Clear Sky Science · en
Multi-feature enhancement fusion network for remote sensing image semantic segmentation
Sharper Maps from the Sky
Every day, satellites and drones capture detailed pictures of our cities and farmlands. Turning these raw images into clear, pixel‑by‑pixel maps of roads, roofs, trees, and crops is essential for tasks like monitoring crop health or planning new neighborhoods. This paper introduces a new way to make those maps more accurate, especially along tricky boundaries where buildings, fields, and vegetation blur together.
Why Aerial Images Are Hard to Read
Remote sensing images look different from everyday photos. They are taken from high above, often at sharp angles and under changing light. Different objects can appear very similar from the air: a concrete parking lot and a flat roof might share almost the same color; different types of crops can show confusingly similar patterns. At the same time, the same kind of object can look quite different depending on shadows, moisture, or camera settings. Traditional computer programs, and even many modern deep‑learning systems, struggle to keep boundaries crisp under these conditions. They often blur edges between categories or miss small details like parked cars or narrow irrigation channels.
Seeing Both the Big Picture and the Fine Lines
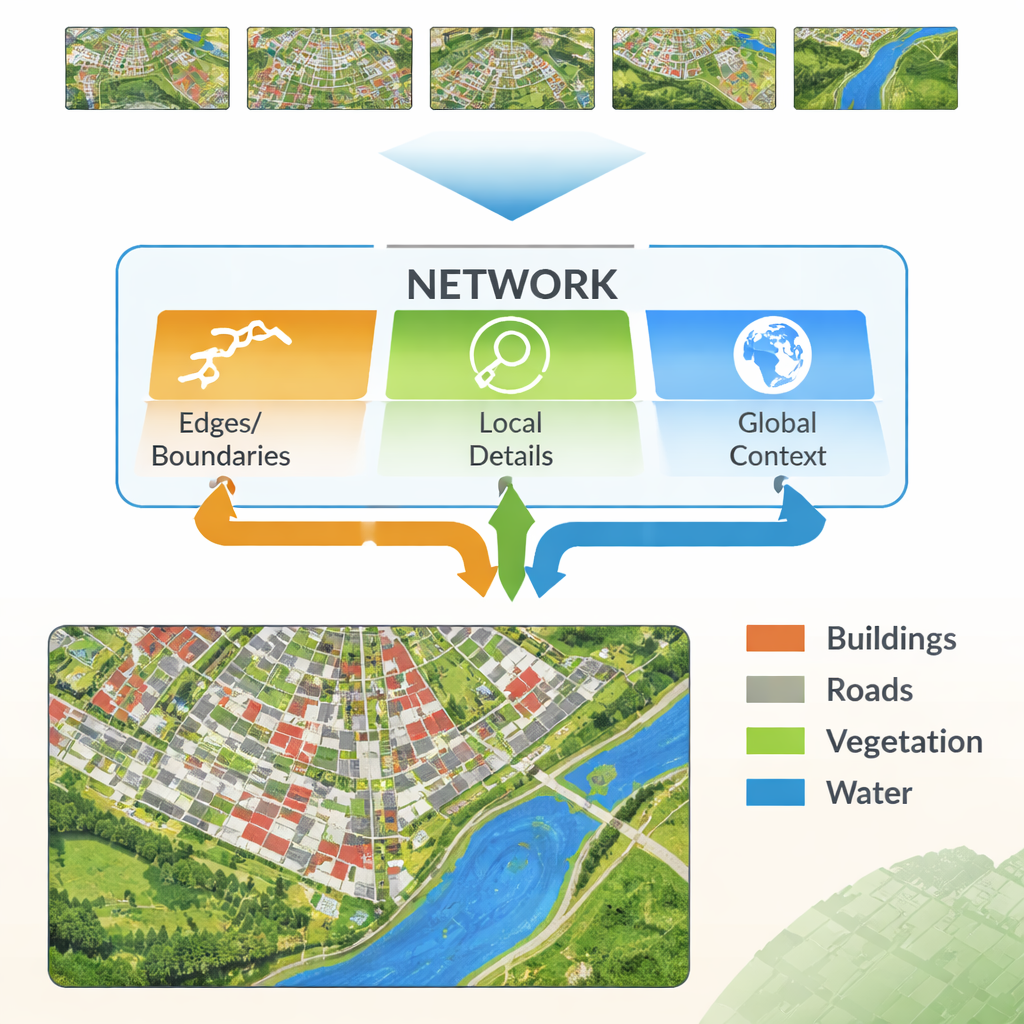
Modern neural networks learn by passing an image through many layers. Early layers pick up fine details like lines and textures, while deeper layers learn broad patterns such as “this region is probably buildings.” The challenge is that combining these two kinds of information is not straightforward. Low‑level details can be noisy and redundant, and high‑level patterns can wash out the edges, producing fuzzy outlines. The authors propose a new architecture, called the Multi‑Feature Enhancement Fusion Network (MFEF‑UNet), that is explicitly designed to balance local detail with global understanding. It does this by treating edges, local patterns, and broad context as separate but cooperating sources of information.
