Clear Sky Science · en
QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks
Smarter Sensor Networks for a Connected World
From precision farming to disaster warning systems, wireless sensor networks quietly monitor our world, gathering data from hundreds or thousands of tiny devices scattered over large areas. Their biggest weakness is also their defining feature: each sensor runs on a small battery that is hard or impossible to replace. This paper presents a new way to organize and steer the flow of data in these networks so that batteries last longer, information travels more reliably, and the network adapts when conditions change.
Why Tiny Devices Need Big Intelligence
In a wireless sensor network, each node can sense, compute, and communicate, but energy is precious. If some nodes do too much work, they die early, creating “dead zones” where no data can be collected. To avoid this, designers typically group nodes into clusters. Within each cluster, one node becomes the cluster head: it collects readings from its neighbors and forwards them toward a central base station. Choosing which nodes should be cluster heads, and how data should hop across the network, is a complex puzzle that changes as batteries run down. Traditional rule-based or single-algorithm solutions often settle too quickly on sub‑optimal patterns or fail when the network’s shape and energy levels evolve over time.
Blending Quantum-Inspired Swarms with Learning Machines
This study introduces QPSODRL, a protocol that marries two powerful ideas: a quantum‑inspired swarm method for forming clusters and a deep reinforcement learning engine for routing. In the first stage, virtual “particles” explore different ways to assign cluster heads and members. Their behavior is guided by a measure of how evenly energy is spread across the network, known as entropy. When energy use is unbalanced, the algorithm encourages broad exploration of new cluster layouts; when things look stable, it fine‑tunes promising arrangements. A special “elite perturbation” step occasionally nudges the best candidates in new directions, helping the search escape local dead ends and avoid overusing the same high‑energy nodes. 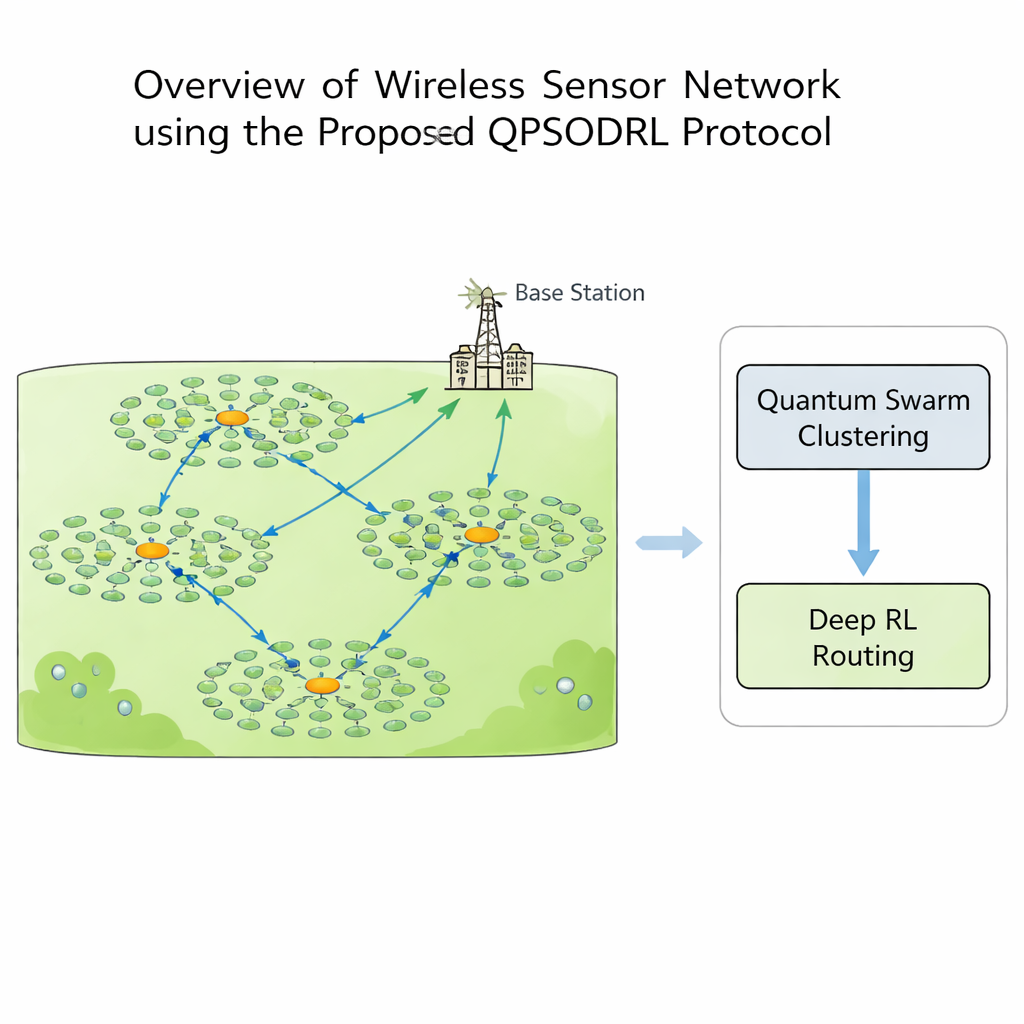
Teaching the Network to Learn Better Paths
