Clear Sky Science · en
Visual guided AI color art image generation using enhanced GAN
Why Smarter Art Machines Matter
Digital tools can now paint portraits, landscapes, and abstract scenes in seconds, yet many of these AI artworks still look slightly off—colors clash, textures feel flat, or the “style” doesn’t quite match what people imagine. This paper presents a new way to teach computers to create color artworks that are richer, more coherent, and closer to real paintings while letting users nudge the result with simple visual hints like sketches and color choices. The goal is to make AI a more reliable creative partner for artists, designers, and everyday users who want personalized art without needing years of training.
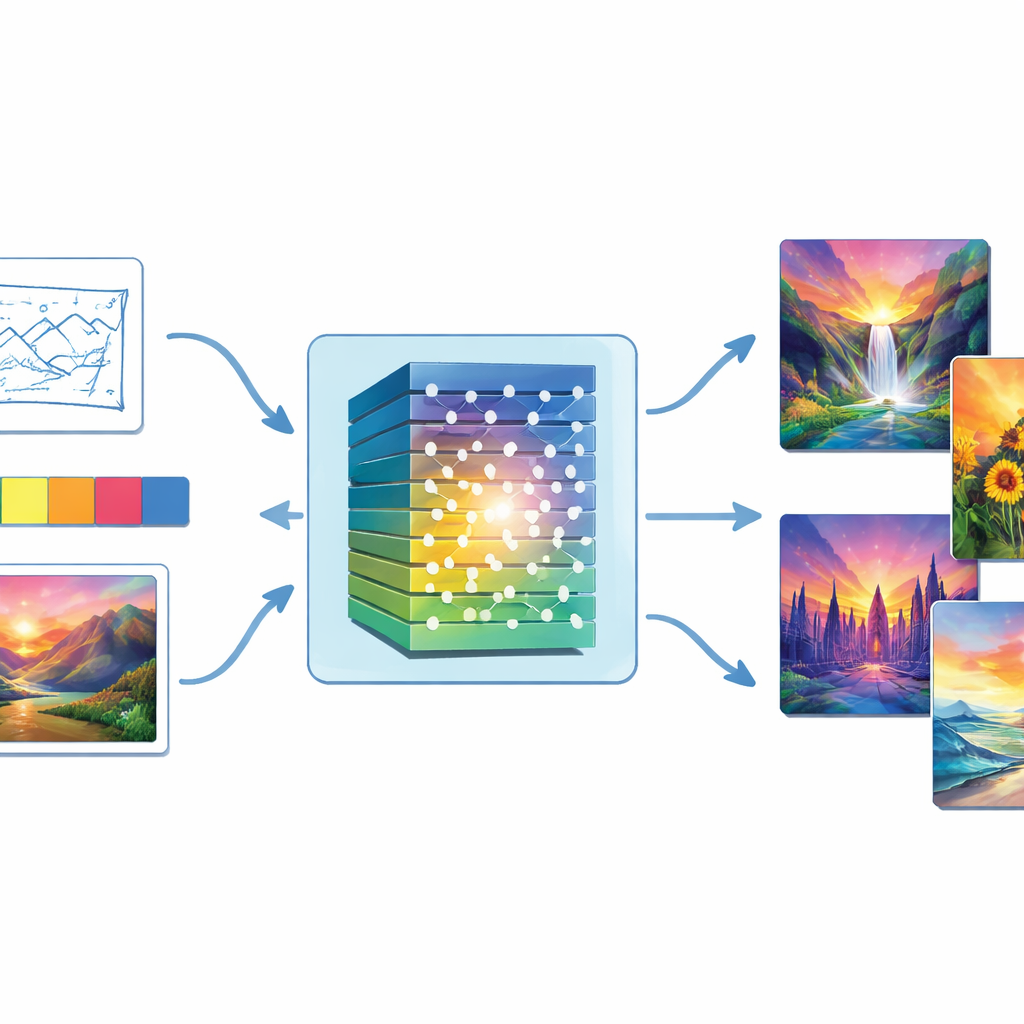
From Random Noise to Finished Paintings
At the heart of the study is a type of AI called a Generative Adversarial Network, or GAN. A GAN is built from two opposing parts: a “generator” that tries to produce convincing images from random noise, and a “discriminator” that judges whether an image looks real or fake. Through many rounds of back-and-forth training, the generator gets better at fooling the discriminator, and the images gradually become more lifelike. The authors strengthen this core idea by inserting a deep image-processing stack—called a convolutional neural network—inside both generator and discriminator, so the system can better capture everything from broad shapes down to fine brushlike details.
Teaching the System Where to Look
While standard GANs can produce sharp images, they often miss the big picture: they may overemphasize small details and lose global structure, or fail to keep a consistent artistic style. To address this, the team adds an adaptive attention mechanism. This module analyzes the internal feature maps of the generator and learns, during training, which regions of an image matter most at each moment. It then strengthens those key areas—such as edges, textures, and focal objects—while softening less important background zones. Special loss measures track how well the generated image matches the style and texture of a target artwork, pushing the model to balance recognizable content with a coherent artistic look.
Guiding the Machine with Visual Cues
Unlike text-only systems, this approach lets people steer the artwork with direct visual guidance. Users can provide a sketch to define the composition, a color palette to set the mood, a sample style image to imitate, or simple scene tags. These inputs enter the generator alongside the random noise. The model then computes color properties such as hue, saturation, and brightness, and adjusts its output so that the final painting respects both the user’s color intentions and the reference style. A color-matching objective further tightens the link between what the user indicates and what the system produces, so that a cool blue seascape does not unexpectedly turn into a warm sunset, for example.
