Clear Sky Science · en
Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance
Listening for Hidden Footsteps
Imagine detecting people moving through a dark forest or along a remote border without a single camera in sight—just by listening to their footsteps. This study explores how subtle sounds made by walking can be turned into a powerful early‑warning tool for soldiers, police, and investigators, especially in places where cameras fail or power is scarce.
Why Cameras Are Not Enough
Modern security often relies on video surveillance, but cameras have clear weaknesses: they need a direct line of sight, consume a lot of power, and can be hard to deploy quickly in rough or hostile terrain. Mobile checkpoints, border patrols, and counter‑terrorism teams may operate at night, under dense foliage, or in mountainous regions where installing and maintaining camera networks is impractical. In these situations, sound becomes an appealing alternative. Microphones are lightweight, cheaper to power, and can “hear around corners,” picking up people before they are visible. Footsteps, although relatively quiet, stand out in many tactical settings where background noise is low, making them a promising signal for early warning and forensic reconstruction of events.
Building a Real‑World Footstep Library
To turn this idea into a working system, the researchers first had to solve a basic problem: there was no suitable collection of real‑world footstep recordings. Existing sound databases include a few footsteps mainly for generic sound recognition or identity matching, often recorded in controlled lab conditions. They usually do not say whether the sound came from a forest, a road, or indoors, nor whether it was made by one person or many. The team therefore created a new resource called the EWFootstep 1.0 dataset. It contains 1,650 audio clips from 176 volunteers walking naturally across forests, roads, and indoor spaces in three different regions of India. Recordings capture a mix of soft‑soled and hard‑soled shoes, different terrains, and realistic field conditions such as uneven microphone placement. Each clip includes at least 15 footsteps and is labeled both by environment type and by whether it features a single person or a group.
Teaching a Machine to Hear Like a Scout
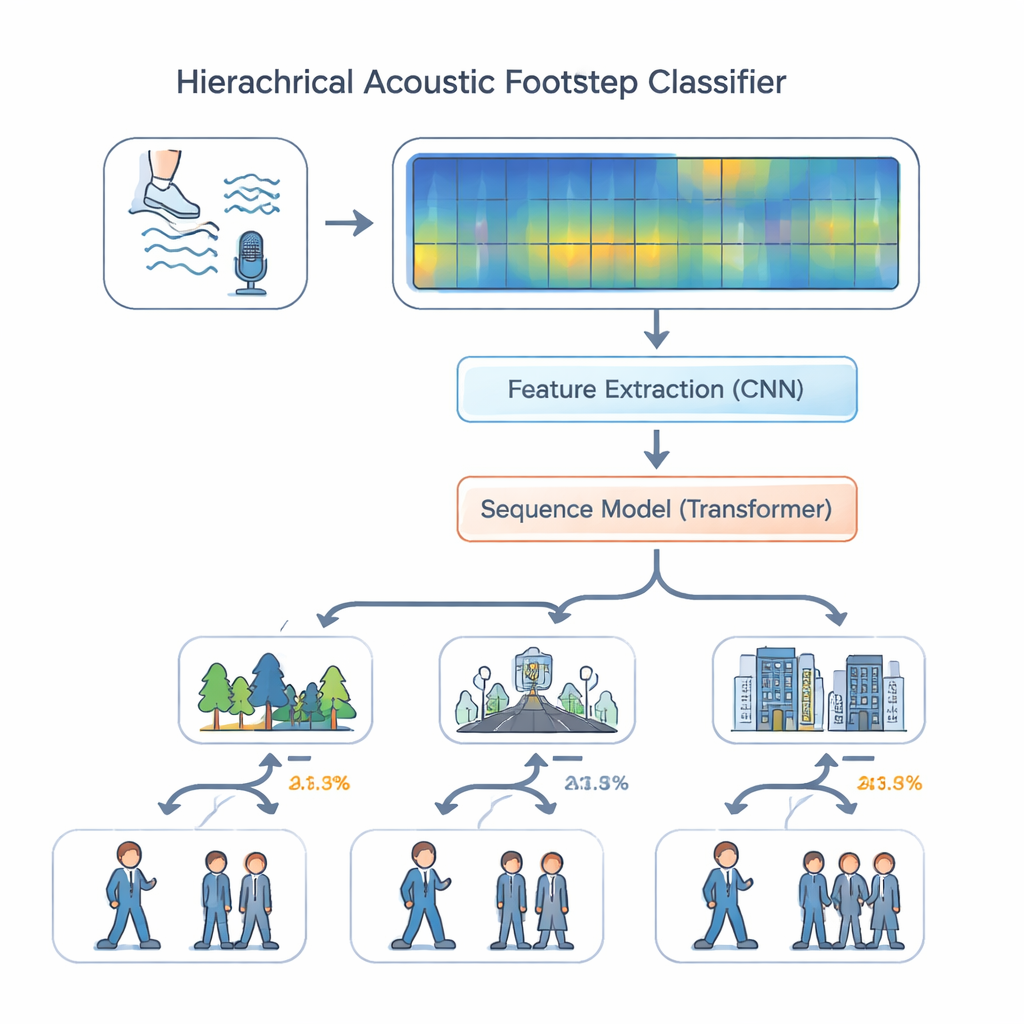
With this dataset in hand, the authors designed a listening system that mimics how a skilled scout might reason about sound. Instead of treating all tasks as equal, their “hierarchical multi‑task” model first decides where the sound is happening—forest, road, or indoors—and then, using that context, estimates whether it is one person or more than one. The audio is converted into colorful spectrograms that show how energy is spread across frequencies over time. A set of convolutional layers picks out fine details linked to surfaces and footwear, such as the crunch of leaves or the thud of boots on concrete. These features then pass into a transformer module, a modern sequence‑processing engine that examines patterns over many steps—rhythm, spacing, and repeated impacts—rather than isolated sounds. Positional encoding helps the model keep track of ordering in time, which is essential for recognizing walking patterns.
How Well Does the Acoustic Sentinel Work?
The researchers compared their hierarchical model against simpler approaches, such as a single all‑in‑one classifier and a standard multi‑task design where environment and headcount are predicted independently. They also tested variants that removed key components like the convolution layers or the transformer. Across the board, the full design with both modules and positional encoding performed best. On the EWFootstep 1.0 dataset, it correctly identified the environment about 96 percent of the time and the number of people with similar accuracy—substantially better than trained human listeners, who lagged behind by 25 to 30 percentage points. Additional experiments on a cough‑sound dataset showed that the same architecture generalizes well beyond footsteps, suggesting it can handle very different kinds of everyday audio.
From Battlefield to Crime Scene
For non‑specialists, the key takeaway is that faint, everyday sounds like footsteps contain far more information than we typically notice. By combining large, realistic datasets with advanced pattern‑recognition tools, the authors show that a compact system can reliably tell what kind of place it is listening to and how many people are there, in near real time and without cameras. This “acoustic sentinel” could help protect patrols and remote facilities, and its ability to dissect subtle sound patterns may also aid audio forensics, such as reconstructing movement at a crime scene when video is unavailable or unreliable.
Citation: Agrahri, A., Maurya, C.K., Tiwari, R.S. et al. Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance. Sci Rep 16, 5635 (2026). https://doi.org/10.1038/s41598-026-35756-3
Keywords: acoustic surveillance, footstep detection, early warning systems, deep learning audio, tactical security