Once clusters are formed, the second stage decides how each cluster head should send its data to the base station. Instead of following fixed routes, QPSODRL treats each cluster head as an agent in a learning process. At every step, the agent observes its own remaining energy, the energy and distance of neighboring heads, and estimated delays, then chooses the next hop. A specialized form of deep Q‑learning, called Dueling Double Deep Q‑Network, estimates how good each choice is in the long run. The authors add an “entropy” term to discourage the system from becoming too confident too quickly, so it keeps exploring alternative routes. They also design an enhanced experience replay mechanism that deliberately focuses learning on the most informative situations—such as when energy is low or delays spike—so the model improves faster in the scenarios that matter most. 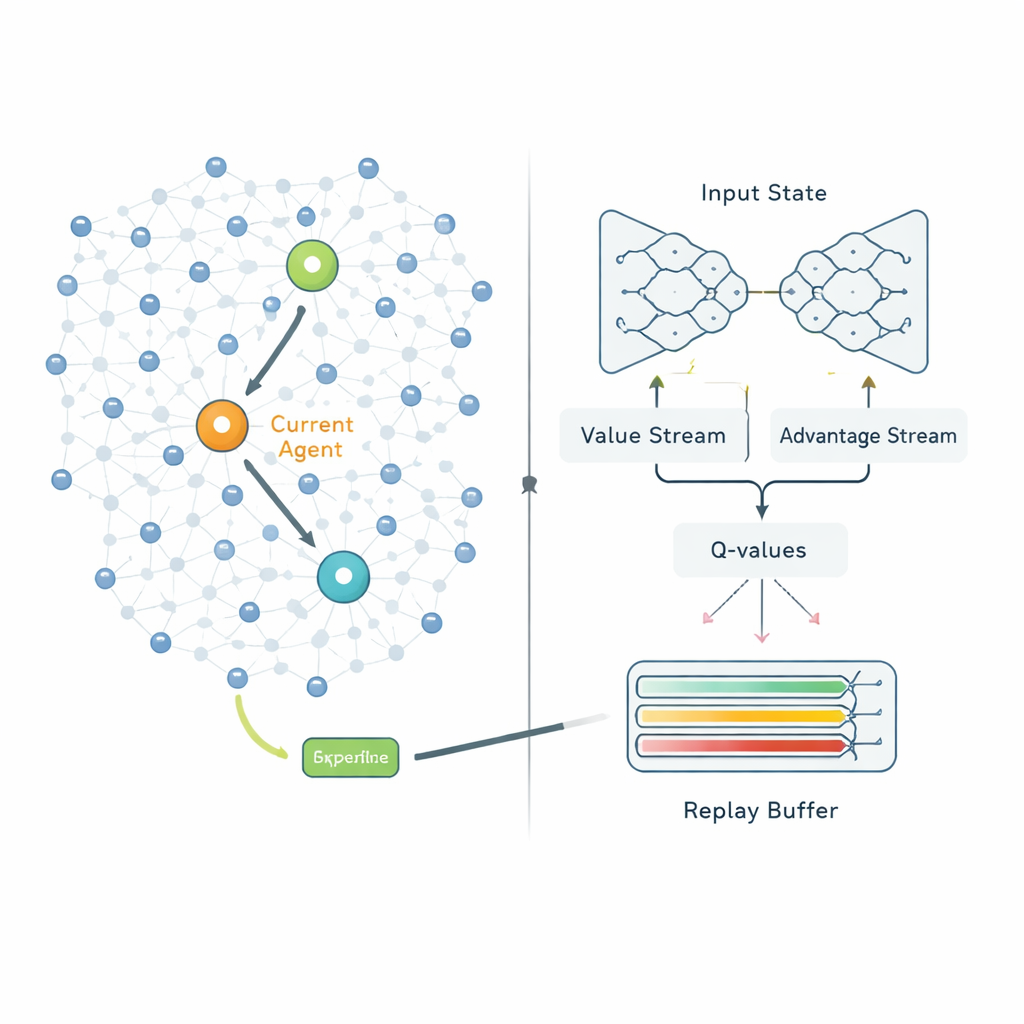
Putting the Approach to the Test
To see how QPSODRL performs, the author runs detailed computer simulations of networks with 100 and 200 nodes spread over areas of different sizes and with different fractions of nodes acting as cluster heads. The new protocol is compared with four recent and advanced competitors that use particle swarms, whale optimization, fuzzy logic, or other hybrid and learning‑based schemes. Under all tested setups, QPSODRL keeps the network alive for more communication rounds, delivers more data packets to the base station, and consumes less total energy. It also spreads the workload among cluster heads more evenly, as shown by a lower variation in how much traffic each head handles. These gains are especially pronounced in tougher layouts where the base station is placed at the edge of the field, forcing longer hops for some nodes.
What This Means for Real-World Systems
For non‑specialists, the key message is that giving sensor networks the ability to both globally optimize their structure and locally learn from experience can significantly extend their useful life. QPSODRL’s quantum‑inspired clustering keeps energy usage balanced, while its deep learning‑based routing adapts to changing conditions without constant human tuning. Although the results are based on simulations with fixed, non‑moving nodes, they suggest that future sensor deployments—from smart cities to environmental observatories—could run longer, fail less often, and make better use of limited battery power by adopting similar intelligent control strategies.
Citation: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Keywords: wireless sensor networks, energy-efficient routing, deep reinforcement learning, swarm optimization, network clustering