Clear Sky Science · en
Chinese spatial relation extraction model by integrating geographic semantic features
Teaching Computers to Understand Where Places Are
Every day we describe locations in simple phrases: a town lies south of a river, a park is near a university, a highway passes through a province. Turning this kind of everyday language into precise digital knowledge is vital for smart maps, navigation apps and geographic research. This paper presents a new method, called PURE‑CHS‑Attn, that helps computers read Chinese texts and automatically figure out the spatial relationships between places more accurately than before.
Why Spatial Language Matters
Spatial relations are words and phrases that tell us how places are connected in space, such as “inside,” “next to,” “north of,” or “30 kilometers from.” They form a bridge between the real world we see on maps and the concepts we use in our heads. In geographic information systems (GIS), these relations underpin how data are organized, searched and analyzed. They are also central in other fields: for example, combining satellite images, tracking motion in video, planning industrial layouts or studying how climate and landforms shape biodiversity. Because so much of this information is written in natural language, having reliable tools that can read text and extract spatial relations automatically is increasingly important.
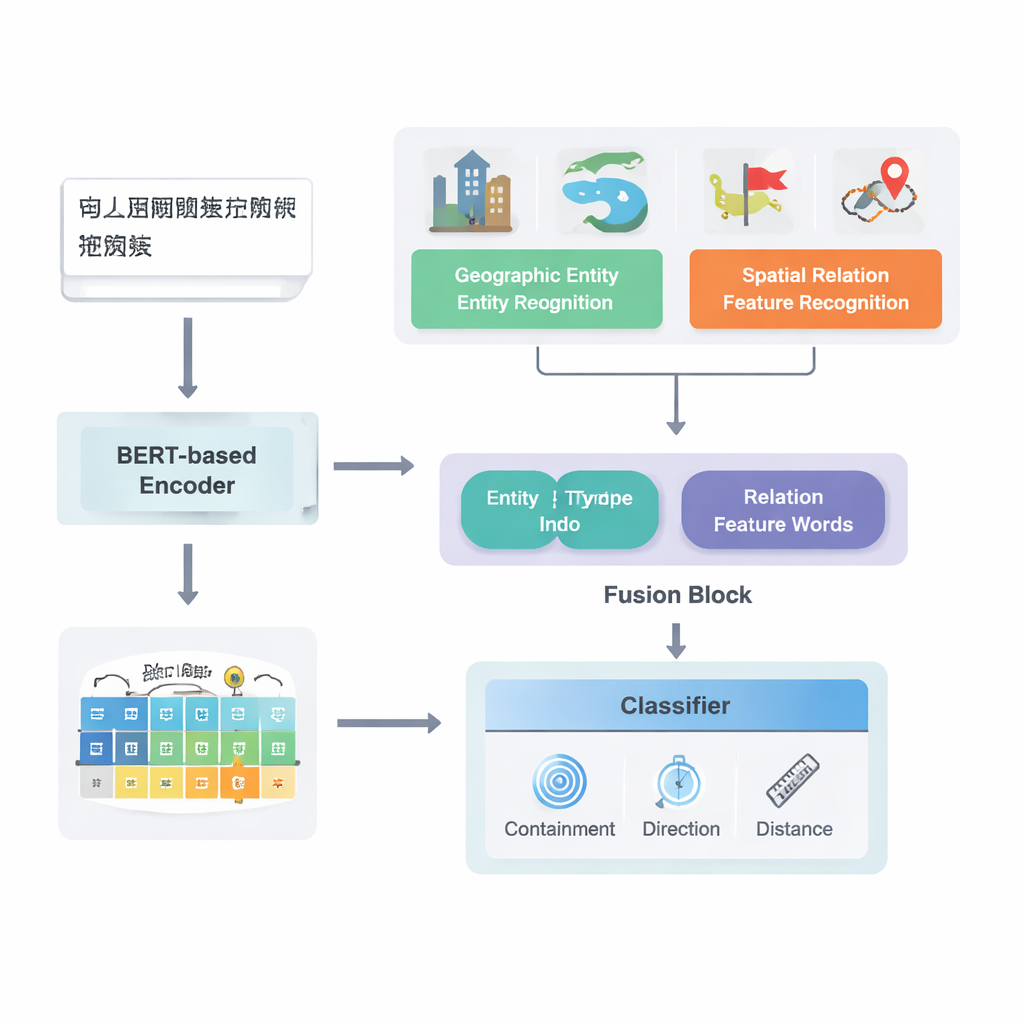
From Raw Text to Mapped Relationships
The authors focus on Chinese texts and build on a strong existing deep learning pipeline model known as PURE. Their enhanced model, PURE‑CHS‑Attn, works in several stages. First, it scans sentences to find geographic entities such as mountains, rivers, cities and administrative regions, and labels each with a type (for example, land surface, water body, public facility, historical site or administrative division). Next, it detects spatial relation “feature words” like “borders,” “flows through,” “south of” or “near,” which signal how two places are related. A powerful language model, BERT‑wwm‑ext, turns the characters in each sentence into numerical vectors that capture their meaning and context. These vectors feed separate components that recognize entities and relation words and then pass on their results to a fusion module.
Blending Human Knowledge with Machine Learning
A key novelty of the work lies in how it fuses geographic knowledge with learned text patterns. Instead of treating every word equally, the model exploits two kinds of semantic information that humans naturally use: the type of each geographic entity and the specific spatial feature words connecting them. The fusion module first combines the vectors for the two entities using weights that depend on how often different types of places (such as two administrative regions versus a river and a county) participate in different relation types. It then blends in the vectors of the spatial feature words. On top of this “basic fusion,” the authors add an attention mechanism that lets the model dynamically focus on the most informative parts of the entity–word combination. The final fused representation is passed to a classifier, which can assign one or more relation types—topological (like containment or adjacency), directional (north, south, etc.) or distance‑based—between each pair of places in the sentence.
