Clear Sky Science · en
Primacy of feature engineering over architectural complexity for intermittent demand forecasting
Why predicting rare sales matters
Behind every car repair shop or parts warehouse sits a quiet puzzle: how many slow-moving spare parts should be kept on the shelf? These items sell rarely and unpredictably, yet must be available when a vehicle breaks down. Over-order and money is tied up in dusty stock; under-order and customers wait while parts are rushed in. This article tackles that everyday but costly problem by asking a simple question: is it better to use ever more complicated prediction models, or to feed existing models with smarter, carefully designed signals from the data?
From long stretches of nothing to sudden spikes
In many supply chains, especially for automotive spare parts, demand is not steady like milk or bread. Instead, there are long stretches of months with zero sales, interrupted by sudden orders of a few units. The authors analyze more than 56,000 dealer–part combinations, spanning about 1.4 million monthly records, and find that most series are extremely sparse: on average, there are many zero months for each month with a sale, and the size of orders swings wildly. Traditional statistical methods such as Croston’s approach and its refinements were built for this kind of “on–off” demand and give stable, interpretable forecasts, but they treat each part in isolation and cannot easily use extra information like prices or product attributes. Modern machine-learning systems can, in principle, use all this information, but they tend to struggle when the data is mostly zeros and only occasionally informative.
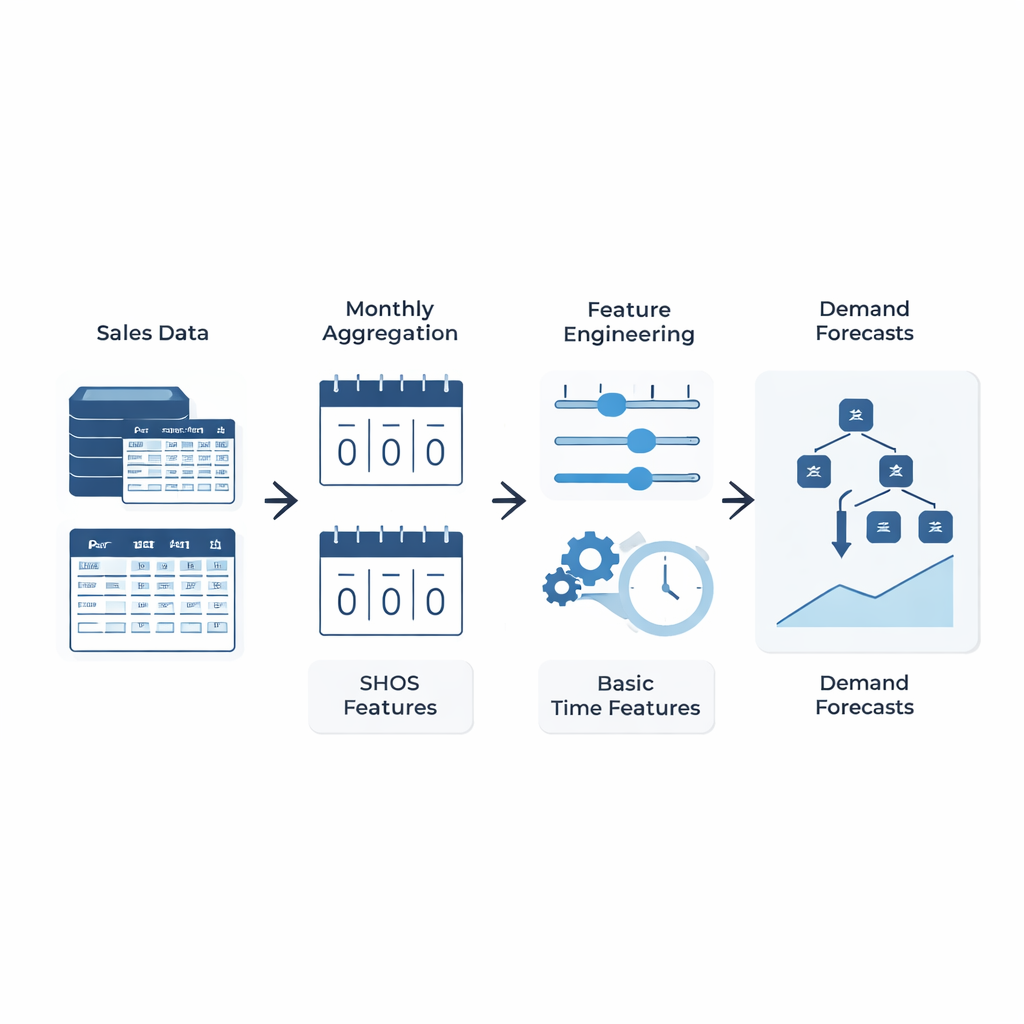
A simple idea: teach the model what really matters
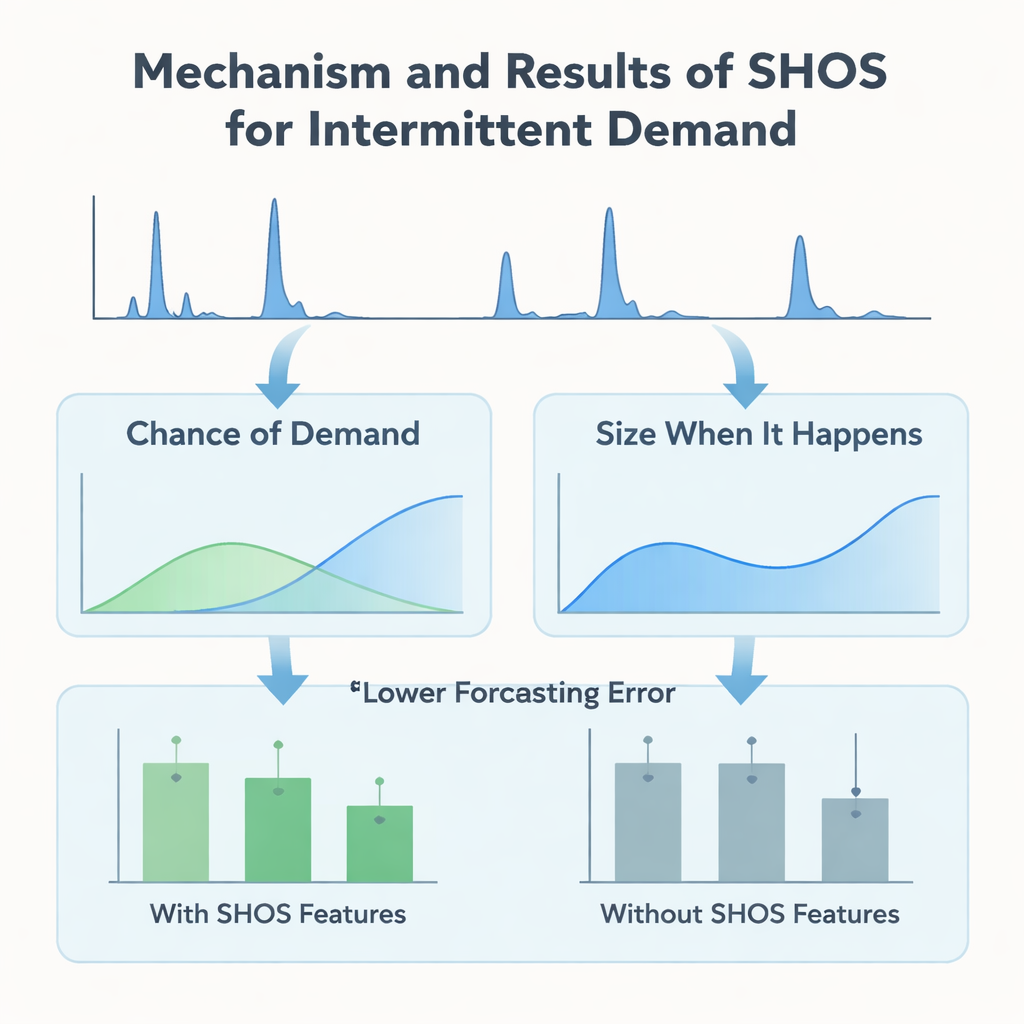
Instead of designing ever more intricate machine-learning architectures, the authors focus on what is fed into the model. They introduce the Smoothed Hybrid Occurrence–Size (SHOS) framework, a lightweight statistical routine that runs over each demand history. At every month, SHOS produces two numbers: the estimated chance that any demand will occur next month, and the typical size of that demand if it does. It does this by carefully smoothing past zeros and non-zeros, adapting its behavior for very sparse series, and reacting more quickly when demand suddenly returns after a long lull. Crucially, SHOS is not the final forecasting model. Its outputs become extra input features for standard machine-learning algorithms, alongside simple items like recent sales, rolling averages, and static product details.
Putting feature quality ahead of model complexity
