Clear Sky Science · en
Knowledge integration for physics-informed symbolic regression using pre-trained large language models
Teaching Computers to Guess Nature’s Formulas
Many of the big ideas in science are captured as neat little equations: from how a ball falls to how light waves ripple through space. This paper explores a new way to help computers automatically rediscover such equations from raw data, by letting them consult a large language model—the same kind of AI that powers modern chatbots—so that their guesses are not just accurate, but also physically sensible.
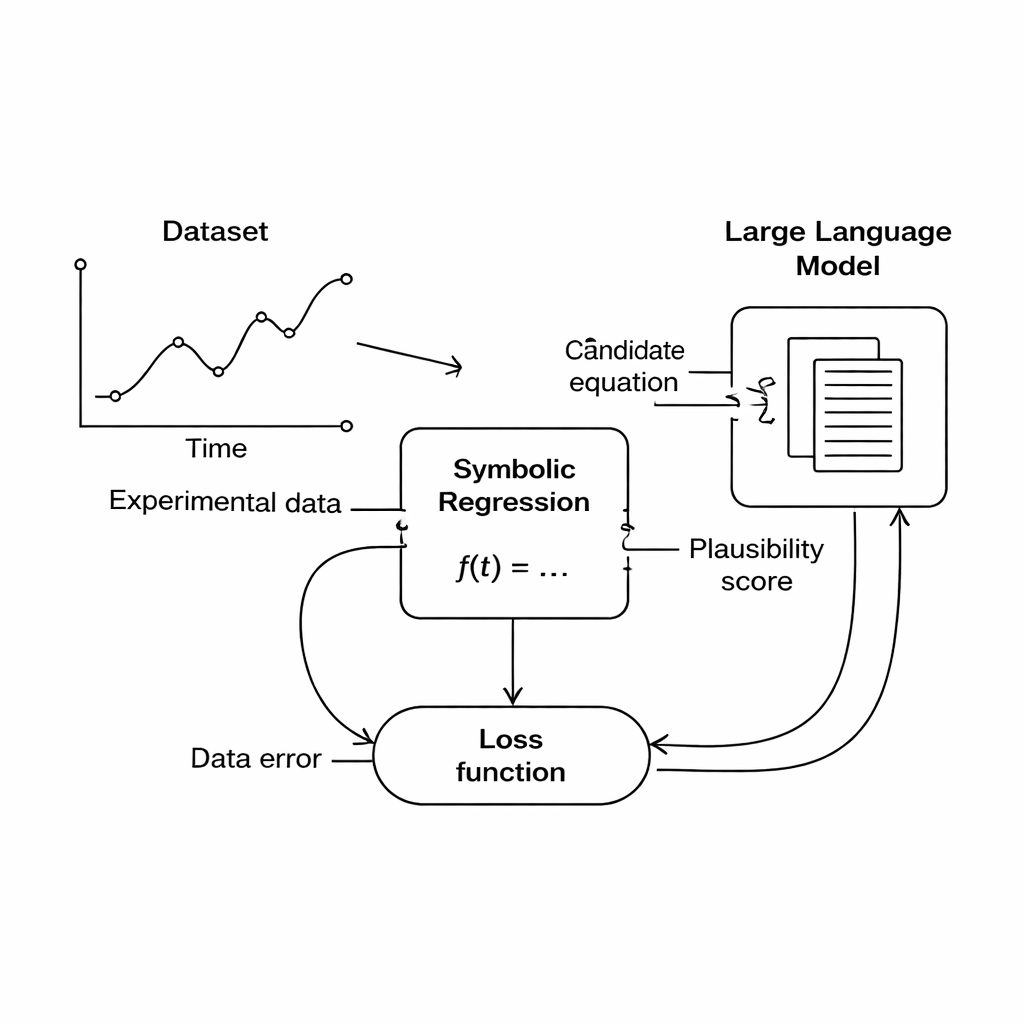
From Raw Data to Human-Readable Laws
The authors focus on a technique called symbolic regression, which searches for a mathematical formula that links measured inputs and outputs. Unlike ordinary curve fitting, symbolic regression does not start with a fixed formula shape; instead, it builds and evolves candidate equations until one fits the data well. This makes it a promising tool for scientific discovery, because it can potentially uncover new relationships that no one has written down before. Yet there is a catch: a formula that fits the data perfectly can still be nonsense from a physics standpoint—for example, adding a distance to a time or producing units that do not match any real quantity.
Why Physical Insight Still Matters
To avoid such nonsense, researchers have developed “physics-informed” versions of symbolic regression that bake known rules of nature into the search. These methods reward equations that, for instance, conserve energy or respect dimensional consistency. However, encoding this knowledge has typically required experts to handcraft constraints and special loss functions for each new problem. That makes the approach powerful but hard to generalize. Every new physical system may need its own careful design work, limiting the accessibility of these tools to non-experts.
Letting Language Models Judge the Equations
This study proposes a different route: instead of hard-coding domain rules, use a large language model (LLM) as a flexible judge of scientific plausibility. During the search, the symbolic regression engine produces candidate equations that fit the data to some degree. Each equation is then translated into text and sent to the LLM, along with a short prompt describing the quantities involved and any known physical constraints. The LLM returns scores for three aspects: whether the equation’s units make sense, how simple it is, and whether it seems physically realistic. These scores are folded into the main objective function, so the computer now balances “fits the data” against “looks like good physics” when choosing which equations to keep improving.
