Clear Sky Science · en
A deep reinforcement learning approach to dance movement analysis
Teaching Computers to Watch Dance Like We Do
From ballet to hip-hop, dance is full of subtle shifts in rhythm and pose that human eyes pick up instantly—but computers struggle to see. This study introduces a new way for artificial intelligence to “watch” dance videos more like a human expert, skimming past routine steps to focus on brief, revealing moments that define each style. The result is a system that recognizes dance genres more accurately while watching far less video, a potential boost for everything from digital archives to sports and entertainment technology.
Why Dance Videos Are Hard for Machines
At first glance, training a computer to recognize dance styles sounds simple: feed in videos and let deep learning find patterns. In reality, most existing systems waste effort. Standard video models either process every frame or sample clips at fixed intervals, assuming all moments are equally important. But dance styles often differ in tiny details—how a foot turns, when a partner pivots, or the timing of a spin—rather than in constant motion. That means many frames are either repetitive or uninformative, and key poses may fall between fixed sample points, leading to confusion between, say, a Waltz and a Foxtrot.
A Smarter Way to Skim Through Video
The researchers propose a framework called Reinforcement-based Attentive Temporal Sampling, or RATS, that treats video analysis as an active search rather than passive viewing. Instead of marching frame by frame, the system breaks a dance video into short clips and first converts each clip into a compact description of its movement using a specialized 3D convolutional network. These movement summaries are then stored in memory. On top of this, a decision-making agent steps through the clip sequence, choosing whether to move ahead by a small jump, a larger jump, or to stop and issue a style prediction. In effect, the system learns how to browse through time, lingering on telling patterns and skipping less useful stretches.
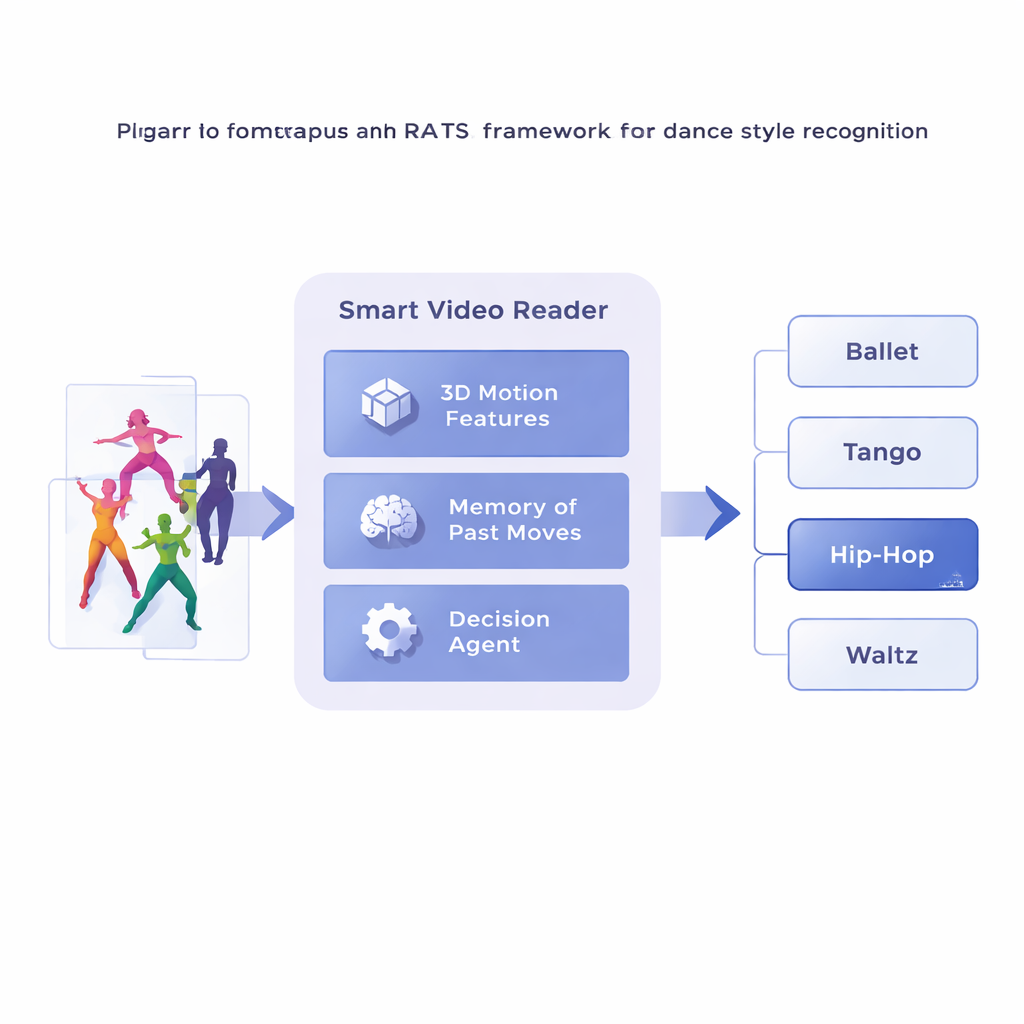
Learning When to Look and When to Decide
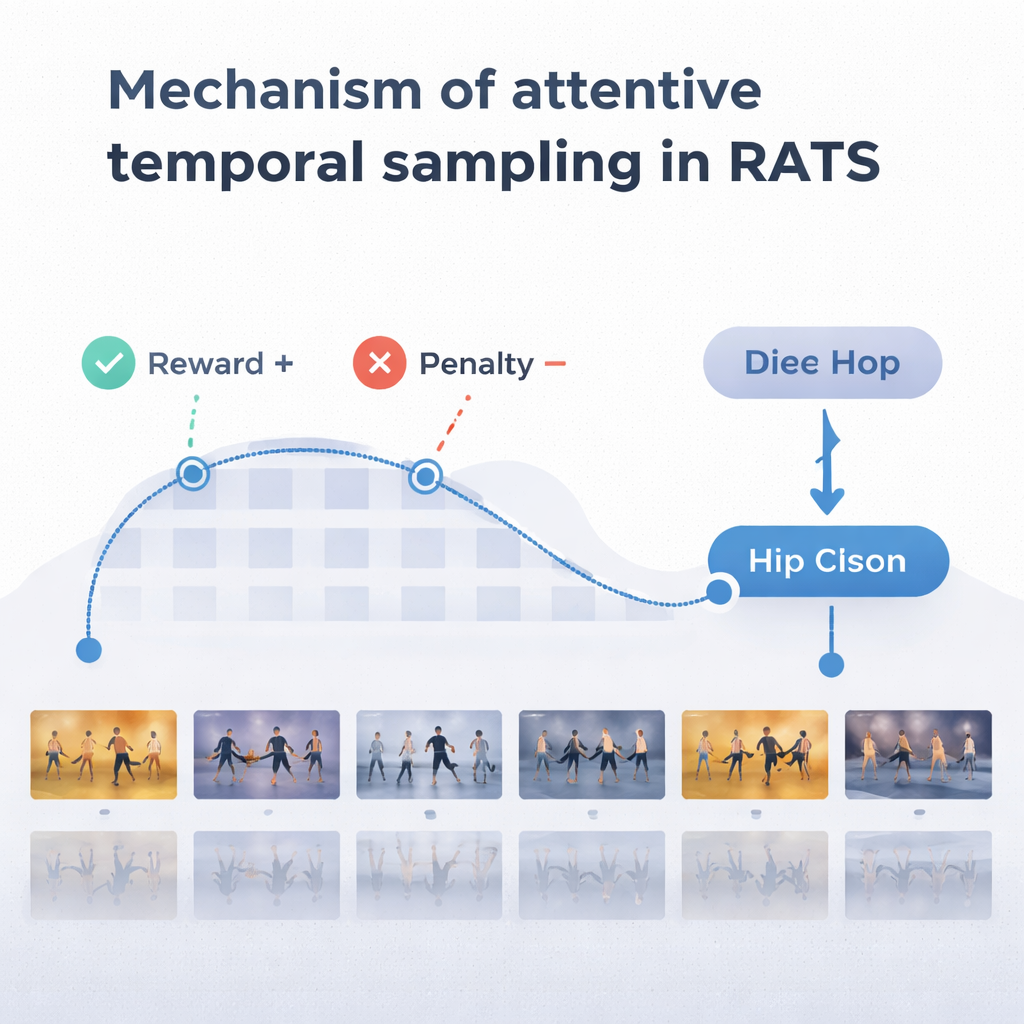
