Clear Sky Science · en
Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning
Why protecting shared models matters
Our phones, hospitals, and banks are increasingly powered by artificial intelligence. Often, many organizations would like to train a shared model together, but laws and common sense say they must not pool their raw data in one place. Federated learning was invented to solve this tension: each participant trains on their own device and only shares model updates. But this paper shows that even those updates can leak private information if the central server is curious or dishonest—and then introduces a new way to keep both our data and our identities safer.
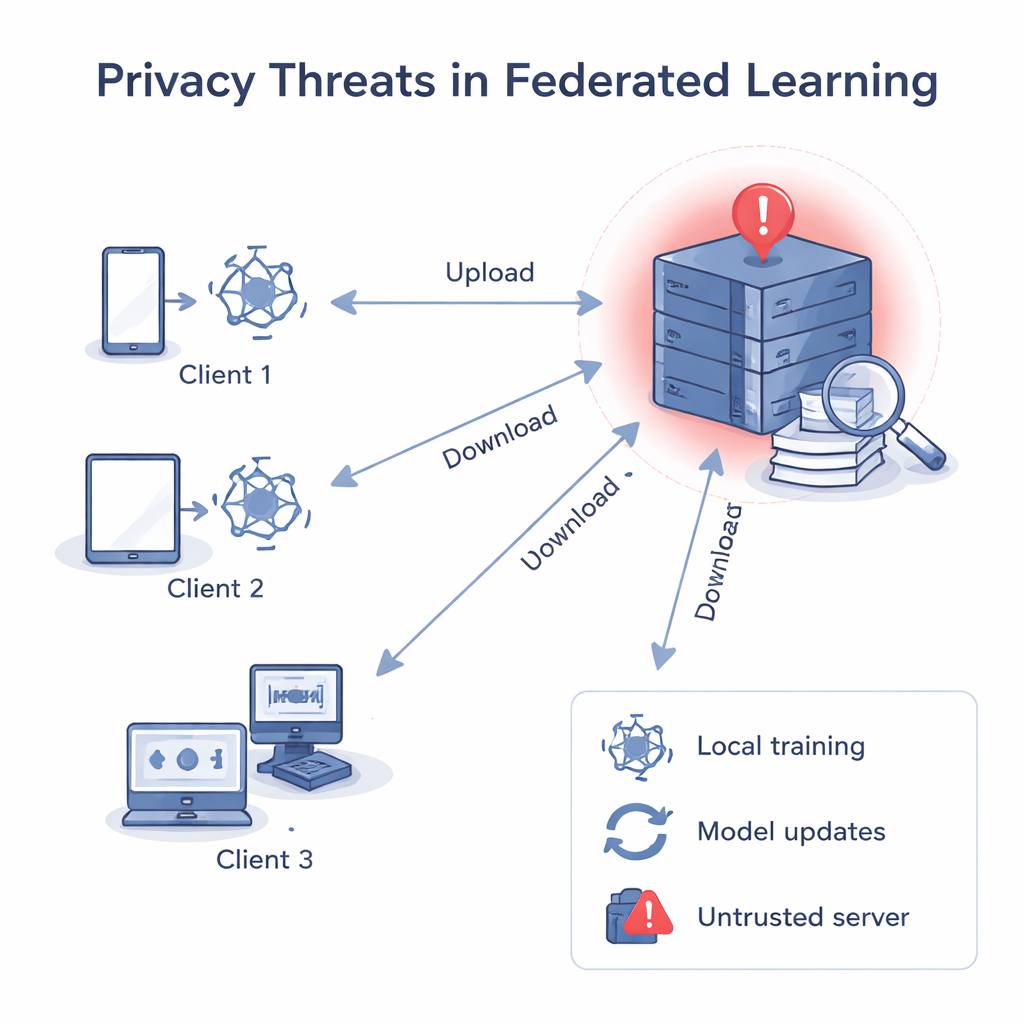
When the server shouldn’t be trusted
In classic federated learning, a central server sends out a common model, each client improves it using their own data, and then sends the updated model back. The server averages these updates into a better global model. Even though raw data never leaves the devices, past research has shown that gradients and weights—the numbers inside the model—can be “run backwards” to reconstruct private data, such as images or text, or to guess whether a specific record was used in training. If the central server is untrustworthy, it can analyze each client’s update separately, learn about that client’s local data, and even link an update to a particular person or organization.
