Clear Sky Science · en
Social user geolocation based on K-medoids and Gaussian Kernel graph attention network
Why your tweets can reveal where you live
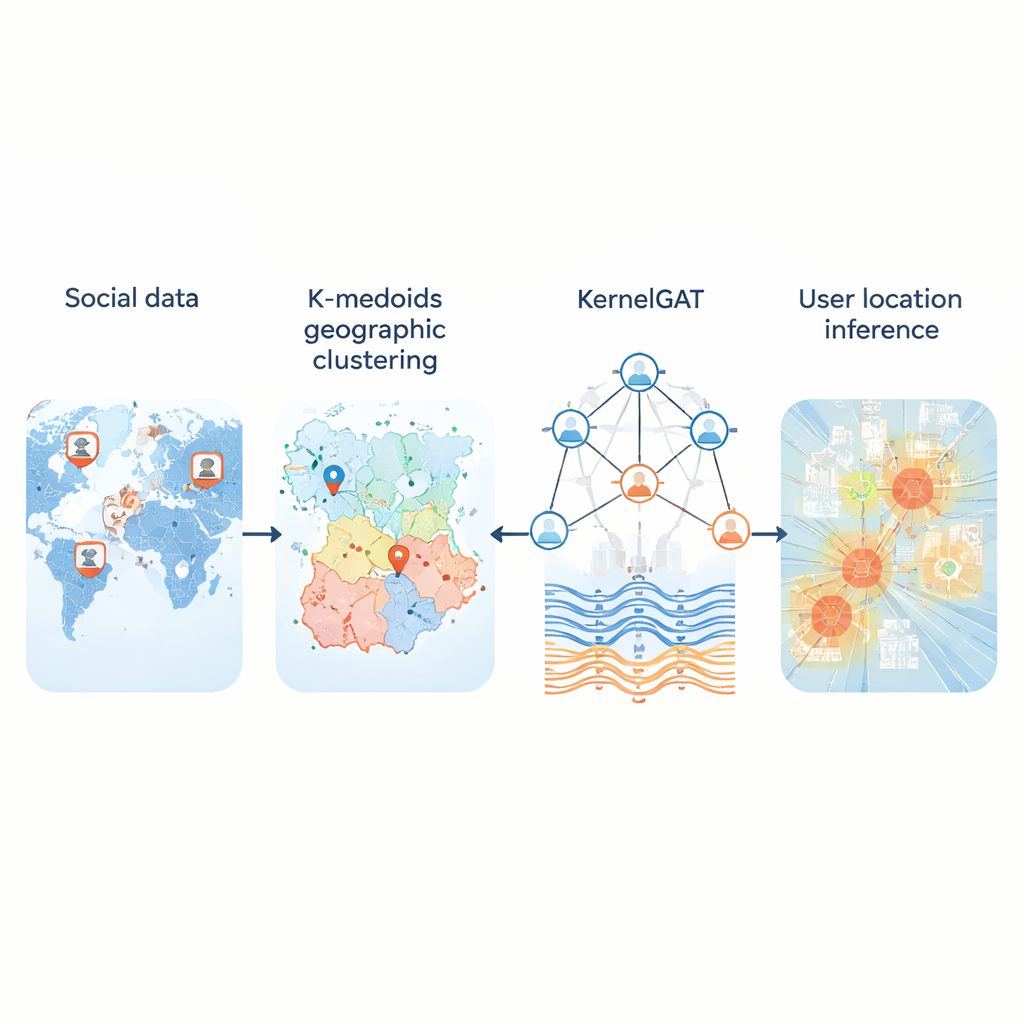
Every day, millions of people post on social media without sharing their GPS coordinates. Yet those posts still leave clues about where users live, work, and travel. Being able to infer location from this public trail matters for everything from emergency response and disease tracking to local recommendations and targeted services. This paper introduces a new method, called KMKGAT, that uses both what people say and how they are connected online to estimate where they are, more accurately than earlier approaches.
From online chatter to real-world places
When users write tweets or microblogs, they may mention place names, use local slang, or interact with nearby friends. Companies like Twitter (now X) know a user’s internet address, but outside researchers and service providers usually do not. Instead, they must work with public information: the text itself, user profiles, and who talks to whom. Earlier methods fell into three camps. Content-only methods mined words and hashtags to guess locations. Network-only methods relied on the fact that people tend to interact with nearby users. A third, more powerful family combined both views, but still had blind spots—especially for people in sparsely populated areas and for users whose online connections span large distances.
Smarter geographic grouping with real user centers
A key problem is how to turn the continuous globe into a set of regions a computer can learn to predict. Many systems slice the map into a fixed grid. That works reasonably well in cities but fails in rural areas, where huge cells cover many hundreds of kilometers. The new method replaces rigid grids with k-medoids clustering, a way of grouping users so that each region is centered on an actual user instead of an artificial point. This makes the regions compact and less sensitive to outliers, particularly where users are sparse. In tests on three large Twitter datasets covering the United States and the world, this adaptive partitioning reduced typical errors compared with grid-based schemes and provided more realistic “home regions” for users.
