Clear Sky Science · en
Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating
Teaching Computers to Follow One Object in a Crowded Scene
From self-driving cars to home security cameras and drones, many modern devices need to follow a single moving object through a busy, changing world. This task, called visual object tracking, sounds simple to humans but is surprisingly hard for machines: people walk in front of the camera, lighting changes, the object shrinks into the distance or is briefly hidden. This paper introduces TSDTrack, a new tracking system that uses recent advances in deep learning and transformers to stay locked on a target more reliably in such real-world conditions.
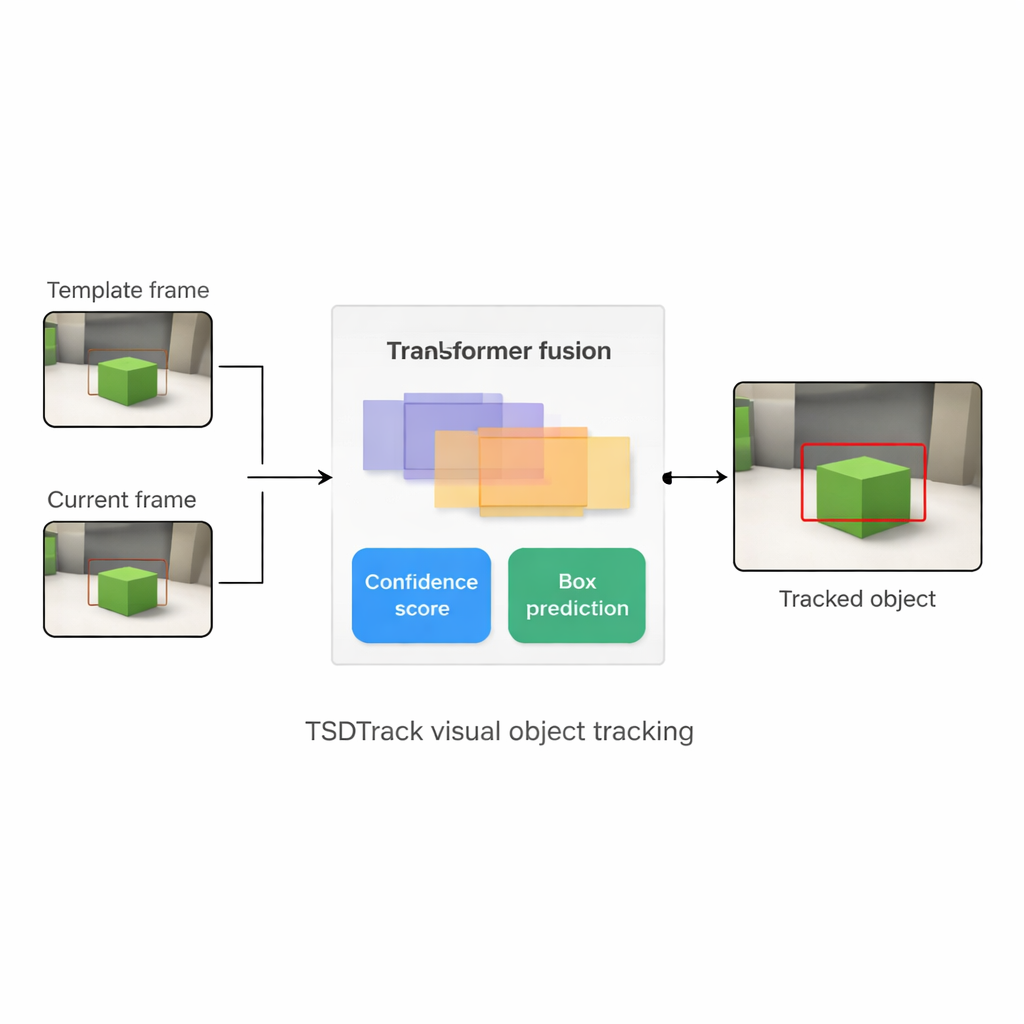
Why Following One Thing Is So Difficult
A tracker usually sees the object clearly only in the first frame of a video, then must keep finding it as the scene changes. Traditional methods either relied on hand-crafted image features or on a neural network that compared the first frame (the "template") with each new frame. These older systems had three big weaknesses. First, they typically kept the original template fixed, so if the object turned, got partly covered, or changed in size, the tracker struggled. Second, they often focused on a single level of detail in the image, missing the combination of fine edges and broader context that helps humans recognize things. Third, they did not know when to doubt themselves: they produced a box around the supposed object without any clear sense of how reliable that guess was, which made them prone to drifting onto the background.
Blending Global Context with Fine Details
TSDTrack addresses these problems by combining a classic "Siamese" tracking setup with a transformer, the same kind of attention-based model that has transformed language and vision tasks. The system uses a deep network to extract features from two inputs: a small patch that defines the target and a larger patch that contains the current search area. Instead of relying on just one feature scale, it pulls information from multiple layers of the network, which represent edges, shapes, and object-level patterns. A transformer-based fusion module then learns how to mix these layers so that the tracker understands both where things are in the image and how they relate to the broader scene. This helps it distinguish the target from similar objects and clutter, even when the view is noisy or partially blocked.