Breaking updates into harmless pieces
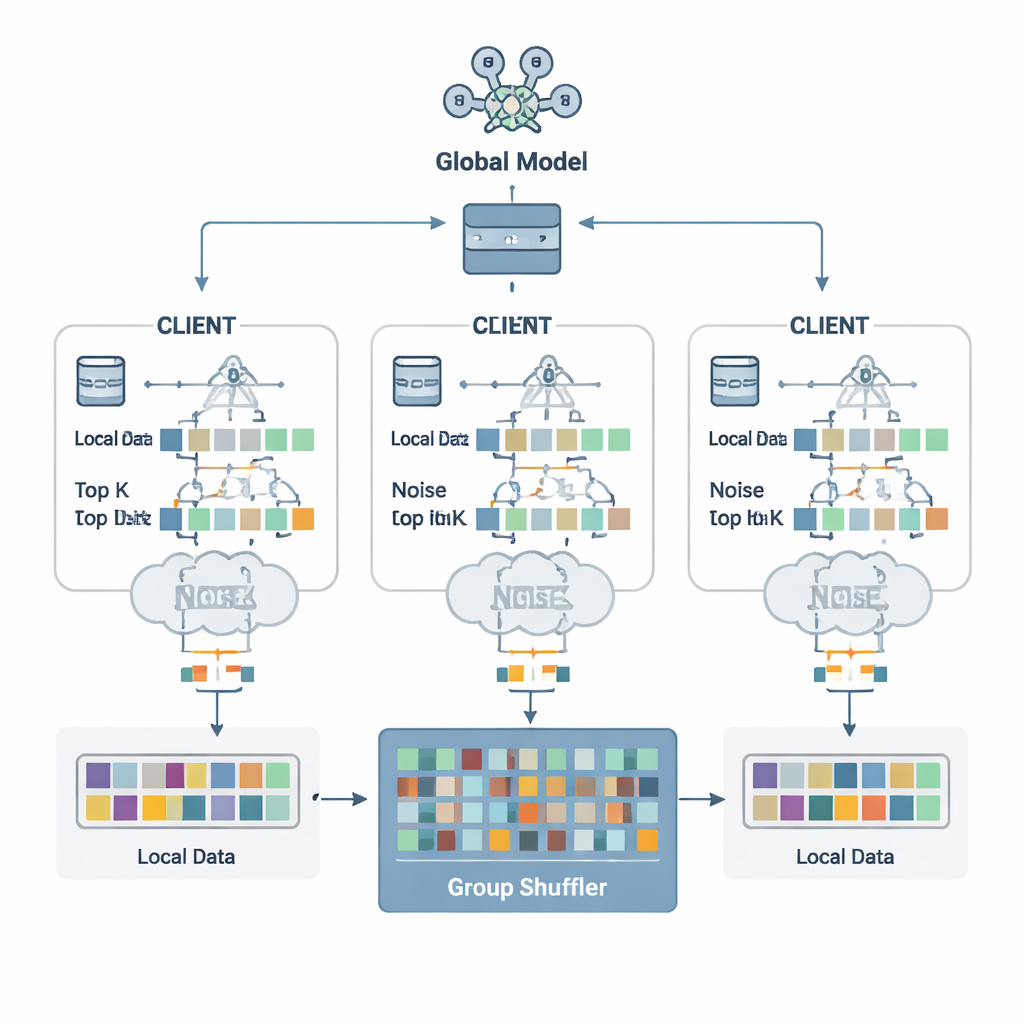
The authors propose a defense scheme called Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS). Its first idea is simple but powerful: never send a complete update. Instead, each client splits its model update into several artificial “fragments.” Most of these are filled with random numbers, and only the last one is adjusted so that all fragments still add up to the true update. Any single fragment, or even several of them, looks like noise and reveals almost nothing about the original data. This mathematical trick is similar to secret sharing: only by combining all pieces can one recover the whole.
Adding noise and stirring the pot
Sending many fragments could still be wasteful and, if examined together, might allow an attacker to infer more. To avoid this, each client selects only the most important fragment values—the Top-K entries that matter most for learning—and adds carefully calibrated random noise to them following the principles of differential privacy. This noise makes it statistically hard to tell whether any one person’s data influenced a given value. Next comes the second key ingredient: group shuffling. Instead of sending fragments straight to the server, clients forward them to a trusted “shuffler” that mixes fragments from many clients into groups before forwarding them on. After this mixing, the server can no longer tell which fragment came from which client, severing the link between updates and identities.
Keeping accuracy while cutting leaks
The team tested SDPFGS on standard image and text benchmarks, including handwritten digits (MNIST), clothing photos (Fashion-MNIST), and color images (CIFAR-10 and CIFAR-100), as well as a news classification task. They compared their method with several state-of-the-art privacy techniques that use noise alone, shuffling alone, or simple gradient compression. Across these experiments, SDPFGS consistently matched or exceeded the accuracy of competing methods while using less communication and training time than many of them. Most notably, under model inversion attacks—where an adversary tries to reconstruct training examples—SDPFGS had the lowest attack success rate, meaning it leaked the least about the underlying data.
What this means for everyday users
For a layperson, the take‑home message is that "hiding the data" is not enough; we must also hide what our devices send during training. SDPFGS does this by turning each model update into noisy, shuffled fragments that are useless on their own but still combine into a high‑quality global model. The result is a stronger shield against a curious or compromised server, with only minor cost to accuracy and efficiency. As federated learning spreads into health care, finance, and smart devices, techniques like SDPFGS could help ensure that people benefit from powerful shared models without handing over the keys to their private lives.
Citation: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Keywords: federated learning, data privacy, differential privacy, model inversion attacks, secure aggregation