Learning to Improve Through Trial and Error
The system goes a step further by using deep reinforcement learning, a technique inspired by trial-and-error learning. Here, a separate decision-making module treats the gap between the current output and the target guidance as its “state,” and proposes small adjustments to elements such as sketch strength or palette weights as its “actions.” After each change, the system measures how much important image-quality scores improve—such as peak signal-to-noise ratio, structural similarity, and style loss—and uses this as a reward signal. Over time, this loop learns a policy that automatically fine-tunes the guidance to drive the generator toward images that are both visually faithful and artistically consistent.
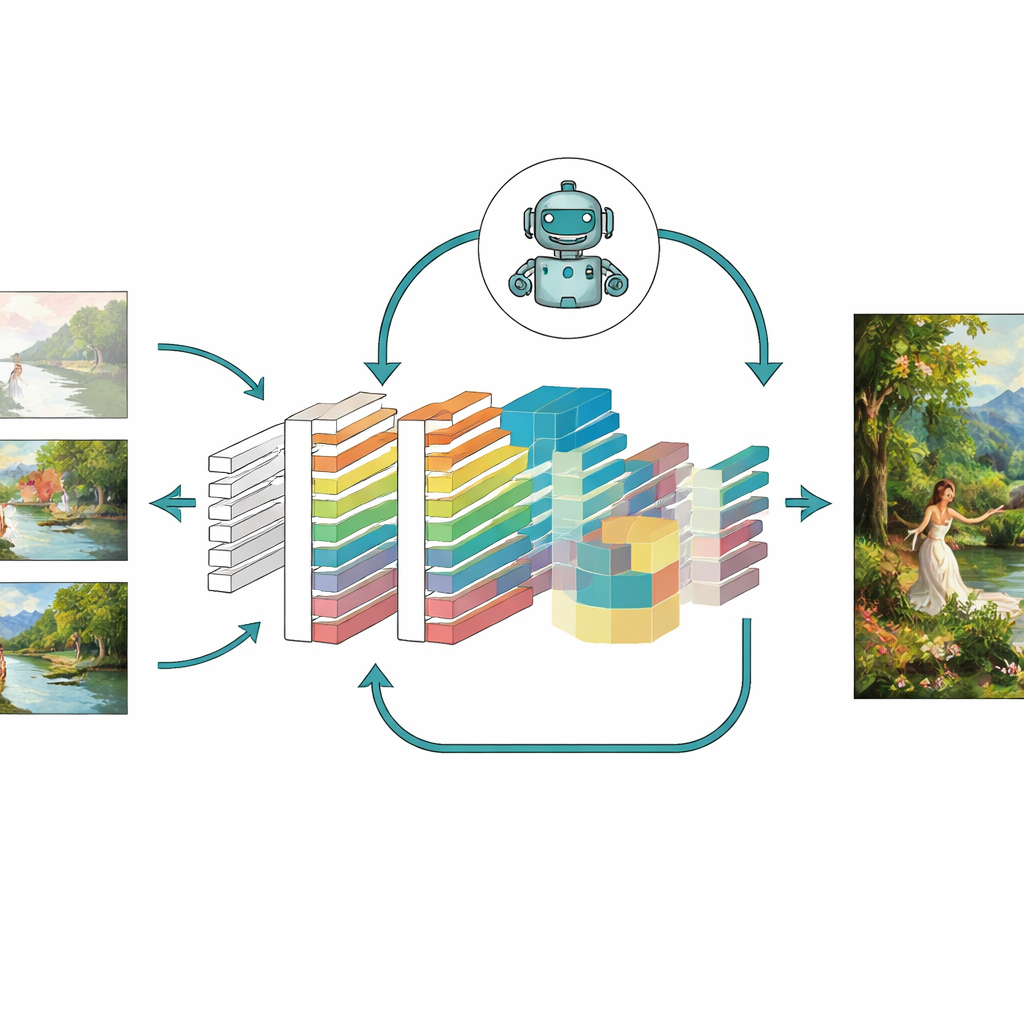
Putting the Model to the Test
To judge whether these ideas truly help, the authors tested their enhanced model—called a CNN-GAN—on a large paintings collection from the University of Oxford and on a custom set of more than 5,000 color artworks across styles like portraits, landscapes, and abstract scenes. They compared results with several well-known systems, including classic GAN variants, autoencoders, and even modern diffusion-based generators. Across many measures, the new model produced sharper images with fewer artifacts, closer structural match to real artworks, lower perceptual distance from target images, and higher diversity in the types of scenes it could generate. Ablation studies, which removed one module at a time, showed that attention, reinforcement learning, and the combined loss design each contributed meaningful improvements, and together gave the strongest performance.
What This Means for Future Creative Tools
In everyday terms, the paper describes a painting machine that not only learns from thousands of artworks, but also pays special attention to important regions, listens to users’ visual hints, and gradually teaches itself how to adjust these hints for better outcomes. The result is an AI that can generate high-quality, stylistically unified images more reliably than earlier methods, while still leaving room for human direction. Although the system still struggles with extremely intricate textures and relies on substantial training data, the authors suggest future extensions—such as multi-scale modules and lighter-weight networks—to make it more efficient and widely usable. Together, these advances point toward AI art tools that are faster, more faithful to user intent, and better at capturing the subtle character of human-made paintings.
Citation: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Keywords: AI art generation, image style transfer, generative adversarial networks, artificial creativity, neural image synthesis