Putting the Model to the Test
To evaluate their approach, the team assembled and carefully annotated a dataset from the Encyclopedia of China: Chinese Geography, containing 1381 sentences and 368 spatial relation pairs. They compared several versions of the model: a baseline that uses only coarse location information, a version with finer entity types, a version that also adds spatial feature words, and their full PURE‑CHS‑Attn model with the new fusion and attention design. By standard metrics of precision, recall and F1 score, PURE‑CHS‑Attn improved performance by about 7% in precision, 6.5% in recall and 6.7% in F1 over the baseline. It was especially strong in recognizing topological and directional relations, and it handled rare “few‑shot” relation types better than simpler models. When compared with three recent state‑of‑the‑art systems, including one based on large language models, PURE‑CHS‑Attn came in a close second while remaining much lighter and easier to deploy.
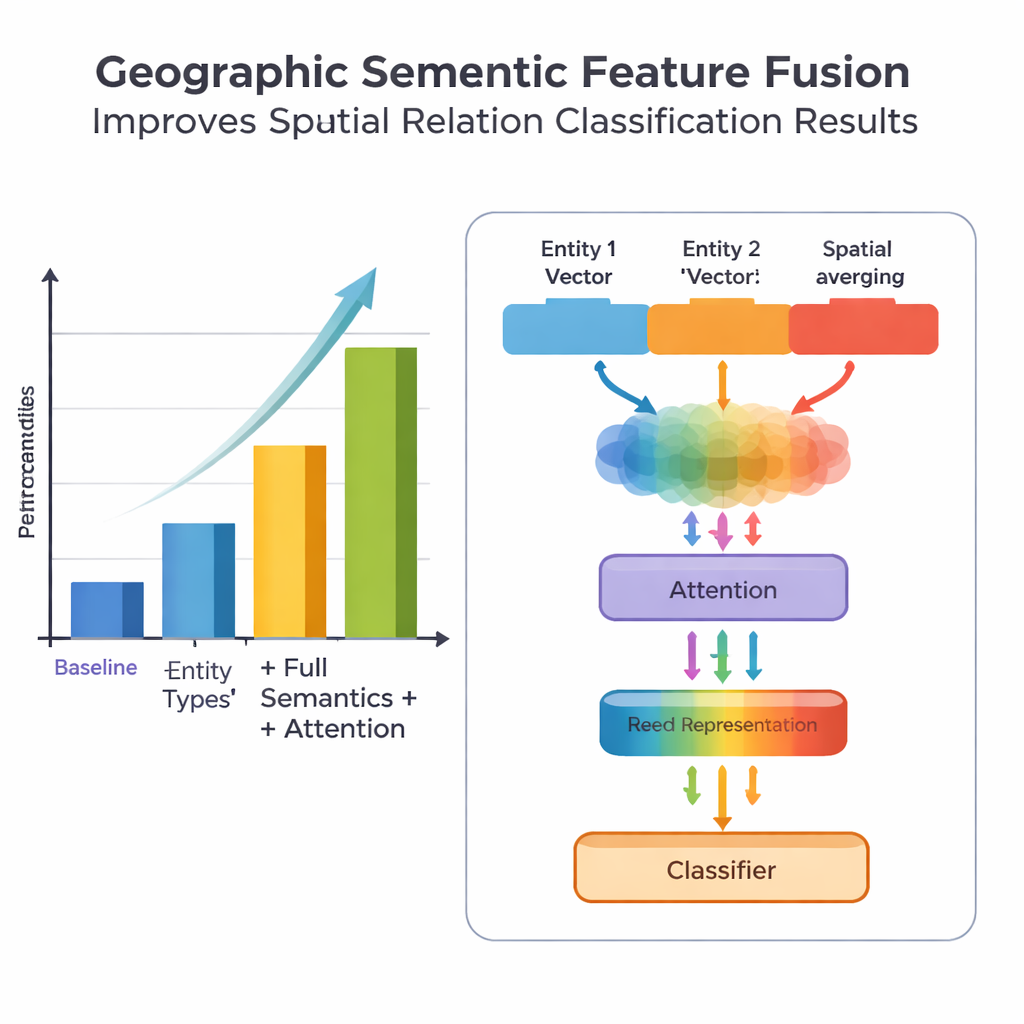
Challenges and Future Directions
Despite these gains, the model still struggles with distance relations, especially when only a handful of training examples exist. The authors show that their dataset contains very few such cases, which limits what any data‑hungry method can learn. They also note that blindly averaging many spatial feature words in a sentence can introduce noise, which their attention mechanism helps but does not fully solve. Looking ahead, they suggest two promising paths: expanding and balancing training data using augmentation, and combining their geographic semantic fusion with techniques from large language models and prompt‑based learning to further boost performance in data‑sparse scenarios while keeping the system efficient.
What This Means for Everyday Mapping
In simple terms, this research teaches computers to read spatial descriptions in Chinese more like humans do, by paying attention to what kinds of places are mentioned and exactly how their relationships are phrased. The PURE‑CHS‑Attn model shows that blending structured geographic knowledge with modern deep learning leads to more accurate and robust extraction of “who is where, relative to what” from text. This paves the way for smarter, more automated GIS systems, richer geographic knowledge graphs and better tools for exploring how space is described across science, policy and everyday communication.
Citation: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Keywords: spatial relation extraction, geospatial AI, geographic semantics, Chinese text mining, GIS automation