Clear Sky Science · en
Accurate discharge summary generation using fine tuned large language models with self evaluation
Why paperwork at the hospital really matters
When a patient leaves the hospital, the story of their illness does not end at the exit door. Doctors in other clinics, family physicians, and the patients themselves all rely on a key document called a discharge summary to understand what happened in the hospital and what to do next. Yet writing these summaries is slow, repetitive work that can take busy clinicians half an hour or more per patient. This study explores how modern AI language tools can help draft discharge summaries faster and more accurately, while keeping patient data private and under hospital control.
Turning scattered records into a clear story
Hospital information is spread across many electronic systems: lab results in one table, surgery notes in another, nursing observations in a third, and so on. Each patient’s stay generates thousands of small pieces of text. The researchers first built a pipeline to turn this scattered, messy information into clean input that an AI model can understand. Using methods to merge and de-duplicate overlapping records, filter out private details such as names and IDs, fix spelling, and standardize medical terms, they created structured input for each hospital stay. This process was applied to data from more than 6,000 thyroid surgery patients at a major Chinese hospital, producing paired examples of real discharge summaries and the raw data from which they were written. 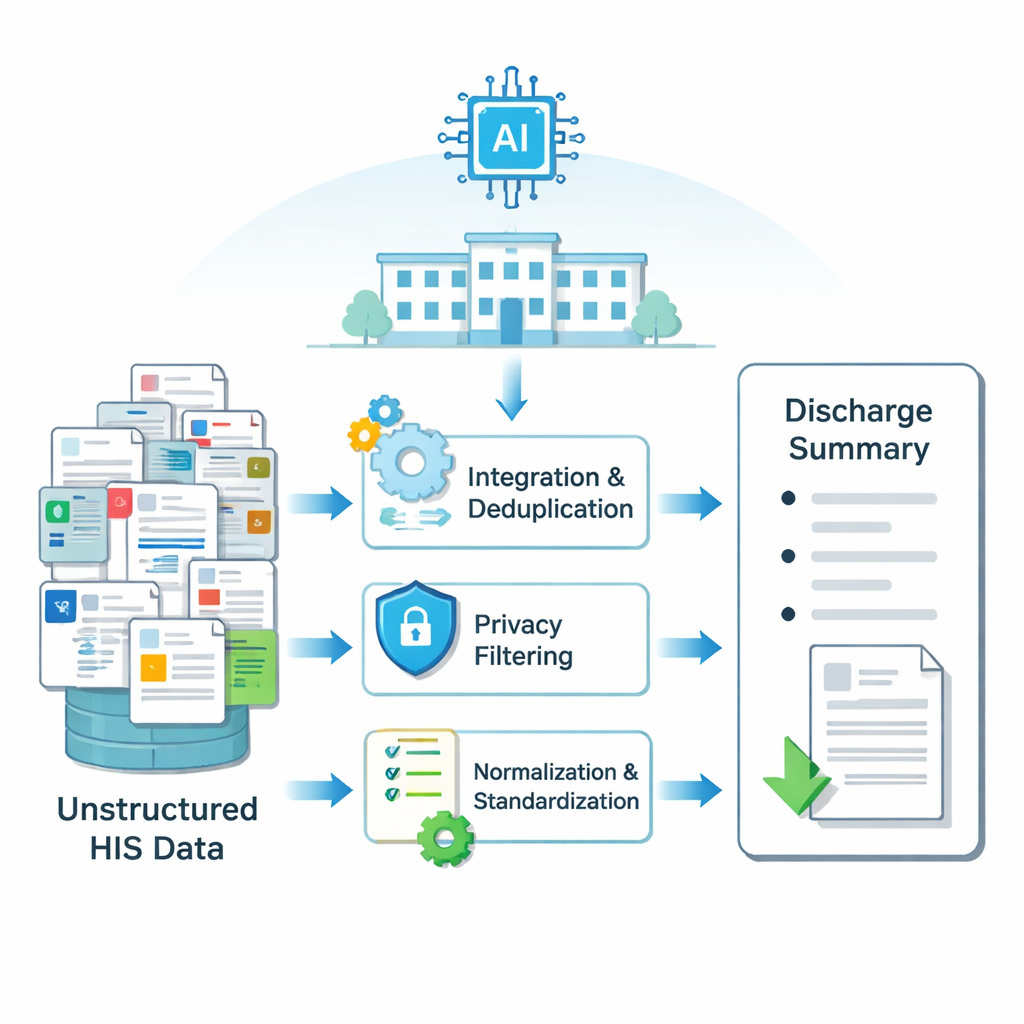
Fine-tuning AI to speak the language of medicine
Off-the-shelf large language models are trained on general text from the internet and books, so they often struggle with specialized medical language and local documentation styles. The team compared several ways to “fine-tune” existing models so they better understand Chinese medical records. A new method called weight-decomposed low-rank adaptation, or DoRA, adjusts the internal weights of the model in a more targeted way than older techniques such as LoRA and QLoRA. Across different models, including Qwen2, Mistral, and Llama 3, DoRA consistently produced summaries that were more fluent, closer in meaning to human-written ones, and less confused (as measured by a standard metric called perplexity). In essence, DoRA helped the AI learn medical phrasing and terminology without needing a full retraining on massive hardware.