Highlighting Edges and Blending Features
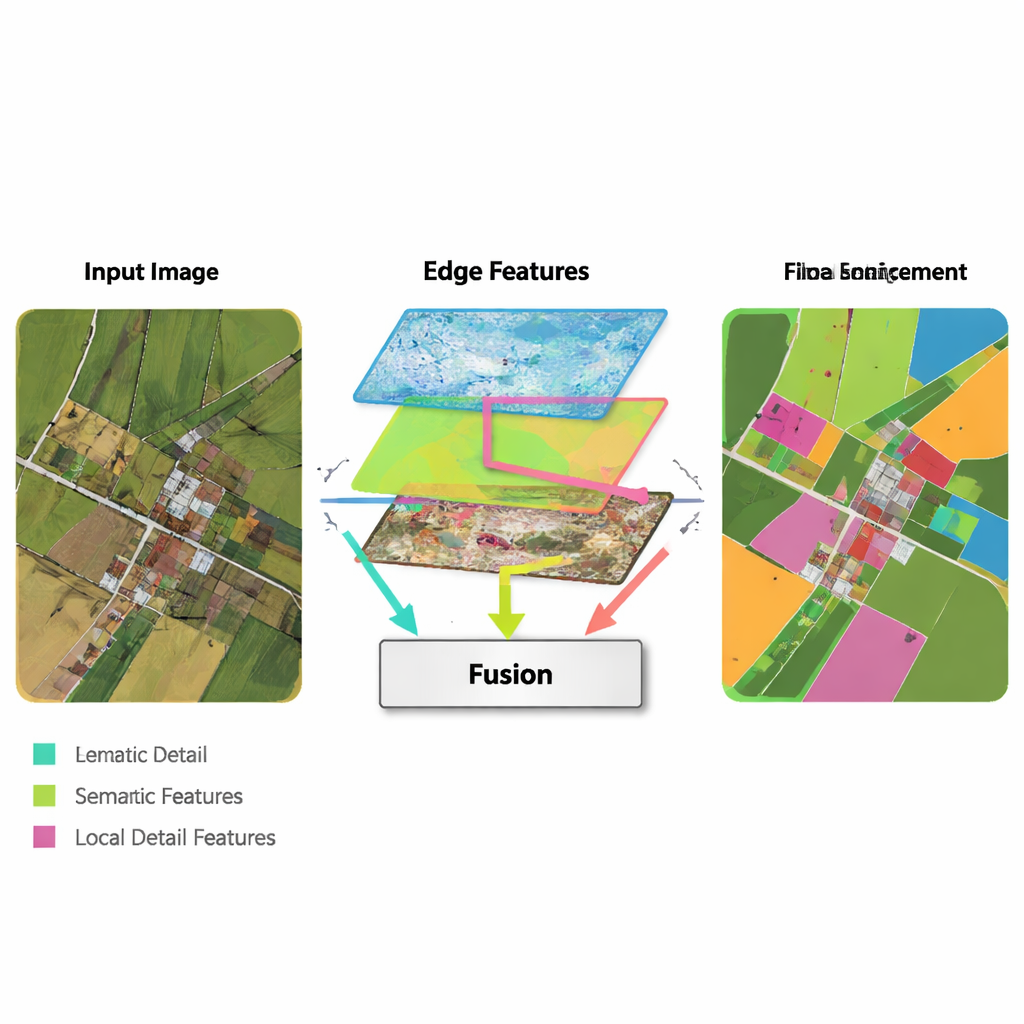
A key idea in the new method is to borrow simple, classic edge‑detection tools and weave them into a modern deep‑learning pipeline. An Edge Enhancement Module takes the earliest features from the network and runs them through operators that are very good at finding boundaries—similar to how basic image‑editing software can detect outlines. These enhanced edge maps are produced at several scales, so the network sees both fine and coarse boundaries. A Multi‑Feature Fusion Module then brings together three streams: the evolving high‑level “what is this region?” information, the decoder’s reconstruction of details, and the edge maps. Instead of just stacking them, the module uses an attention‑like mechanism so that semantic features can “ask” the edge and detail streams where boundaries and small structures really are, and adjust the final representation accordingly.
Balancing Local Detail with Global Context
Another ingredient of MFEF‑UNet is a Local‑Global Feature Enhancement Module. To a layperson, this can be thought of as the part of the network that ensures it does not lose track of the forest while focusing on the trees—or the city while refining each building. The image is broken into manageable sub‑windows so that nearby pixels can be modeled together, preserving shapes and textures. After this local modeling, the windows are stitched back into a full image, and a second pass allows information to flow across distant regions. This two‑step process helps the model respect both small structures, like cars and narrow field boundaries, and large‑scale patterns, like blocks of housing or continuous water bodies.
Proving the Method on Cities and Farmland
The researchers tested their approach on three publicly available datasets: two that cover European towns and cities, and one large collection of farmland images from the United States. These datasets contain a mix of roofs, roads, vegetation, water, and subtle crop patterns. Across all three benchmarks, MFEF‑UNet consistently produced more accurate maps than a range of leading methods, including classic convolutional networks, Transformer‑based architectures, and newer “state‑space” models. Its advantages were most visible around complex building outlines, clusters of small objects like vehicles, and long, thin structures such as drainage channels or crop rows—places where other methods tend to fragment or blur the segmentation.
What This Means in Practice
In practical terms, the proposed network turns aerial images into cleaner, more reliable land‑cover maps. Urban planners can more confidently measure built‑up areas, engineers can better trace roads and roofs, and agronomists can more precisely delineate fields, waterways, and zones of crop stress. Although the added edge and fusion components introduce some extra computation, the overall design stays reasonably efficient while delivering clear gains in accuracy and robustness. For non‑specialists, the takeaway is that by deliberately emphasizing edges and carefully fusing different kinds of visual cues, computers can now read satellite and drone imagery with a sharper eye—bringing us closer to up‑to‑date, high‑precision maps of the world.
Citation: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Keywords: remote sensing, semantic segmentation, satellite imagery, deep learning, land cover mapping