Clear Sky Science · en
Disagreement between human and AI evaluation of treatment plans
Why this matters for everyday medical care
As artificial intelligence (AI) tools start helping doctors choose treatments, a key question arises: whose judgment do we trust more—humans or machines? This study looks at a simple but unsettling possibility: doctors and AI systems may disagree not only on which treatment is best, but also on what counts as a “good” treatment plan in the first place. Understanding this gap is essential if we want AI to support, rather than quietly distort, real-world medical decisions.
A head-to-head test of treatment advice
The researchers focused on dermatology, a field where doctors manage long-term skin conditions that rarely have a single “correct” answer. Ten experienced dermatologists and two large language models (LLMs)—a general-purpose model and a reasoning-focused model—were each asked to write treatment plans for five challenging, made-up cases, such as severe eczema, psoriasis with other illnesses, and pregnancy-related acne. To keep things fair, all 60 plans were edited into a common format: similar length, structure and tone. Any obvious hints about whether a human or an AI wrote the plan were removed, so later judges would be rating content, not style.
How humans and AI did the judging
The plans then went through two rounds of blind scoring using the same rubric. First, the same group of ten dermatologists rated every plan on overall quality from 0 to 10, considering how effective, safe, practical and patient-centered it was. Second, a separate AI model—used only as a judge, not a plan writer—scored the very same plans with the same instructions. Crucially, neither the human raters nor the AI judge knew who had written any given plan. This setup let the authors isolate one key factor: whether the evaluator was human or AI.
Humans back humans, AI backs AI
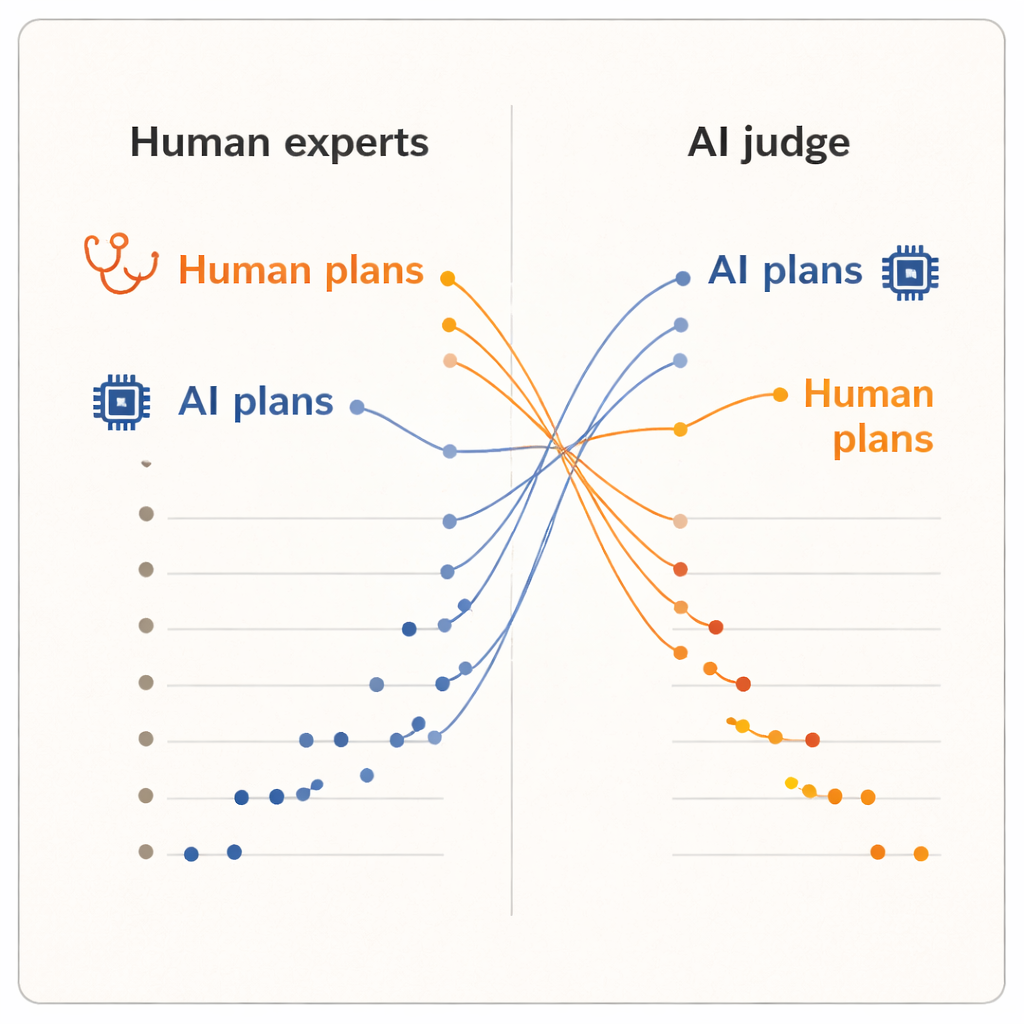
The results showed a clear “evaluator effect.” When humans scored the plans, they gave higher marks to plans written by their fellow dermatologists than to those written by either AI system. Human-generated plans had a slightly higher average score and occupied the top five positions in the ranking. One of the AI models, the advanced reasoning system, landed near the bottom. But when the AI judge took over, the picture flipped. Now, the two AI-written plans rose to the top of the ranking, and every human dermatologist’s plan fell below them. On average, the AI judge scored AI-generated plans higher than human-generated ones, even though it was reading the exact same, standardized text that the dermatologists had seen.
Different ideas of what makes a "good" plan
Because the plans were normalized for wording and the judges were kept blind to the source, the authors argue that this split cannot be explained by superficial polish. Instead, it suggests that humans and AI systems bring different internal yardsticks to the table. Clinicians likely lean on real-world experience: what tends to be feasible in their clinics, how patients react, and which trade-offs feel acceptable in practice. By contrast, an AI judge trained on large text collections may favor plans that follow patterns common in the medical literature or guidelines, even if those patterns do not fully capture local constraints or patient preferences. The study is modest in size—only ten clinicians, five cases and a single AI judge—and it measures perceived quality, not actual patient outcomes. Still, the reversal is striking enough to raise deeper questions about how we evaluate clinical AI.
Rethinking how we test and use clinical AI
From these findings, the authors draw two broad lessons. First, traditional “right-answer” tests for medical AI miss much of what matters in real care, where plans must juggle effectiveness, safety, cost, logistics and patient wishes. They argue for richer, multi-metric evaluation frameworks that explicitly score these dimensions, use multiple human and AI judges, and analyze where and why disagreements arise instead of collapsing everything into a single score. Second, they suggest that differences between human and AI judgments can be a feature, not just a bug. If used carefully, AI-generated plans might serve as a thoughtful second opinion that prompts doctors to revisit their assumptions, while doctors provide the real-world context and ethical judgment AI lacks. Building trustworthy, transparent interfaces that expose assumptions, allow clinicians to adjust priorities and invite critical review could help turn this tension between human and AI perspectives into safer, more balanced decision-making.
Citation: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Keywords: clinical decision support, artificial intelligence in medicine, human AI collaboration, treatment planning, evaluation bias