Clear Sky Science · en
Machine learning approach for wheat variety identification using single-seed imaging
Why smarter seed sorting matters
For farmers and seed companies, telling one wheat variety from another is crucial. Planting the wrong type can mean lower yields, poorer resistance to disease, and crops that are not suited to local soil or climate. Yet, to the naked eye, different wheat varieties look almost identical. This study explores how artificial intelligence and digital photos of single seeds can reliably tell closely related varieties apart, paving the way for faster, cheaper, and more objective seed quality control.
From expert eyeballing to camera-based checks
Today, many seed inspection systems still depend on human experts who visually judge seeds for variety and purity. This process is slow, expensive, and prone to disagreement, especially because many wheat cultivars differ only by subtle changes in shape or surface pattern. The authors set out to replace this subjective approach with an automated system that uses images of individual wheat grains taken in a small, light-controlled box. By carefully standardizing lighting, distance, and background color, they created a clean visual record of six common Iranian wheat varieties, generating tens of thousands of seed photos to train and test computer models.
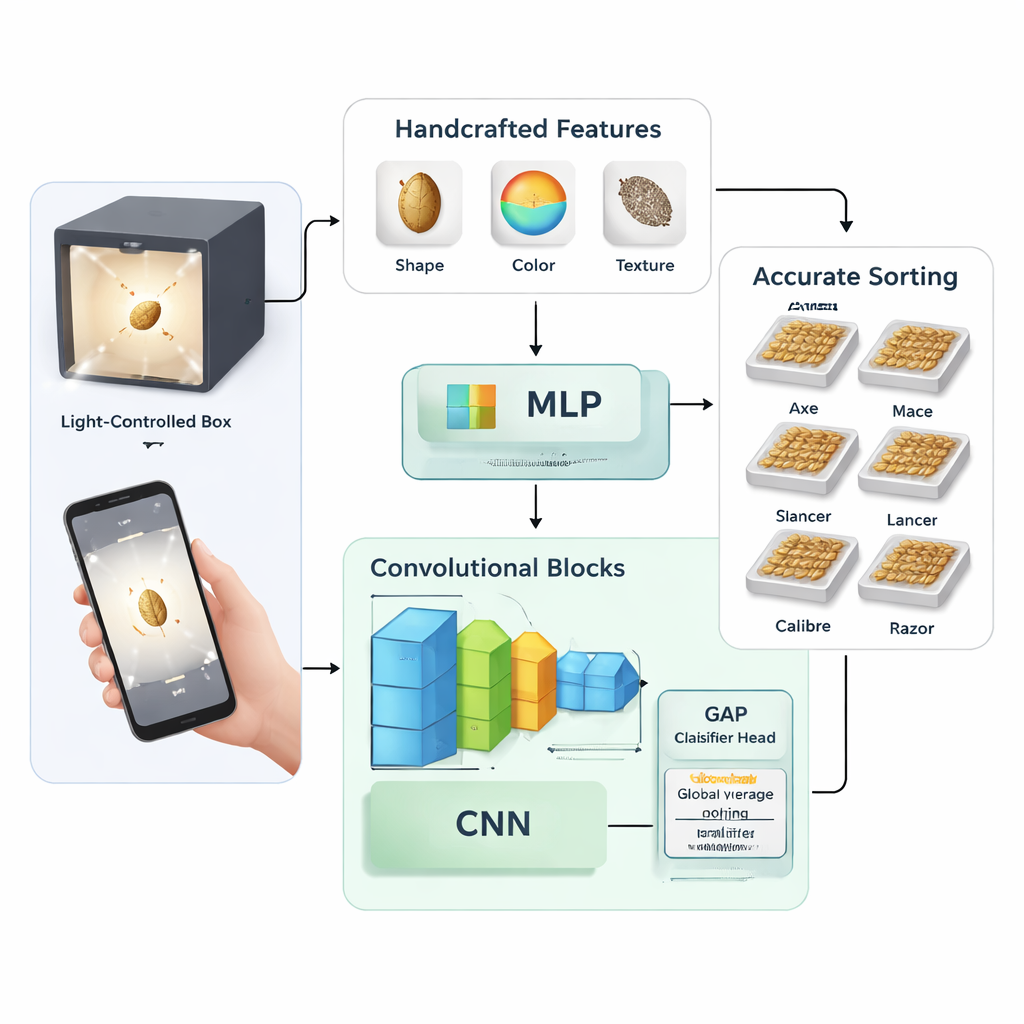
Two ways to teach a computer to see seeds
The study compares two broad strategies for teaching a machine to recognize wheat varieties. In the first, the researchers hand-crafted 58 numerical measurements from each seed image, including basic shape (such as length and area), color statistics across different color spaces, and texture patterns. They then used a technique called principal component analysis to condense these measurements into 27 key features, which were fed into a traditional neural network called a multilayer perceptron. In the second strategy, they skipped manual feature design and trained convolutional neural networks—image-focused AI models—to learn useful patterns directly from the raw pixel data.