Knowing How Sure the Tracker Really Is
The heart of TSDTrack is a dual-branch prediction head that splits the task into two related questions: "Where is the object?" and "How much should we trust this answer?" One branch estimates a confidence score that reflects not just how similar the target looks, but also how well the predicted box overlaps with likely object regions. The other branch treats the box coordinates not as a single guess, but as a probability distribution over many possible positions, allowing the model to represent uncertainty. When the image is clear, the distribution becomes sharp and the box is precise; when the object is blurred or partly hidden, the distribution spreads out. This probabilistic view leads to smoother, more stable box placement compared with older trackers that made a single rigid prediction.
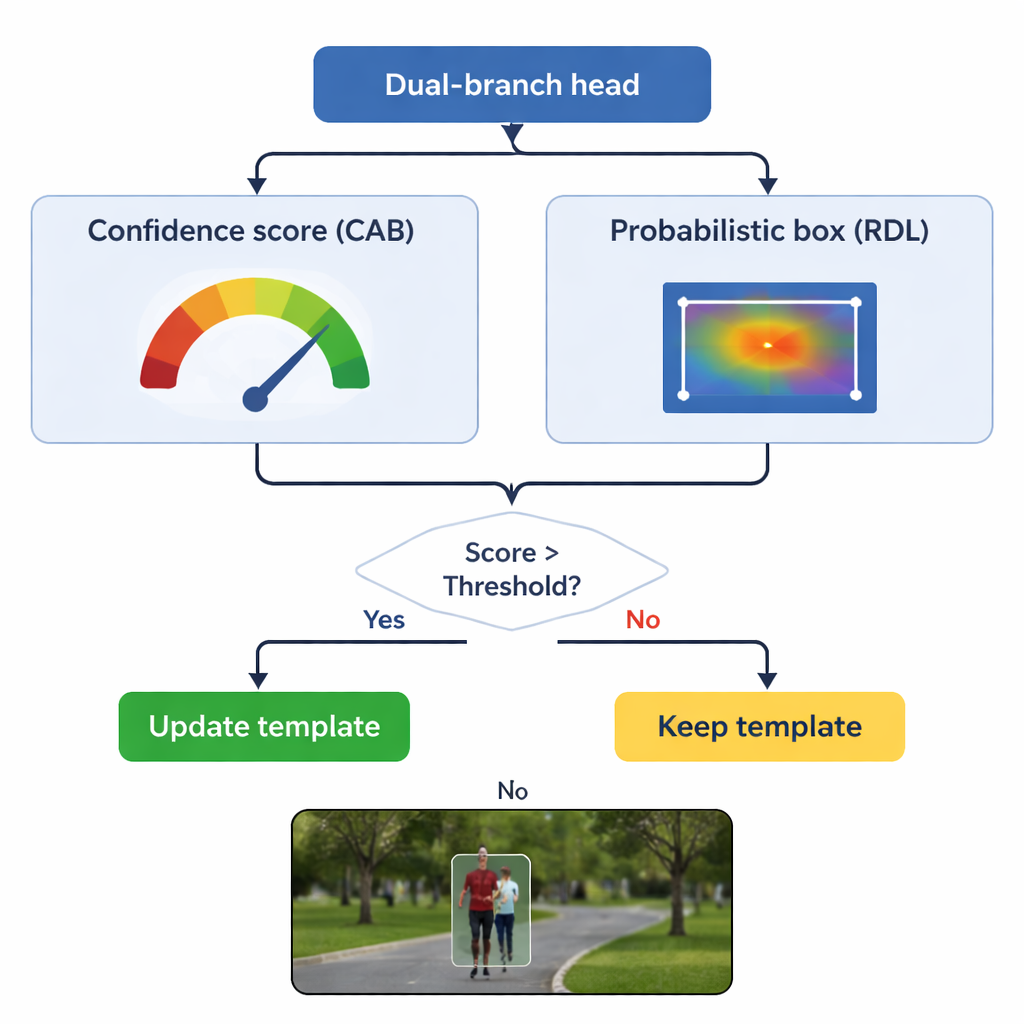
Updating Memory Without Forgetting the Original
A key danger in tracking is "template drift": if the model keeps updating its idea of the object using bad frames, it can slowly learn the background instead. TSDTrack tackles this by letting its confidence branch act as a gatekeeper. The system updates its internal template only when the confidence score is above a chosen threshold, and even then, it blends new information gently with the original view rather than replacing it outright. This selective updating lets the tracker adapt to genuine changes, such as a person turning around or a car rotating, without being fooled by momentary occlusions or distractions. The original template is also kept in reserve as a stable reference in case later updates turn out to be misleading.
What the Results Mean in Practice
The authors tested TSDTrack on several widely used tracking benchmarks, including long videos, fast motion, aerial footage from drones, and scenes with heavy clutter. Across these tests, the new method consistently beat many leading trackers in both accuracy (how close the box is to the true object) and robustness (how rarely it loses the object entirely), while still running fast enough for real-time use on modern hardware. For a non-specialist, the takeaway is that TSDTrack can keep its eye on a chosen target more reliably in the messy conditions found in real-world cameras. By combining multi-scale transformer reasoning, a sense of its own confidence, and careful template updating, it offers a more trustworthy building block for applications like autonomous driving, smart surveillance, and intelligent robots.
Citation: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Keywords: visual object tracking, transformer-based tracking, Siamese networks, computer vision, autonomous systems