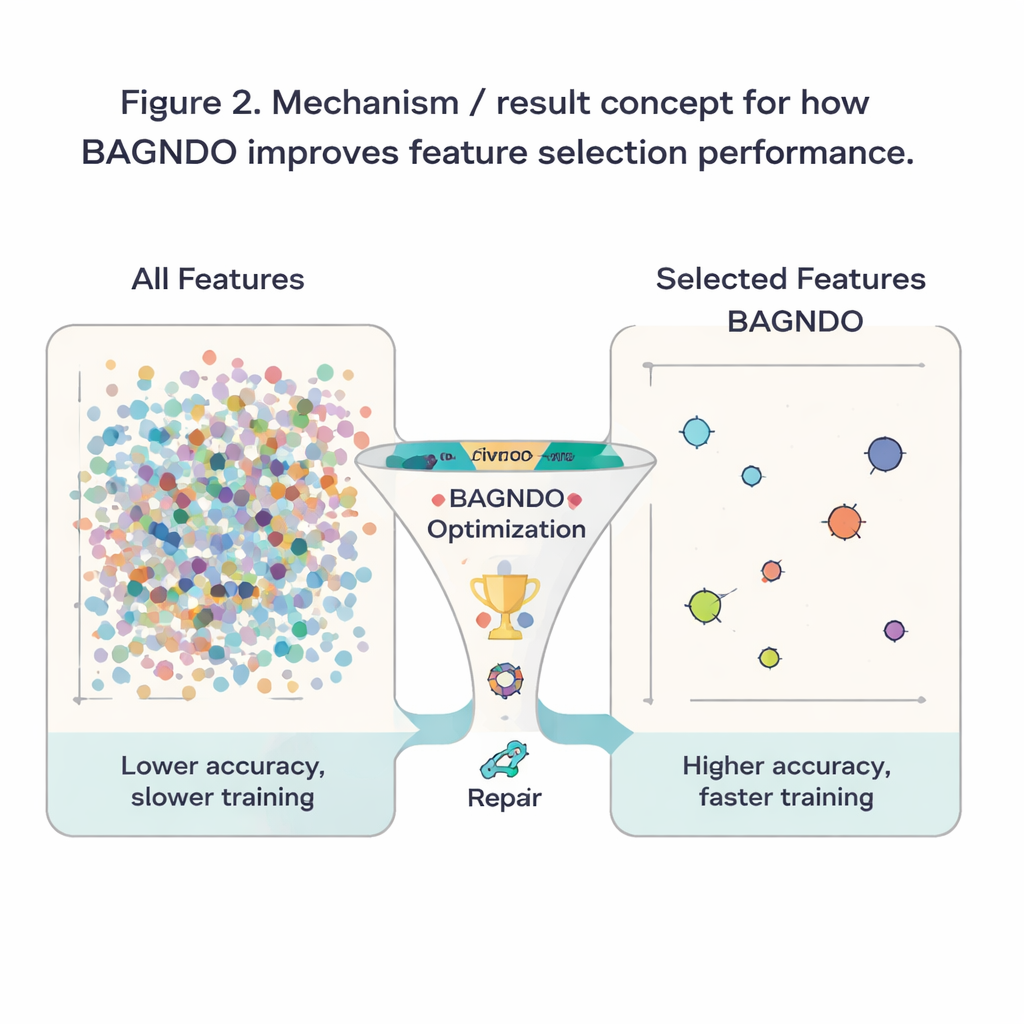
To see whether these ideas help in practice, the authors applied BAGNDO to 18 well-known benchmark datasets from the UCI repository, spanning medical diagnosis, games, signals, and more. In each case, the algorithm searched for a subset of features that allowed a standard k-nearest neighbors classifier to make accurate predictions. BAGNDO was pitted against nine strong competitors, including particle swarm optimization, genetic-style methods, and several modern swarm-inspired algorithms. Across these tests, BAGNDO consistently found smaller sets of features while keeping, and often improving, prediction accuracy. It achieved the best accuracy with the most compact feature subsets in 14 out of 18 datasets, and statistical tests confirmed that these gains were not due to chance.
What this means for everyday machine learning
For a layperson, the outcome can be summarized simply: the authors have built a more disciplined "feature picker" that helps learning algorithms focus on what truly matters in a dataset. By better juggling broad exploration, elite guidance, and repair of poor candidates, BAGNDO trims away unnecessary inputs while keeping or boosting accuracy. This means faster models, reduced storage and computation costs, and often clearer insights into which measurements or questions are most informative. Although the method is more computationally demanding than some simpler alternatives, it offers a powerful tool for problems where accuracy and interpretability are paramount, from medical decision support to industrial monitoring and beyond.
Citation: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Keywords: feature selection, metaheuristic optimization, machine learning, dimensionality reduction, classification accuracy