Letting the network focus on nearby, similar users
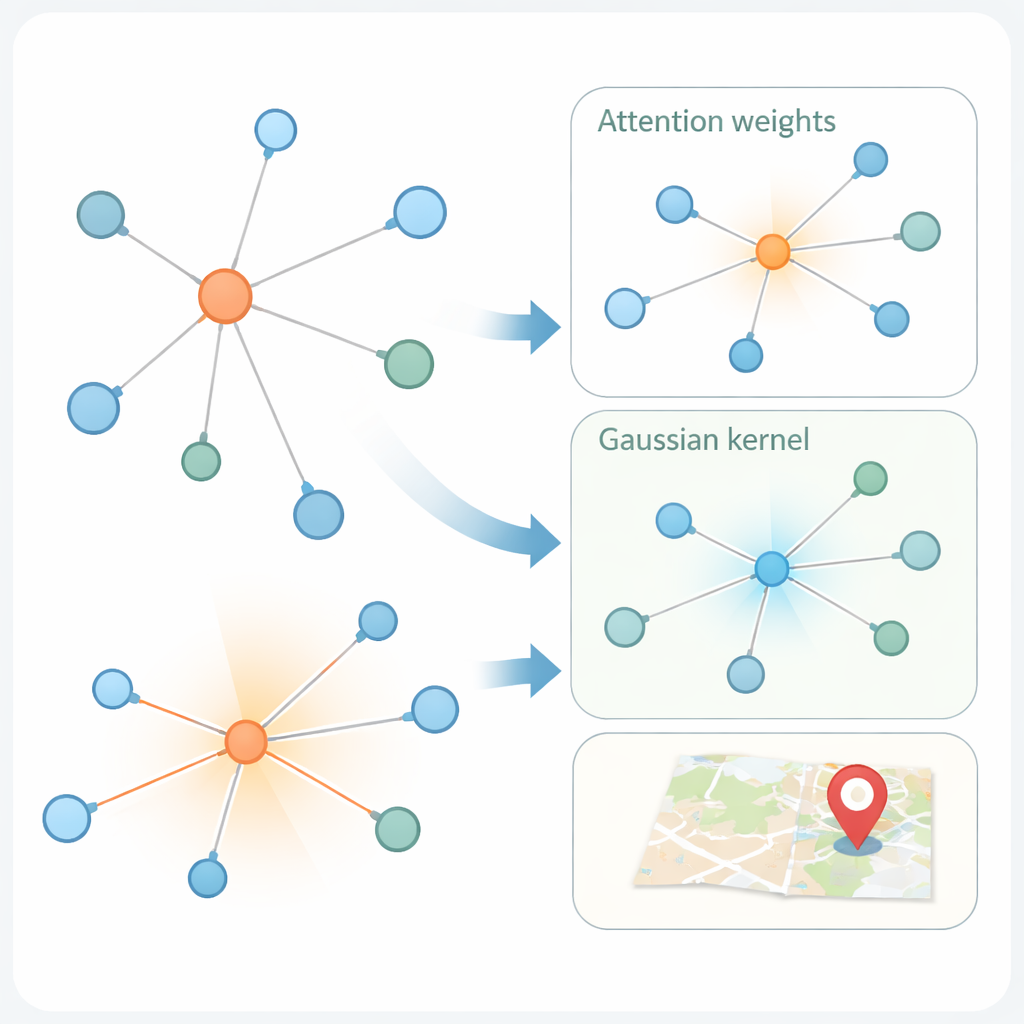
The second innovation lies in how the model learns from the social graph. Modern “graph attention networks” already weigh a user’s neighbors differently, based on how similar their feature representations are. But similarity alone can be misleading: an account in New York and another in London might use similar language yet be far apart geographically. KMKGAT augments attention with a Gaussian kernel, a mathematical filter that favors neighbors whose learned features are close to the target user and dampens the influence of distant ones. Multiple such kernels, combined like a mixture of lenses, allow the model to capture locality at different scales. This respects the simple but powerful principle that online interactions are often strongest among people who are physically closer.
Lightweight text features that still carry location hints
Rather than rely on heavy deep-language models, which can struggle with the noisy, slang-filled style of tweets, the authors use a classic technique called TF–IDF to turn each user’s collection of posts into a bag of weighted keywords. Common words like “the” or “lol” get little weight, while rarer, region-specific terms rise to the top. These text features are then attached to each user in the social graph and passed through the enhanced attention network. Interestingly, the best results came when most text features were randomly dropped during training, suggesting that only a small fraction of words actually help with location and the rest mostly add noise.
Beating the state of the art at scale
To judge performance, the researchers asked how far, in kilometers, the predicted region center was from each user’s known coordinates, and what percentage of users were placed within 161 km (100 miles) of their true location. Across three benchmark Twitter datasets, KMKGAT consistently matched or outperformed strong existing systems, improving the within-161-kilometer accuracy by up to a few percentage points—a meaningful gain at this level of maturity. The benefits were clearest on small and medium-sized networks, while on a massive global graph the method was limited by having to sample only immediate neighbors during training.
What this means in everyday terms
For non-specialists, the takeaway is that it is increasingly feasible to estimate where social media users are, even if they never share a location tag. By grouping users into realistic regions based on actual accounts, and by teaching the model to trust mostly nearby, similar neighbors in the social network, KMKGAT narrows down where someone likely lives or posts from. This can help responders find people during disasters, improve local search and recommendation, and support studies of how information spreads across places. At the same time, it highlights how much our ordinary online interactions can reveal about our offline lives, underscoring the importance of thoughtful data use and privacy protections.
Citation: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Keywords: social media geolocation, Twitter user location, graph neural networks, location-based services, online privacy