Putting the Method to the Test
To see how well this works, the authors ran extensive computer experiments on three classic problems: the free fall of a ball in Earth’s gravity, simple harmonic motion of a mass on a spring, and a damped electromagnetic wave. For each system they simulated thousands of noisy measurements under varied conditions, then asked three popular symbolic regression programs to recover the underlying equations, either with or without help from an LLM. They tried three compact, open-source language models—Mistral, Llama 2, and Falcon—and explored how different prompt designs, from minimal context to full descriptions and even the true formula, changed the LLM’s guidance. Across most settings, adding the LLM score improved how closely the recovered equations matched the known laws and made them more robust to noise, with the combination of PySR (a symbolic regression library) and Mistral generally performing best.
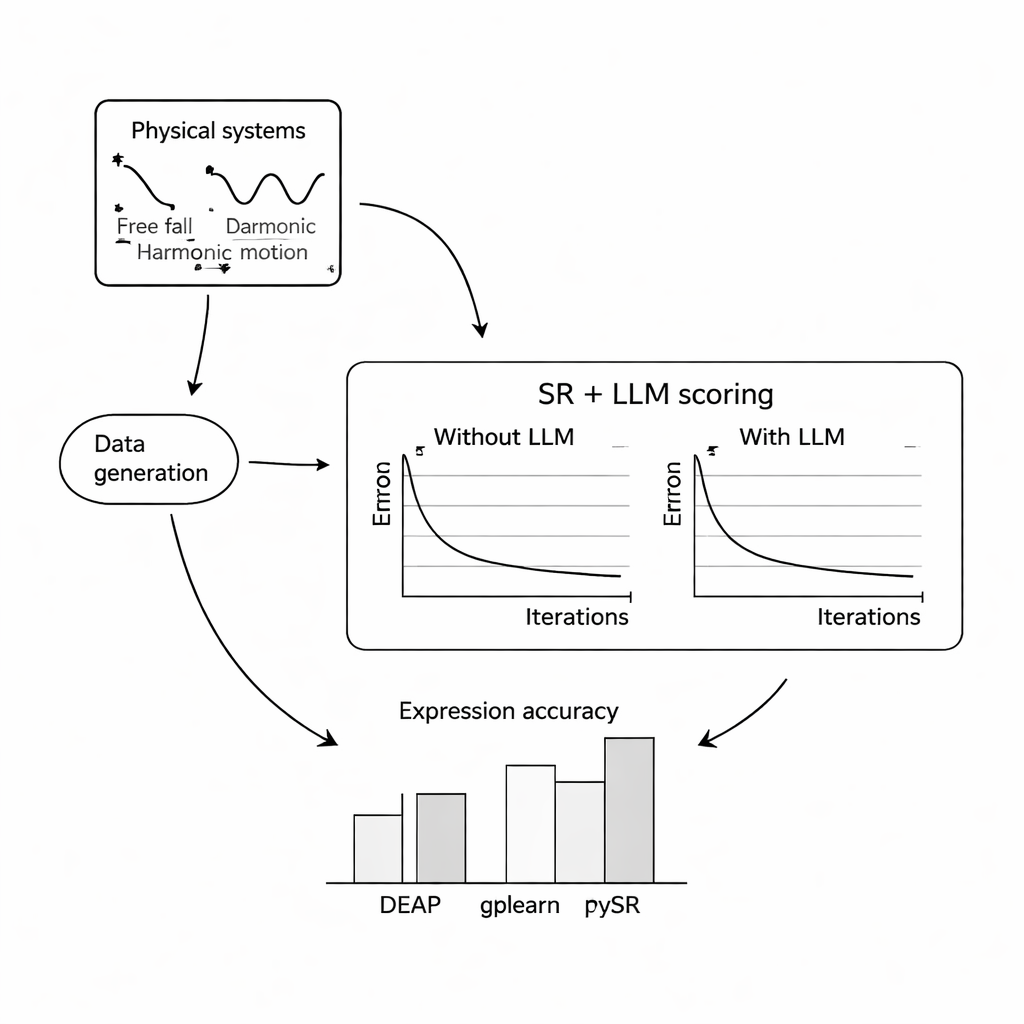
When Words Steer the Math
A key finding is that the wording of the prompt strongly affects outcomes. When prompts included clear descriptions of variables, the nature of the experiment, and sometimes the exact target formula, the LLM-guided search more reliably converged to the correct structure. In these richer cases, the discovered equations were often structurally identical to the ground-truth laws, not just numerically close. The authors also tested how the approach holds up under increasing levels of random measurement noise. While all methods degraded as the data became noisier and the underlying equations more complex, the LLM-augmented versions tended to lose accuracy more slowly than their standard counterparts, suggesting that the language model’s sense of plausibility can act as a stabilizing influence.
What This Means for Future Discoveries
For general readers, the main message is that text-based AI can do more than write essays or answer questions—it can also guide other algorithms toward scientific equations that “feel right” according to our existing knowledge of nature. The method presented here does not guarantee that every discovered equation is correct, and it still relies on human oversight and carefully crafted prompts. But it shows that large language models, trained on oceans of scientific text, can serve as a reusable source of domain knowledge, helping automated tools move from blindly fitting data toward proposing laws that scientists can interpret, check, and build upon.
Citation: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Keywords: symbolic regression, physics-informed AI, large language models, scientific discovery, equation learning