To test whether this statistical “pre-processing” really helps, the researchers build a controlled experiment. They compare a range of popular models—gradient-boosted trees, random forests, and linear methods—with and without SHOS features, all trained on the same zero-filled monthly panel and evaluated using a rigorous rolling-window scheme that mimics real deployment. They also test more elaborate two-stage “hurdle” models that separately predict whether demand will occur and how big it will be. Across 11 validation windows, adding SHOS features almost halves the average forecasting error for highly intermittent items and lowers a key business metric, weighted mean absolute percentage error, by over 40%. Surprisingly, the two-stage architectures, despite being more complex and tailored to this kind of data, do not outperform a single, straightforward regressor that simply ingests the SHOS signals.
Seeing how the model makes its choices
The team goes beyond headline accuracy and probes how the models actually use the information they are given. Using SHAP, a standard tool for interpreting machine-learning predictions, they show that the SHOS-based features—“chance of demand” and “size when it happens”—consistently rank among the most influential inputs. During long zero-demand periods, a low SHOS probability pushes forecasts towards zero, preventing spurious stock build-up. When a burst of demand appears after a dry spell, a recency adjustment in SHOS quickly raises the probability and size estimates, allowing the model to respond without overreacting to a single spike. These behaviors are seen both in the simple single-stage model and in the more complex hurdle versions, underscoring that the main gain comes from the quality of the signals, not from architectural tricks.
What this means for everyday inventory decisions
For practitioners trying to keep the right parts on the shelf, the message is both practical and reassuring. The study shows that carefully designed, statistically grounded features can deliver large improvements in forecasting rare, irregular sales without resorting to fragile, hard-to-maintain model setups. A modest, well-tuned gradient-boosted tree equipped with SHOS features beats or matches more elaborate pipelines while remaining easier to deploy and monitor across tens of thousands of items. In plain terms, feeding your forecasting system better summaries of how often and how much customers are likely to order can matter more than upgrading to the latest, most complex algorithm. This emphasis on simple, interpretable building blocks makes the approach attractive for large-scale, real-world supply chains and suggests that similar feature-centered strategies could pay off in other industries facing intermittent demand.
Citation: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Keywords: intermittent demand, spare parts forecasting, feature engineering, supply chain analytics, machine learning