Building a lean but powerful deep-learning model
The deep-learning approach was tested in several forms. The authors designed their own relatively small network with two to four stacked convolutional blocks and experimented with different training settings, such as learning rates, dropout levels, and batch sizes. They also compared two ways of finishing the network: a classic “fully connected” layer versus a more compact method called global average pooling, which replaces large dense layers with a simple averaging step before final classification. For context, they fine-tuned two heavyweight, widely used architectures—Inception-ResNet-v2 and EfficientNet-B4—on the same wheat dataset to see how a tailored small model stacks up against deep, general-purpose networks.
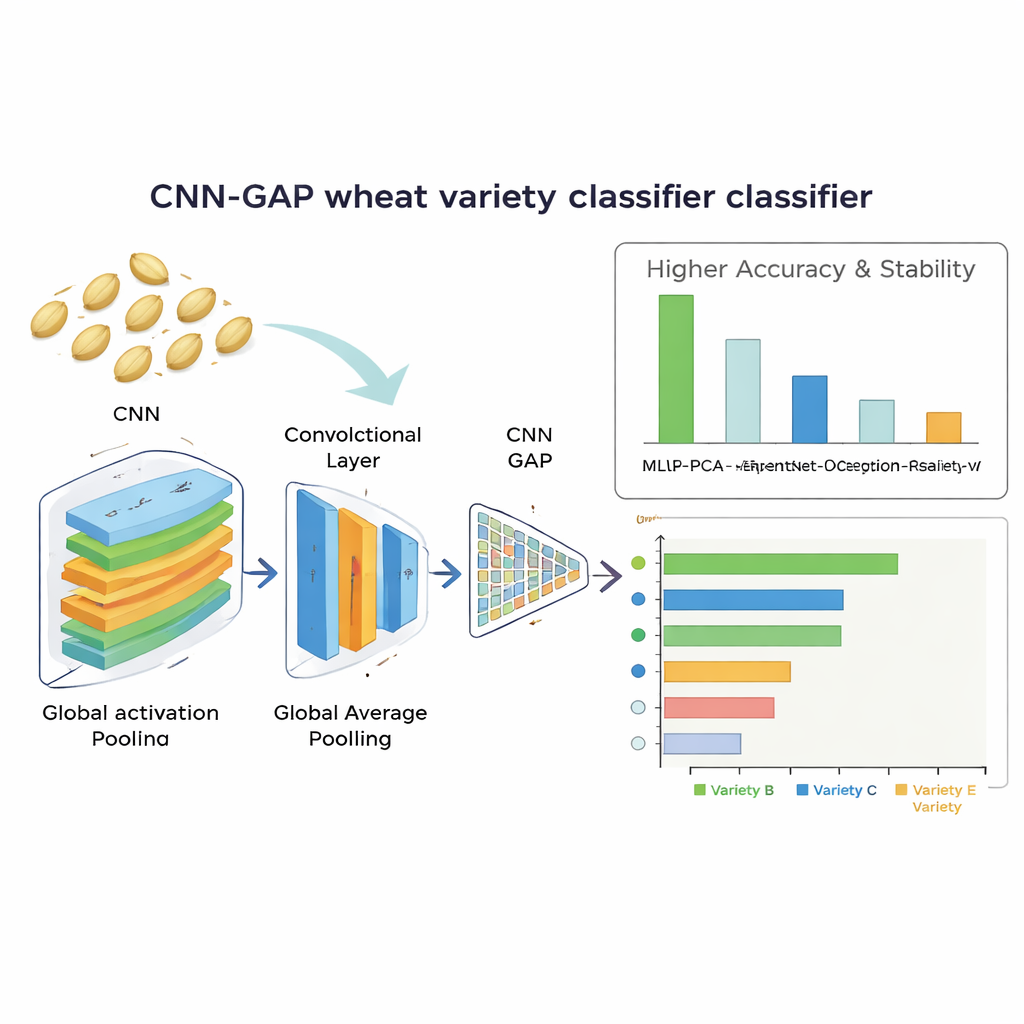
How well the system reads the grain
The best performer was the custom-built convolutional network using global average pooling. It correctly identified wheat varieties about 92% of the time and showed very stable results across repeated training runs. This model not only outperformed the large pre-trained networks but also beat the handcrafted-feature approach, which reached about 86% accuracy after dimensionality reduction. The analysis of confusion patterns showed that the lighter model did a particularly good job separating varieties that looked very similar, while the deeper transfer-learning models tended to overfit the limited dataset. Importantly, the winning network was efficient: it processed each seed image in roughly 13.6 milliseconds and contained only about 2.1 million adjustable parameters, making it realistic for use in low-cost, real-time sorting equipment.
Limits, real-world use, and what’s next
When the same model was tested on an entirely different crop—chickpea seeds—its accuracy dropped sharply, revealing that a system tuned to fine differences among wheat kernels does not automatically generalize to other species. Likewise, because all training images came from a carefully controlled chamber, performance may decline under variable field lighting or with partially hidden grains. Even so, the work shows that a compact, well-designed deep-learning model, fed with standardized single-seed images, can reliably distinguish wheat varieties that are nearly indistinguishable by eye. With broader training data and more varied imaging conditions, similar systems could become practical tools for automated seed certification, helping farmers secure purer seed lots and more predictable harvests.
Citation: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Keywords: wheat seeds, deep learning, image-based classification, seed quality, precision agriculture