To make sensible choices, the agent relies on a form of memory inspired by how we recall both past and emerging motion. A bidirectional recurrent network keeps track of what the system has already “seen” and how current clips relate to that history. At each step, the agent weighs three options: take a short hop to inspect fine-grained details like footwork, make a longer leap over repetitive movement, or stop and classify the dance. The system is trained with rewards and penalties: it earns a large positive score for a correct decision, a large negative score for a wrong one, and a small penalty every time it jumps forward. This balance encourages the agent to be both accurate and efficient—waiting until it has enough evidence, but not wandering through the entire video.
Outperforming Conventional Dance Classifiers
The team tested RATS on the Let’s Dance dataset, a challenging collection of 1,000 videos covering ten styles, from Flamenco and Tango to Swing and Square dancing. Compared with several existing methods, including standard deep networks and other dance-focused models, RATS achieved the highest accuracy—about 92%—and the best overall balance of precision and recall. It also proved statistically better than strong competitors, not just slightly different by chance. Importantly, the system reached these results while, on average, analyzing only about 38% of video frames. Uniformly sampling every few frames was faster but missed crucial moments and dropped performance; processing every frame was slower and still less accurate than the targeted approach.
What This Means Beyond the Dance Floor
To a non-specialist, the core message is straightforward: computers can do a better job when they learn to be selective viewers. By teaching an AI to concentrate on “golden moments” in time, this work shows that machines can recognize complex human movements more accurately while using fewer resources. Although the study focuses on dance, the same idea could help systems pick out key elements in sports routines, security footage, or any long video where important events are brief and scattered. In other words, smarter watching—not more watching—may be the future of video understanding.
Citation: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Keywords: dance recognition, video analysis, deep learning, reinforcement learning, human movement