Teaching the AI to double-check its own work
Even a well-trained model can forget important details or introduce minor errors when it writes a long summary in one pass. Inspired by psychological ideas of quick “System 1” thinking versus slower, more careful “System 2” reasoning, the authors designed a self-evaluation loop. First, the model writes an initial discharge summary from the processed hospital data. Then the original data are broken into segments—such as pathology findings, doctors’ orders, or lab panels—and each segment is re-paired with the draft summary. The model is asked, in effect, “Is everything in this segment reflected in the summary?” If not, it revises the text to add missing or inconsistent information. This cycle repeats up to three times or until the model judges the summary complete, producing a refined version that more faithfully matches the patient’s record. 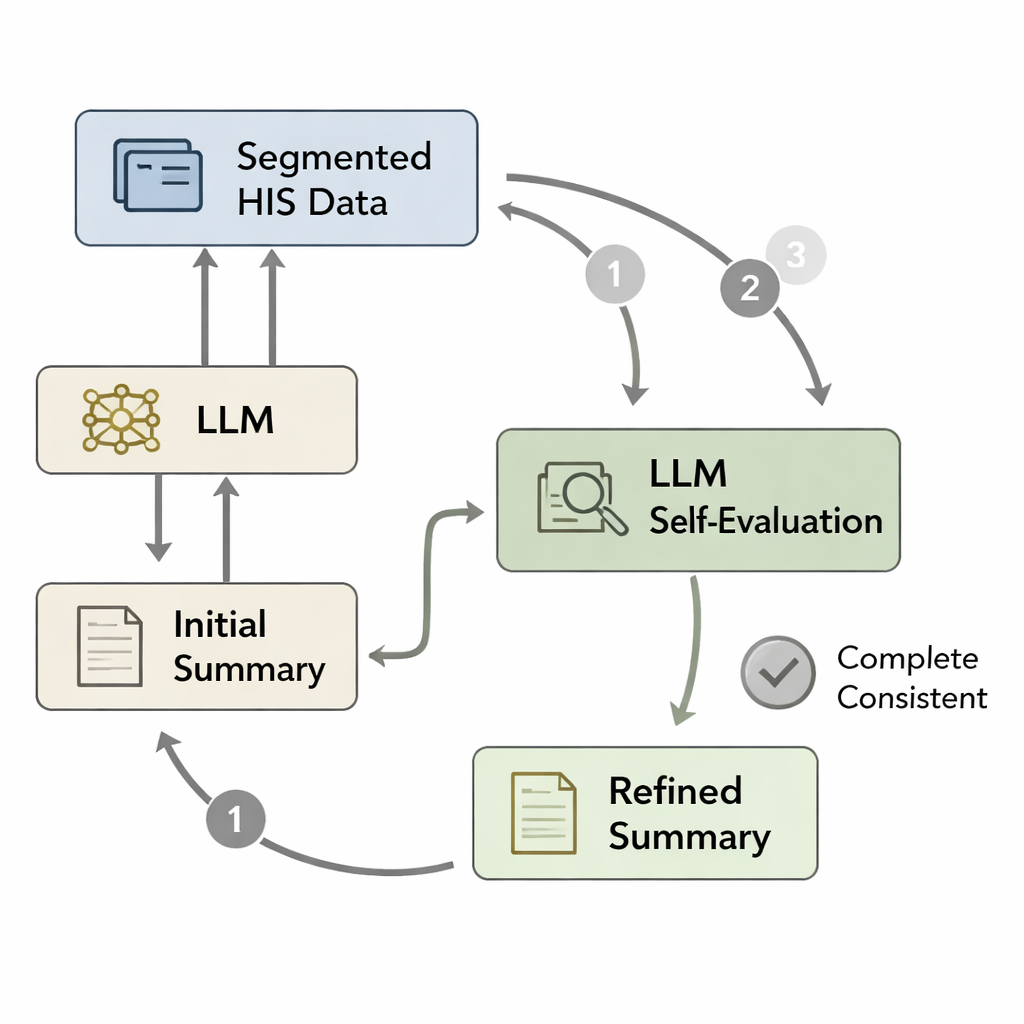
How well did the AI do compared with people?
To judge quality, the team used both automatic scores and human reviewers. Doctors and medical researchers rated summaries on accuracy, completeness, clarity, consistency, and usefulness for ongoing care. The best system—combining DoRA fine-tuning with the self-evaluation loop—came closest to human-written summaries on all measures. It especially improved completeness, meaning fewer missed diagnoses, treatments, or key lab values. In a detailed example, the AI initially forgot to mention a small thyroid cancer and a specific hormone pill; after two self-evaluation passes, both details were correctly added. On average, the system generated a discharge summary in about 80 seconds on a hospital server, compared with 30–50 minutes for a clinician to draft one from scratch, although human review remains essential before the text enters the official record.
What this could mean for patients and clinicians
The study shows that, with careful training and built-in self-checking, AI systems can produce discharge summaries that are accurate enough to be considered clinically acceptable after a quick human check. This does not replace doctors, but it can shift their time from rote typing to higher-level reviewing and decision-making. By keeping all computation inside the hospital network and removing identifying details, the approach also respects patient privacy. While the results so far come from a single department in one hospital, the framework points toward a future in which AI helps turn complex medical data into clear, reliable narratives across many specialties, supporting safer handoffs in care and better understanding for patients and families.
Citation: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Keywords: discharge summaries, medical AI, large language models, clinical documentation, self-evaluation